

预备知识
零.
以下内容都是在虚拟内存的基础上,本来对malloc来说物理内存就是透明的
一.linux虚拟内存管理
概念:虚拟内存就是在虚拟存储器上的地址索引,而虚拟存储器借csapp的话是被组织为一个存放在磁盘上的N个连续的字节大小的数组。
虚拟地址器提供了一个机制(虚拟地址到物理地址的映射),让内存的地址空间大大增加,简单的说就是每一个进程一个存储器映像。(而虚拟地址到物理地址的映射借助了页表,这些分页,地址翻译的知识我就准备跳过了,因为这些对于malloc来说都是透明的,需要了解的可以去看csapp)
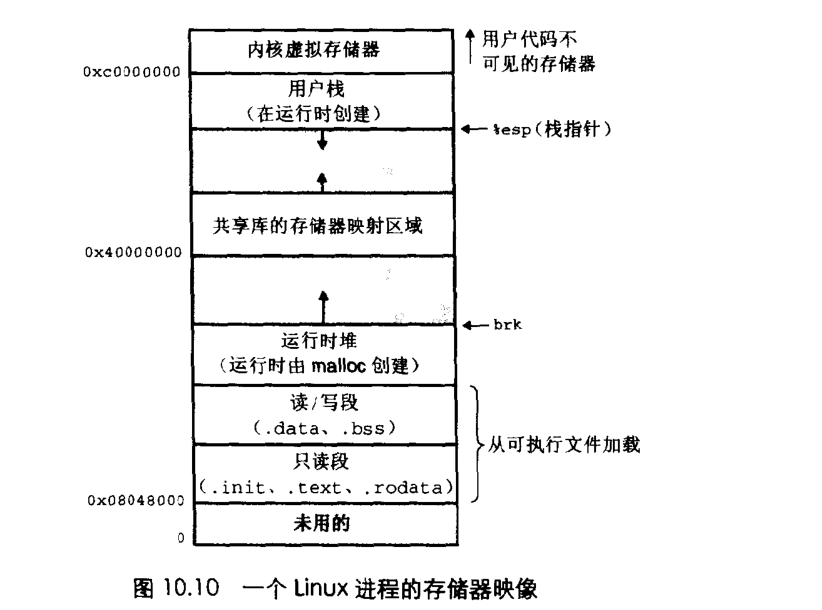
(图来源于csapp原书)
那这个在代码上是怎么实现的呢?
首先我们要知道一件事,就是上文存储器映像中的段还有一个名字加vma(virtual memory area),有一个结构vm_area_struct来描述它。
在linux中用一种加task_struct的结果来描述进程,而task_struct中有一项mm来描述内存。
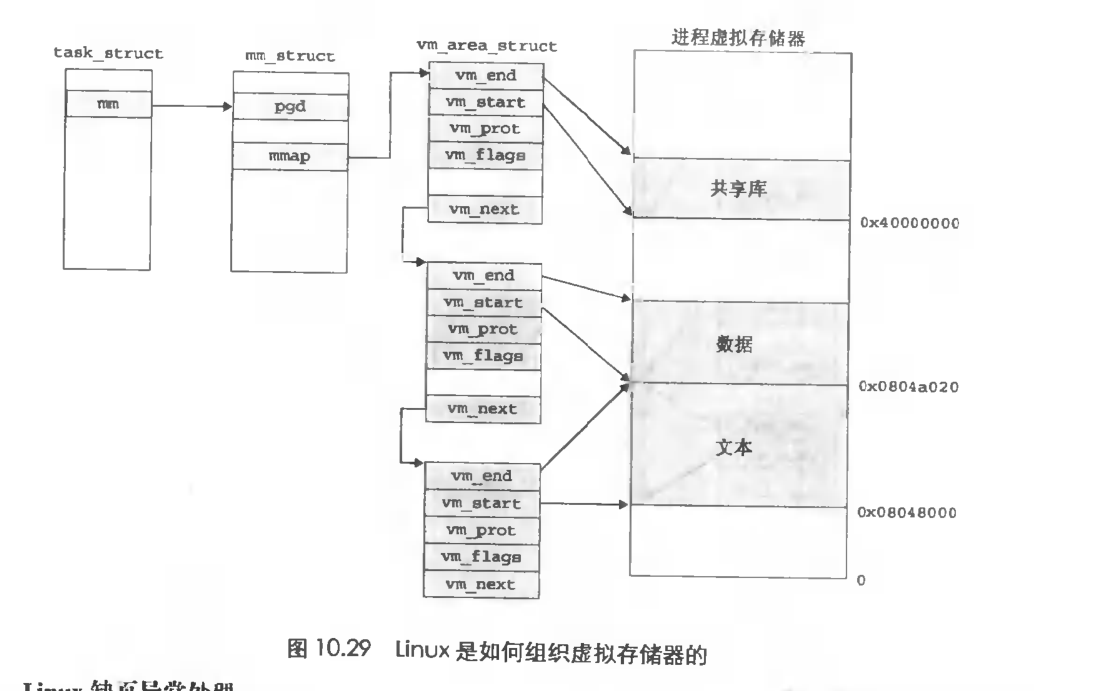
(图来源于csapp原书)
区域被初始化后,os就会进行存储器映射
二.存储器映射
什么是存储器映射?存储器映射就是把vma与一个磁盘对象关联起来。一般来说存储器可以映射到普通文件和匿名文件(bss区域映射到匿名文件的)
事实上每一个vma被映射过后(或者说初始化后)就要装入swap分区,所以swap空间制约着正在运行的进程所能分配的虚拟页面的数量。
现在磁盘上的对象分为了两类:共享对象和私有对象。
每个进程都包含一些公有的东西比如lib库,如果每个进程放一份在内存中不就浪费了吗,所以就有了共享对象,让它映射到不同的进程中。对了大家都知道进程间通信可以通过shared memory来实现,也是共享对象的功劳。
(图来源于csapp原书)
还有私有对象,不过它也有自己的秘诀来减小开销,那就是copy-on-write(写时拷贝)。
所谓写时拷贝就是在进程没有写的需求时,进程二与进程一共享,知道有一个进程要开始写时再分配,那么新分配的内存对原进程不可见
(图来源于csapp原书)
我们的fork就用了这项技术,在父进程创建子进程时就如同上图的开始时,子进程共享父进程的内存,直到父进程或子进程开始写时,copy-on-write再开始创建新页面,因此每个进程就有了私有地址空间。那execve又干了什么?总体上干了四件事
1.删除已经存在的用户结构
2.映射私有area
2.映射共享area
4.设置pc,开始执行代码
另外说一句,所谓load并不是直接把文件放在内存里,而是完成映射后,再进程被调度时,os会发出page fault来换入代码和数据页面
三.mmap函数进行用户级存储器映射
unix进程可以使用mmap函数来创建新的vma并将对象映射过来
void *mmap(void * start,size_t lenth,int prot,int flags,int fd,off_t offset);
prot代表权限比如可写和可读
flag代表时共享还是私有
(图来源于csapp原书)
动态存储器分配
虽然有mmap函数,但是c语言再运行时还是需要动态存储器分配的。动态存储器分配就是维护着heap
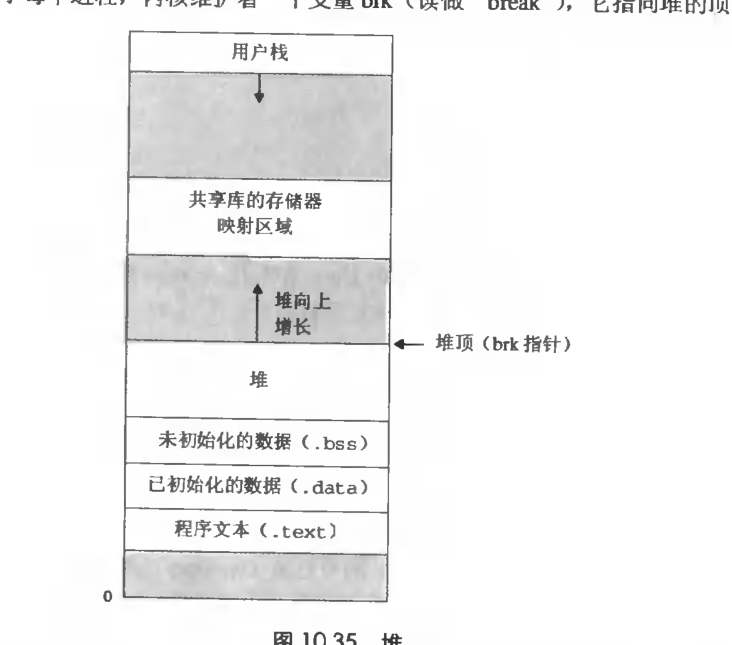
而分配器将heap视为一组不同大小的block数组。
一般分配器分为两个风格:显示分配器,隐式分配器
显示分配器(本文把malloc等同于显示分配器)
隐式分配器(垃圾收集器)不在本文讨论中
显示分配器的实现要点(malloc)
前面说了这么多,终于到了malloc。不过malloc也有不同的实现方式,而区别他们的正是上文说的block的结构和组织方式。
malloc实现要点:
1.将heap中的空闲块组织成freelist
2.malloc 在freelist中找寻空闲块(如果没有,就调用sbrk函数分配),而在block链中查找合适的block有很多算法一般来说有first-fit和best-fit,分配后怎么做split的问题
3.在free时要注意块的合并
4.freelist的实现:隐式空闲链表,显示空闲双向链表,分离存储,红黑树。

来源(27-dynamic-mem1.pptx (williams.edu))
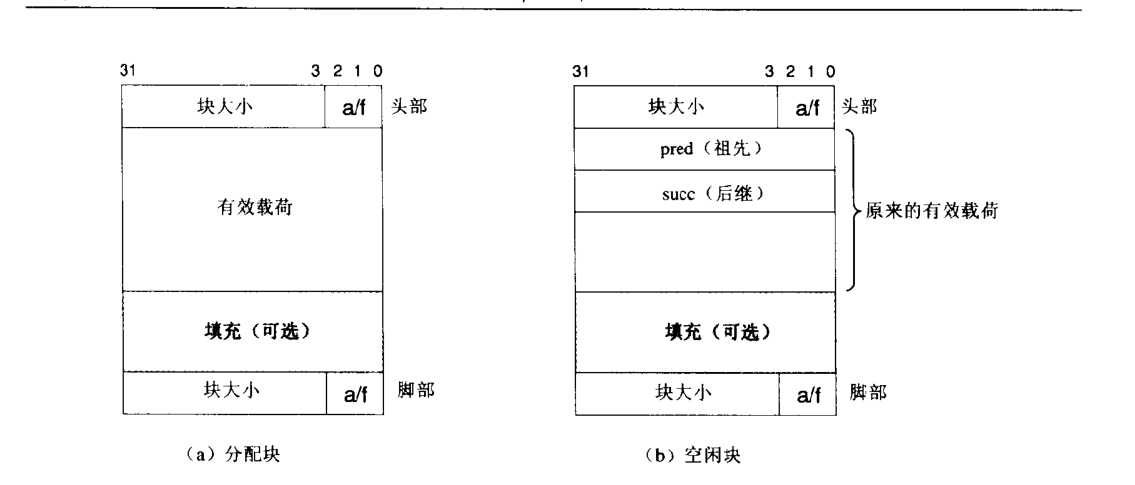
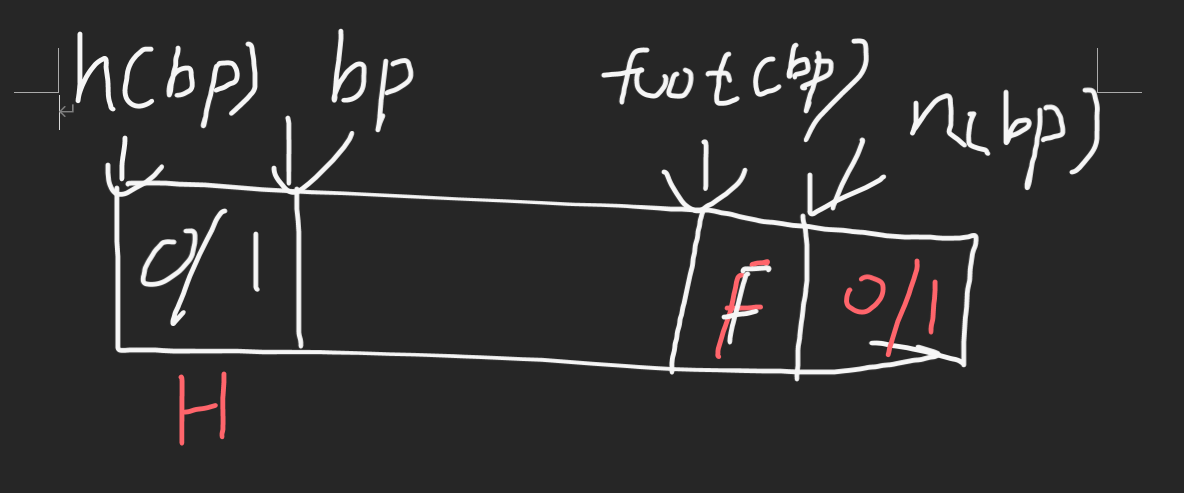
freelist实现的不同也意味着block的不同,但一般来说block分为meta-data(data control block)和payload(看不懂可以看下面的block图)
隐式空闲链表block管理要点
接下来讲隐式空闲链表的block
meta中存放着大小和分配情况,因为大小是以8bit对齐的,所以后面三位永远是000,所以用00a表示分配情况,a为0表空闲,相反a为1表已分配。padding是因为整个block是要以8bit对齐的,所以如果payload没有满8bit就需要padding,使得整个block以8bit对齐
