

背景:对于一个要看海贼王的海迷来说,每周更新的海贼王是必不可少的下饭菜,但正规渠道的高清资源爱奇艺需要充值会员...只为了一个月看4次海贼王就充值一个月会员实属让我不爽~ 无意中发现一个宝藏网站:wujicloud.cn,刚好有我需要的海贼王,而且有最新集!!!支持在线观看,但看到1039集发现视频总是加载不出来,但点击进度条又能加载个2秒,无法顺畅播放!于是我就尝试了以下几种办法去下载视频。 方式1、利用网页扩展软件CocoCut:直接报错,下载不了。(原因在后面)
教程:搜索‘cococut使用教学’ 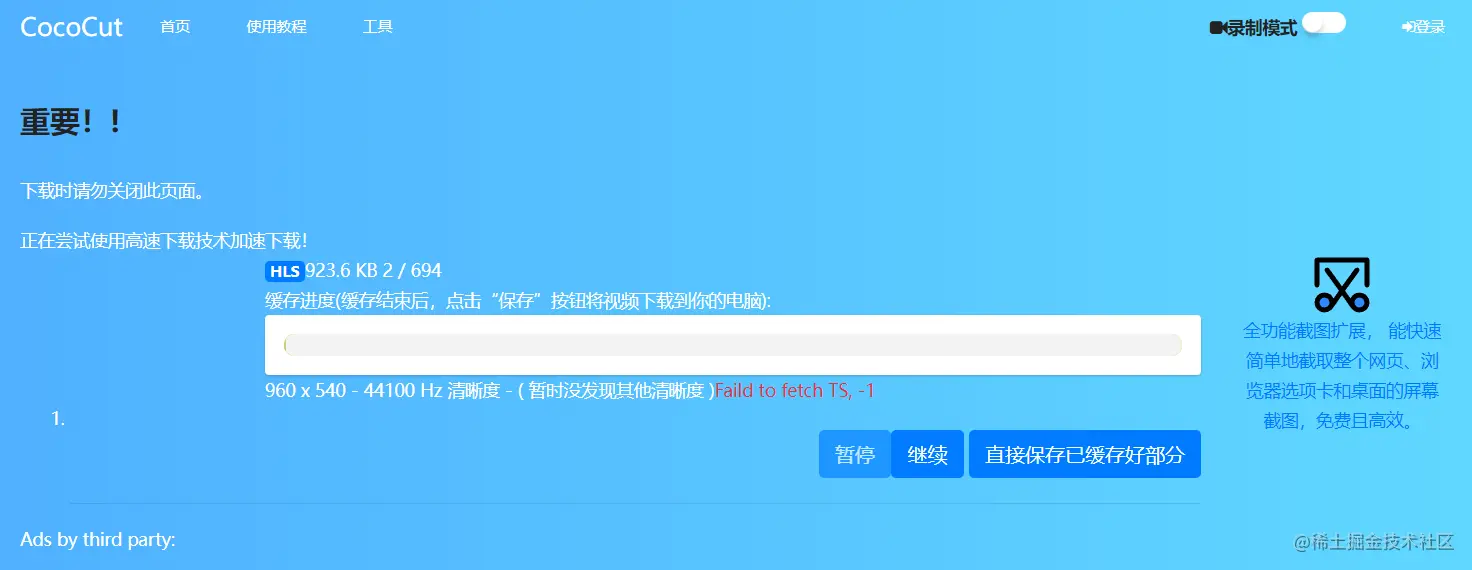
 编辑 方式2、利用m3u8下载器N_m3u8DL-CLI-SimpleG:打开网页“检查”找到了m3u8文件(如果不知可以先去百度搜索),将m3u8网址复制到下载器中,无果!会出现卡顿在某个ts片段就运行不了了,如下图卡在第574个ts文件就下载不了了,重试也无用!
编辑 方式2、利用m3u8下载器N_m3u8DL-CLI-SimpleG:打开网页“检查”找到了m3u8文件(如果不知可以先去百度搜索),将m3u8网址复制到下载器中,无果!会出现卡顿在某个ts片段就运行不了了,如下图卡在第574个ts文件就下载不了了,重试也无用!