整个例子:
函数
分配的block(要记得上文说的block的结构)
确定好大小后 block
上面这个例子我们只malloc(6),却整出来16。而每次我们malloc返回的指针是指向我们的payload的,那我们怎么得到block的地址呢?其实也很简单
void *p = malloc(4);
uint64_t block_start = ((uint64_t)p -4); //为什么是4?因为meta区大小是32bit 就是4byte
uint32_t block_header_value = *((uint64_t*)block_start;
uint32_t block_size = block_start & 0xfffffffe;
int alloc = block_start & 0x1;
uint64_t next_block_start = block_start + block_size;
mallo实现
malloc原理
隐式空闲链表Implicit Free List
这就是隐式空闲链表,利用数组来管理freelist
uint64_t heap_start_addr;
void * malloc(uint32_t size)
{
uint64_t p = heap_start_addr;
while (1)
{
uint32_t p_block_value = *((uint64_t*)p);
uint32_t p_block_alocated = p_block_value & 0x1;
uint32_t p_block_size = p_block_value & 0xfffffffe;
uint32_t p_block_alocated_payload_size = p_block_size -4;
if (p_block_alocated == 0 && p_block_alocated_payload_size >= size)
{
uint32_t request_block_size = 4 + size;
if (request_block_size & 0x7 != 0)
{
request_block_size = request_block_size & 0xfffffffe + 0x8;
}
uint64_t split_block_addr = p + request_block_size;
uint32_t split_block_value = *(uint64_t*)split_block_addr;
split_block_value = p_block_size - request_block_size;
p_block_value = request_block_size;
p_block_value &= 0x1;
return (void*)(p+4);
}
else
{
p += p_block_size;
}
}
}
地址用uint64_t ,数用uint_32_t
还有在freelist后有一个大小为0已分配的终止头部(已分配是为了后面不考虑块的合并)
但是现在malloc的实现有问题就是我们现在无法实现free最大化。我们现在只能合并后一块,这是与block的结构决定的
那我们怎么解决呢?这是Knuth(Donald Knuth - Wikipedia)提出了一个聪明又通用的方法叫边界标记。基于这种思想我们决定在block的最后添加一个脚部
这样我们就可以通过脚部得到分配情况(前一块和后一块的分配情况)
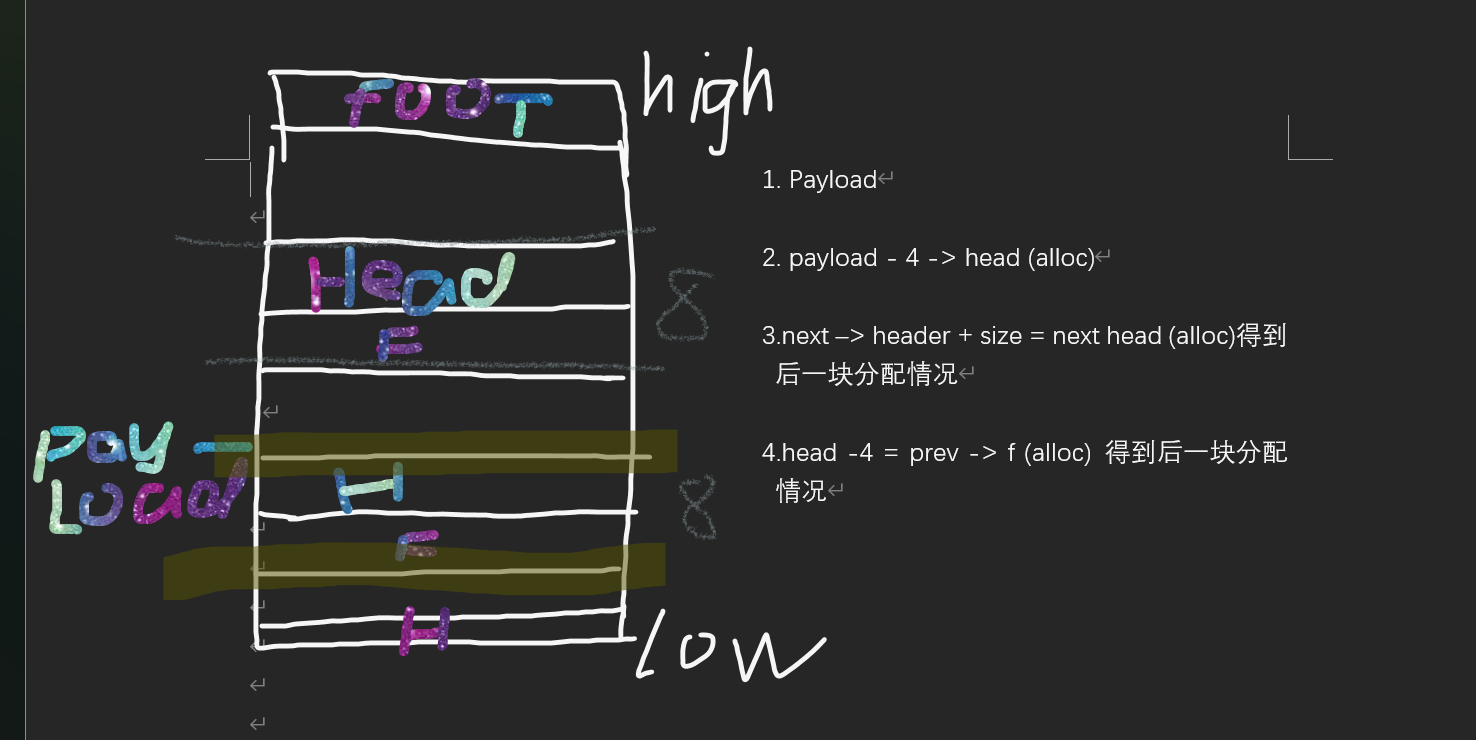
也因为有了脚部所以对齐的时候payload 大小要是8的倍数,因为头部和脚部同时出现并且大小加起来刚好是8。
在写malloc函数之前可以写一些辅助函数,如获取大小,分配情况(因为在malloc和free中都要用到)
// Round up to next multiple of n:
// if (x == k * n)
// return x
// else, x = k * n + m and m < n
// return (k + 1) * n
static uint64_t round_up(uint64_t x, uint64_t n)
{
return n * ((x + n - 1) / n);
} //round_up返回的地址是指向payload的
static uint32_t getblocksize(uint64_t header){
assert(0 < header < heapsize -4);
uint32_t head_value = *((uint32_t *)header);
return head_value&0xfffffff8;
}
static void set_blocksize(uint64_t header_vaddr, uint32_t blocksize){
*(uint32_t*)header_vaddr &= 0x7;
*(uint32_t*)header_vaddr |= blocksize;
}
static uint32_t get_allocated(uint64_t header){
assert(0 < header < heapsize -4);
uint32_t head_value = *((uint32_t *)header);
return head_value&0x1;
}
static void set_allocated(uint64_t header_vaddr, uint32_t allocated){
*(uint32_t*)header_vaddr &= 0xfffffff8;
*(uint32_t*)header_vaddr |= allocated;
}
static uint64_t get_payload(uint64_t vaddr)
{
// vaddr can be:
// 1. starting address of the block (8 * n + 4)
// 2. starting address of the payload (8 * m)
return round_up(vaddr, 8);
}
static uint64_t get_blockheader(uint64_t vadder){
return round_up(vaddr,8) - 4;
}
static uint64_t get_nextheader(uint64_t vaddr){
uint64_t header_addr = get_blockheader(vaddr);
uint32_t block_size = get_blocksize(header_addr);
return header_addr + block_size;
}
static uint64_t get_prevheader(uint64_t vaddr){
uint64_t header_addr = get_blockheader(vaddr);
uint64_t prev_footer_addr = header_addr -4;
uint32_t prev_block_size = get_blocksize(prev_footer_addr);
return header_addr - prev_block_size;
}
malloc与free的实现(firs-fit)
malloc与上面的做法倒是没什么不同,只是用了包装的函数,因为新加的foot只是为了free最大化加的。
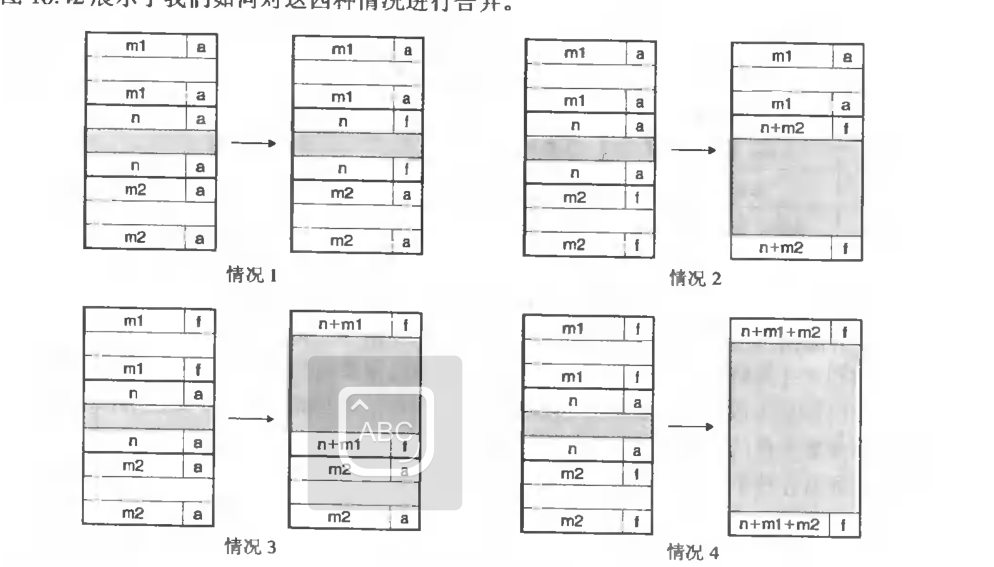
而free总体上分为4种情况
uint64_t mem_malloc(uint32_t size){
assert(0 < size < 4096 - 8);
uint32_t request_block_size = round_up(size,8) + 4 + 4;
uint64_t b = heap_start_addr;
while(b <= heap_end_adder){
uint32_t b_blocksize = get_blocksize(b);
uint32_t b_blockallocated = get_allocated(b);
if(b_blockallocated == 0&& b_blocksize >= request_block_size){
//fit
if(b_blocksize > request_block_size){
//need split
set_allocated(b,1);
set_blocksize(b,request_block_size);
uint64_t split_block_addr = b + request_block_size;
set_allocated(split_block_addr,0);
set_blocksize(split_block_addr,request_block_size);
return get_payload(b);
}
else {
//no need to split
set_allocated(b,1);
return get_payload(b);
}
}
//miss
else {
b = get_nextheader(b);
}
}
return 0;
}
void mem_free(uint64_t vaddr){
assert(vaddr &0x7 == 0x0);
uint64_t req_block_addr = get_blockheader(vaddr);
uint32_t req_block_size = get_blocksize(req_block_addr);
uint32_t req_block_allocated = get_allocated(req_block_addr);
assert(req_block_allocated == 0x1);
//to konw the situation of the next block and prev block