附上m3u8下载器教程:bilibili搜索‘m3u8下载器’
编辑
编辑
发现问题:仔细查看了下载的m3u8文件(如下图所示),发现里面是png后缀的ts文件,不是以.ts结尾的!所以会导致以上两个方式无法下载视频。
编辑
附上下位博主的解决办法:可以借鉴参考一下合适自己的办法
作者:hkwJsxl
出处:m3u8文件后缀jpg,png等处理方法及视频合并 - hkwJsxl - 博客园
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
转载请注明原处
方式3、利用python自己编程下载....(入门的小白建议直接复制粘贴,修改m3u8的url即可)
有了上面处理后的ts文件后就可以直接用request获取啦~
代码如下:
# Haul Lee 写于2022年12月4日 星期日
import os.path
from multiprocessing import Pool
import requests
def main():
if not os.path.exists('./海贼王1043'):
os.mkdir('./海贼王1043')
# m3u8文件(可以直接通过网页扩展软件直接获取)
# 若要验证是否正确,直接复制到网址会下载一个m3u8文件,把文件格式修改成txt查看是否是ts文件
url = 'https://new.qqaku.com/20221204/1fwR9x4p/1100kb/hls/playlist_up.m3u8'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
'AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35'}
url_ts_list = get_ts(url, header)
pool = Pool(10) # 10个进程足以了,1分钟内即可搞定,亲测30多秒
pool.map(get_video_data, url_ts_list) # 使用线程池对视频数据进行请求(主要用于处理较为耗时的阻塞操作)
pool.close() # 关闭进程池,不再接受新的进程
pool.join() # 主进程阻塞等待子进程的退出
def get_ts(url, header):
data = requests.get(url=url, headers=header).content
with open('./未处理的m3u8文件', 'wb') as fp:
fp.write(data)
url_ts_list = [] # 创建一个空列表用于装取ts文件的url
i = 1
# 处理m3u8文件,提取有用的ts文件url
with open('未处理的m3u8文件', 'r', encoding='utf-8') as rf:
for url_ts in rf: # 获取文件的每一行
url_ts = url_ts.strip() # 去除文件中的空格、空白、换行
if url_ts.startswith('#'): # 如果以#开头,不要获取,直接下行
continue # 继续跳转for取url_ts
# 将ts文件的url和name进行封装成字典
dic_ts = {
'video_name': f'{i}.ts',
'video_url': url_ts
}
url_ts_list.append(dic_ts) # 将ts文件字典加到列表中存储
i += 1
return url_ts_list # 将值返回给main()
def get_video_data(dic_ts): # 下载ts文件
url = dic_ts['video_url'] # 读取ts文件中的每一个url
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
'AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35'}
data = requests.get(url=url, headers=header).content
with open(f'./海贼王1043/' + dic_ts['video_name'], 'wb') as wf:
wf.write(data)
print(dic_ts['video_name'], '下载完成!')
def resolve_ts(src_path, dst_path): # 将ts文件中的伪png转换成真实的ts文件
if not os.path.exists(dst_path):
os.mkdir(dst_path)
file_list = sorted(os.listdir(src_path), key=lambda x: int(x.split('.')[0]))
for i in file_list:
origin_ts = os.path.join(src_path, i)
resolved_ts = os.path.join(dst_path, i)
try:
infile = open(origin_ts, "rb") # 打开文件
outfile = open(resolved_ts, "wb") # 内容输出
data = infile.read()
outfile.write(data)
outfile.seek(0x00)
outfile.write(b'\xff\xff\xff\xff')
outfile.flush()
infile.close() # 文件关闭
outfile.close()
except:
pass
print('resolve ' + origin_ts + ' success')
def merge_ts_video(ts_path, mp4_path): # 合并ts文件
all_ts = os.listdir(ts_path)
all_ts.sort(key=lambda x: int(x[:-3]))
with open(mp4_path, 'wb+') as f:
for i in range(len(all_ts)):
ts_video_path = os.path.join(ts_path, all_ts[i])
f.write(open(ts_video_path, 'rb').read())
print("视频合并完成!!!")
if __name__ == '__main__':
main()
src_path = 'D:/pythonProject/pythonProject/海贼王1043' # 伪png的ts文件存储路径
dst_path = 'D:/pythonProject/pythonProject/海贼王1043-ts' # 去除伪png头的ts文件存储路径
resolve_ts(src_path, dst_path)
merge_ts_video(dst_path, './海贼王1043.mp4') # 真实ts文件存储路径 和 合并后视频的输出路径
总结:写代码就是在不断发生问题解决问题,看似简单的一个想法,过程中会遇到意想不到的问题,能发现问题就已经很不错了~如果最后能解决问题,那成就感满满的,这是我这初世小白的第一篇文章,刚学python2个月不到...如有更好的方式欢迎私信。