uint64_t next_block_addr = get_nextheader(req_block_addr);
uint64_t prev_block_addr = get_prevheader(req_block_addr);
uint32_t next_block_size = get_blocksize(next_block_addr);
uint32_t prev_block_size = get_blocksize(prev_block_addr);
uint32_t next_block_allocated = get_allocated(next_block_addr);
uint32_t prev_block_allocated = get_allocated(prev_block_addr);
//four situation for free
if(next_block_allocated == 1 && prev_block_allocated == 1){
set_allocated(req_block_addr,0);
}
else if(next_block_allocated == 0 && prev_block_allocated == 1){
set_allocated(req_block_addr,0);
set_blocksize(req_block_addr,req_block_size+next_block_size);
}
else if(next_block_allocated == 1 && prev_block_allocated == 0){
set_allocated(prev_block_addr,0);
set_blocksize(prev_block_addr,prev_block_size+req_block_size);
}
else if(next_block_allocated == 0 && prev_block_allocated == 0){
set_allocated(prev,0);
set_blocksize(prev_block_addr,prev_block_size+req_block_size+next_block_size);
}
}
但是我们在这里乱写也不知道对错,所以我们还要借助malloc lab这个实验。实际上这些代码也只是写一个感觉(其实在我们上面写的malloc中少了一步就是如果在freelist中找不到就要extend_heap,因为这个我不能乱写,其实主要也是不会写,所以我干脆就不写了。还有比如一个block经过split后剩下的block放不下meta区怎么办?按理说是不分割,可是上面的代码没有)
另外在我们现在实现的malloc效率是比较低的,尽管free是o(1),但是malloc是要搜索所有的block是一个o(n)
那我们第一次优化就是让freelist成为一个真正的freelist(因为在之前我们都是把block 数组当初freelist难免有些名不副实),就是malloc遍历时只遍历free的block,就是在所有的block数组中另外有一个freeblock组成的freelist,这样效率能提高100%,因为一个free block周围肯定有一个allocated block(根据free最大原则)
显式空闲链表Explicit Free List
显式空闲链表block,分为free block 和allocated block
我们对block的排序总体上有两种,一是按照LILO的原则,二时按照地址大小,比如从大到小。
我是选择FIFO。
(27-dynamic-mem1.pptx (williams.edu))这个ppt写的很完全了
分离链表(Segregated Free Lists)
还有一种Segregated Free Lists(分离链表):在系统中维持多个空闲链表,每个空闲链表内放置某个大小返回内的空闲块
malloc实现(malloc lab)
malloc lab本身
1.获取: CS:APP3e, Bryant and O'Hallaron (cmu.edu)往下翻找到malloc lab,然后点击self-study handout 下载下来解压就行
然后根据writeup写的 Use the command make to generate the driver code and run it with the command ./mdriver -V.
2.解压后make 发现出错
错误原因:系统中的gcc没有安装multilib 库;使用这个库可以在64位的机器上产生32位的程序
解决方法:sudo apt-get install gcc-multilib
3.打开后实现少了trace就是测试文件 可以通过这个链接(CSAPP-Labs/yzf-malloclab-handout at master · Ethan-Yan27/CSAPP-Labs (github.com))下载 (clone) 把trace文件放到自己的malloc lab里
然后在config.h中 把tracedir改成这样
运行 **./mdriver -V**测试一下
要做什么?writeup已经写了
How to Work on the Lab :
Your dynamic storage allocator will consist of the following four functions, which are declared in mm.h and defined in mm.c.
int mm_init(void);
void *mm_malloc(size_t size);
void mm_free(void *ptr);
void *mm_realloc(void *ptr, size_t size);
就是完成这mm.c中的这4个函数,然后运行/mdriver -V测试成绩
还有一些关于heap的辅助函数(位于memlib.c)就是维护三个变量和一些函数
static char *mem_start_brk; /* points to first byte of heap */
static char *mem_brk; /* points to last byte of heap */
static char *mem_max_addr; /* largest legal heap address */
void mem_init(void); //初始化 heap
void mem_deinit(void); //将整个heap置为free
void *mem_sbrk(int incr); //相当于sbrk 返回old mem_brk
void mem_reset_brk(void); //reset *mem_brk指针
void *mem_heap_lo(void); //return (void*)*mem_start_brk heap起始地址
void *mem_heap_hi(void); //return (void*)*mem_brk - 1 heap现在地址
size_t mem_heapsize(void); //返回mem_brk - mem_start_brk
size_t mem_pagesize(void); //return the page size of system
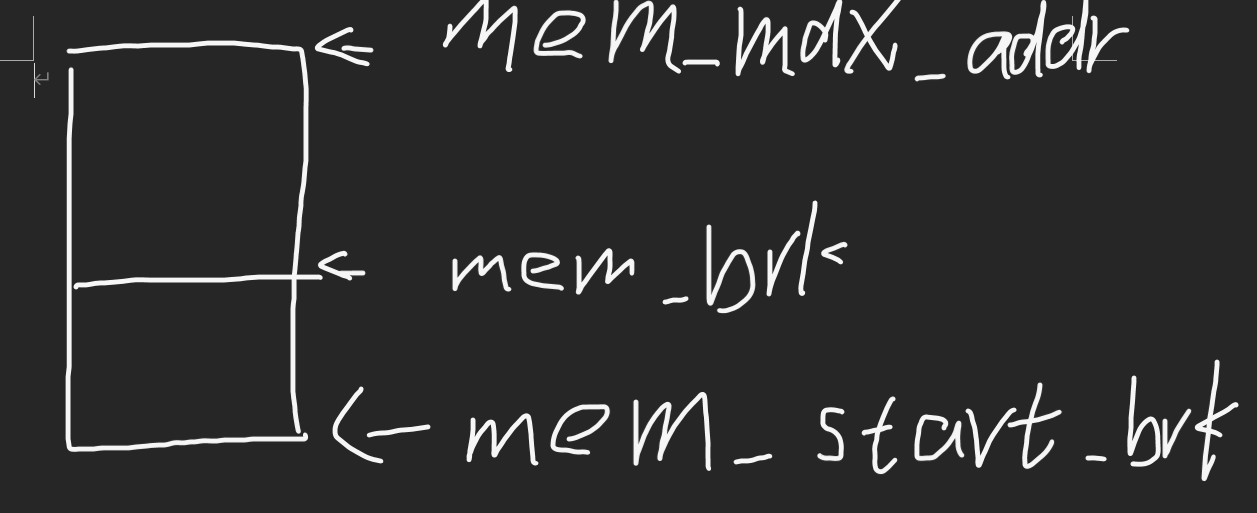
另外上面乱写的代码虽然不是完全对的,但是改一下参数还是可以拿来用的
在csapp原书中在mm,c中开头有一些宏来辅助,其实他们和我们写的函数没什么不同,就是把函数变成宏而已
还有malloc lab中地址是用unsigned int * ,我是用uint64_t*
宏
/* 头部/脚部的大小 */
#define WSIZE 4
/* 双字 */
#define DSIZE 8
/* 扩展堆时的默认大小 */
#define CHUNKSIZE (1 << 12)
#define GET(p) (*(unsigned int *)(p)) //get_blockvalue
#define PUT(p, val) ((*(unsigned int *)(p)) = (val)) //set_blockvalue
#define PACK(size, alloc) ((size) | (alloc)) //相当于把我们的set_blocksize和set_allocated合在一起
#define GET_SIZE(p) (GET(p) & ~0x7) //get_blocksize
#define GET_ALLOC(p) (GET(p) & 0x1) //get_allocated
#define HDRP(bp) ((char*)(bp) - WSIZE) //get_blockheader
#define FTRP(bp) ((char *)(bp)+GET_SIZE(HDRP(bp))-DSIZE)
#define NEXT_BLKP(bp) ((char*)(bp) + GET_SIZE(((char*)(bp) - WSIZE))) //get_nextheader
#define PREV_BLKP(bp) ((char*)(bp) - GET_SIZE(((char*)(bp) - DSIZE))) //get_prevheader
隐式空闲链表+first-fit
init
首先说隐式空闲链表书上实现的了,也就是说代码书上是有的,我们现在是做一个相当于代码完成注释的事情
初始化就是构建出Implicit Free List,而Implicit Free List要求如图

序言块前面是一个双字边界对齐的不使用的填充字,序言块是一个8字节的已分配块,包括header和footer,然后heap总是以一个结尾块结尾,这个结尾块是一个大小为0的分配块只有
所以初始化时我们要构建出这三个特殊块
if((heap_list = mem_sbrk(4*WSIZE)) == (void *)-1)
return -1;
PUT(heap_list, 0);
/*
* 序言块和结尾块均设置为已分配, 方便考虑边界情况
*/
PUT(heap_list + (1*WSIZE), PACK(DSIZE, 1)); /* 填充序言块 */
PUT(heap_list + (2*WSIZE), PACK(DSIZE, 1)); /* 填充序言块 */
PUT(heap_list + (3*WSIZE), PACK(0, 1)); /* 结尾块 */
完成后,现在我们的表有了这四个块,不过显而易见的是不够,所以我们还要对这个表做extend,借助一个叫extned_heap函数,扩展CHUNKSIZE大小字节,并创建空闲块,这个函数在两件事中被调用:1初始化 2.freelist中没有满足的块
所以我们现在要做两件事,一是在初始化时调用extend_heap函数,二自然是实现extend_heap函数
int mm_init(void)
{
/* 申请四个字节空间 */
if((heap_list = mem_sbrk(4*WSIZE)) == (void *)-1)
return -1;
PUT(heap_list, 0); /* 对齐 */
/*
* 序言块和结尾块均设置为已分配, 方便考虑边界情况
*/
PUT(heap_list + (1*WSIZE), PACK(DSIZE, 1)); /* 填充序言块 */
PUT(heap_list + (2*WSIZE), PACK(DSIZE, 1)); /* 填充序言块 */
PUT(heap_list + (3*WSIZE), PACK(0, 1)); /* 结尾块 */
heap_list += (2*WSIZE); //因为heap_list总是要指向序言块的第二块
/* 扩展空闲空间 */
if(extend_heap(CHUNKSIZE/WSIZE) == NULL)
return -1;
return 0;
}
extend_heap函数有它实现上的细节,它分配出一个块接在原来的heap上,将原来的结尾块(其实它本身就是一个header)作为新的块的header,然后在新的块上分出一个结尾块,所以在extend_heap函数中要调用函数进行merge。
extend_heap函数是调用mem_sbrk函数它返回的是指向payload的指针(因为它已经有头部了,就是之前的结束快)
mem_sbrk分配的块应该是与8对齐的,所以要根据奇偶来设置
static void *extend_heap(size_t words){
char *bp; ///* bp should be pointed to payload
size_t size;
size = (words%2) ? (words+1)*WSIZE : words*WSIZE; //根据奇偶对齐
if((long)(bp=mem_sbrk(size))==(void *)-1) //分配
return NULL;
PUT(HDRP(bp),PACK(size,0)); //设置header 其实就是设置old结束块,因为mem_sbrk返回old mem_brk(指向结束块)
PUT(FTRP(bp),PACK(size,0));
PUT(HDRP(NEXT_BLKP(bp)),PACK(0,1)); //set new 结束块
return coalesce(bp); //merge
}
merge(coalesce)
合并其实我们上面已经讨论过了,就是分成四种情况
和上面的代码几乎是一样的,只是用了宏而已
void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); /* 前一块大小 */
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); /* 后一块大小 */
size_t size = GET_SIZE(HDRP(bp)); /* 当前块大小 */
/* 前后都不空 */
if(prev_alloc && next_alloc){
return bp;
}
/* 前不空后空 */
else if(prev_alloc && !next_alloc){
size += GET_SIZE(HDRP(NEXT_BLKP(bp))); //增加当前块大小
PUT(HDRP(bp), PACK(size, 0)); //先修改头
PUT(FTRP(bp), PACK(size, 0)); //根据头部中的大小来定位尾部
}
/* 前空后不空 */
else if(!prev_alloc && next_alloc){
size += GET_SIZE(HDRP(PREV_BLKP(bp))); //增加当前块大小
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp); //注意指针要变
}
/* 都空 */
else{
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp))); //增加当前块大小
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}
malloc
malloc实现:
1.将fit算法抽离出来,做成函数
2.使用了上面写的round_up函数进行对齐(其实也没有)
3.在寻找合适块的时候,除了要看大小是否符合要求,还要看split过后,剩下的块能否放得下block结构(就是是否大于8-一个header+一个footer
void *mm_malloc(size_t size)
{
size_t asize;
size_t extendsize;
char *bp;
if(size == 0)
return NULL;
if(size <= DSIZE)
asize = 2*DSIZE;
else
asize = DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE);//书上代码
//round_up(size,8); 我们自己的对齐函数
/* 寻找合适的空闲块 */
if((bp = first_fit(asize)) != NULL){
place(bp, asize); //split
return bp;
}
/* 找不到则扩展堆 */
extendsize = MAX(asize, CHUNKSIZE);
if((bp = extend_heap(extendsize/WSIZE)) == NULL)
return NULL;
place(bp, asize); //split
return bp;
}
first-fit
void *first_fit(size_t asize)
{
void *bp;
for(bp = heap_list; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp)){
if((GET_SIZE(HDRP(bp)) >= asize) && (!GET_ALLOC(HDRP(bp)))){
return bp; //size符合并且没有分配
}
}
return NULL;
}
split(place)
void place(void *bp, size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp));
/* 判断是否能够分离空闲块 */
if((csize - asize) >= 2*DSIZE) { //就是看split过后,剩下的块能否放得下block结构
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(csize - asize, 0));
PUT(FTRP(bp), PACK(csize - asize, 0));
}
/*不用分割*/
else{
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}
free
书上把free 和merge代码分离了,所以free代码就没什么难度了,就是把header和footer置0
void mm_free(void *ptr)
{
if(ptr==0)
return;
size_t size = GET_SIZE(HDRP(ptr));
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
coalesce(ptr);
}
realloc
指针名=(数据类型*)realloc(要改变内存大小的指针名,新的大小)。
就照着writeup写的要就行

void *mm_realloc(void *ptr, size_t size)
{
size_t oldsize;
void *newptr;
/* If size == 0 then this is just free, and we return NULL. */
if(size == 0) {
mm_free(ptr);
return 0;
}
/* If oldptr is NULL, then this is just malloc. */
if(ptr == NULL) {
return mm_malloc(size);
}
newptr = mm_malloc(size);
/* If realloc() fails the original block is left untouched */
if(!newptr) {
return 0;
}
/* Copy the old data. */
oldsize = GET_SIZE(HDRP(ptr));
if(size < oldsize) oldsize = size;
memcpy(newptr, ptr, oldsize); //不管大小就把按最小的大小复制过来
/* Free the old block. */
mm_free(ptr); //再释放掉原来的块
return newptr;
}
结果
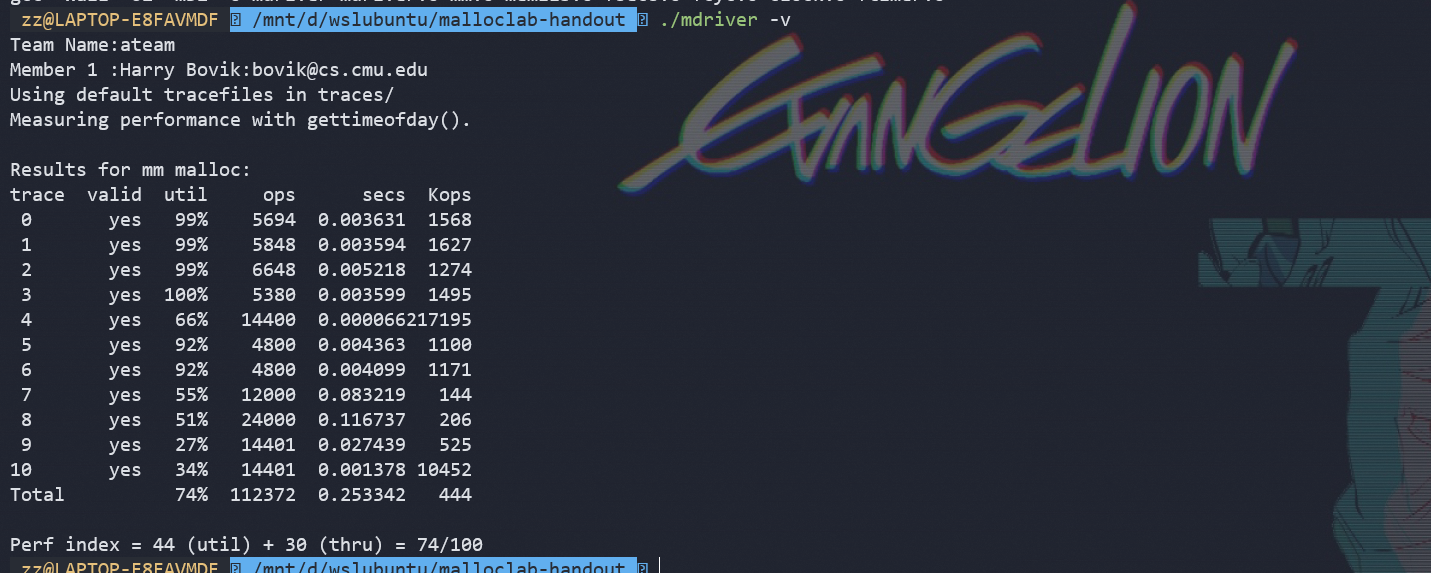
分析:
我们malloc lab与我们上面写的代码有什么不同吗?
1.malloc lab所有函数都统一参数是指向payload的指针,再通过宏进行操作。而我们的代码则利用了round_up(x,8)进行转换,就是无论是什么地址放进round函数(参数也只会有header addr 和 payload地址),出来都是指向payload的指针。为什么?
所以所有的payload区域都8对齐的,而且round只会返回指向payload的指针(因为参数只有header addr 和 payload地址)
2.其实我们上面的代码挺完善了,我们加了什么呢?
1.使用mem_sbrk实现的extend_heap,我们原来的代码就没有block的扩展和结尾块的合并
2.再split是加了检测,检测split后的block能不能放下block结构
显式空闲链表+fifo
来源:(27-dynamic-mem1.pptx (williams.edu))写的真的很好,靠这个pdf写Explicit Free List完全够了。
还有一点很重要就是就下来所以bp指针再上面是指向paypoad,在下面的函数是指向prev指针(因为prev和next在块的结构里就算在payload里面,所以其实是一样的)
宏
要加一些对链表设置的宏
#define PREV_LINKNODE_RP(bp) ((char*)(bp)) //块的prev
#define NEXT_LINKNODE_RP(bp) ((char*)(bp)+WSIZE) //块的next
init
还是与Implicit Free List一样构建Explicit Free List就行
显式相比于隐式就是block加了prev和next指针,那么显式list初始化时就要为链表服务,init出一个链表头root(有一个prev指针和next指针)
所以要sbrk6个块了,再加上对root的初始化。(可能与上面那个图不一样,但在那个pdf中关于free时都有root的出现)
int mm_init(void)
{
if((heap_listp = mem_sbrk(6*WSIZE))==(void *)-1) return -1; //知道为什么是6吗
PUT(heap_listp,0);
PUT(heap_listp+(1*WSIZE),0); //prev
PUT(heap_listp+(2*WSIZE),0); //next 换言之init root
PUT(heap_listp+(3*WSIZE),PACK(DSIZE,1)); /* 填充序言块 */
PUT(heap_listp+(4*WSIZE),PACK(DSIZE,1)); /* 填充序言块 */
PUT(heap_listp+(5*WSIZE),PACK(0,1)); /* 填充结尾块 */
root = heap_listp + (1*WSIZE); //root
heap_listp += (4*WSIZE); //因为heap_list总是要指向序言块的第二块
/* 扩展空闲空间 */
if((extend_heap(CHUNKSIZE/DSIZE))==NULL) return -1;
return 0;
}
而extend_heap函数与隐式也有两点不同 一是大小有了变化现在最小是16byte(header 4 +next 4+prev 4 +footer 4)
二是扩展后的内存多了next prev 的初始化
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
size = (words % 2) ? (words+1) * DSIZE : words * DSIZE;
if((long)(bp = mem_sbrk(size))==(void *)-1)
return NULL;
PUT(HDRP(bp),PACK(size,0)); //设置header 其实就是设置old结束块,因为mem_sbrk返回old mem_brk(指向结束块)
PUT(FTRP(bp),PACK(size,0));
PUT(NEXT_LINKNODE_RP(bp),0); //设置next
PUT(PREV_LINKNODE_RP(bp),0);
PUT(HDRP(NEXT_BLKP(bp)),PACK(0,1)); //set new 结束块
return coalesce(bp);
}
merge(coalesce)
合并就是分成四种情况
1.前后都不空
做法:把这个块直接插入链表头部后面(头插法)
2.前不空后空
做法:把后面的块先从链表取下,再进行合并最后头插法
3.前空后不空
做法:把前面的块先从链表取下,再进行合并最后头插法
4.前后都空
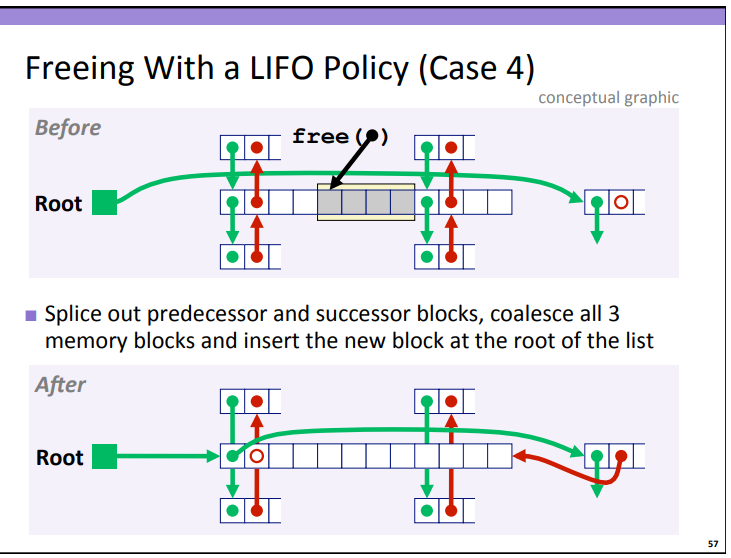
做法:把前面和后面的块先从链表取下,再进行合并最后头插法(这些图都是来自上面提到的pdf)
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
/*coalesce the block and change the point*/
/* 前后都不空 */
if(prev_alloc && next_alloc)
{
//什么也不做,待会直接返回bp
}
/* 前不空后空 */
else if(prev_alloc && !next_alloc)
{
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
fix_linklist(NEXT_BLKP(bp));/*后面的块从链表取下*/
PUT(HDRP(bp), PACK(size,0));
PUT(FTRP(bp), PACK(size,0));
}
/* 前空后不空 */
else if(!prev_alloc && next_alloc)
{
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
fix_linklist(PREV_BLKP(bp)); /*前面的块从链表取下*/
PUT(FTRP(bp),PACK(size,0));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));
bp = PREV_BLKP(bp);
}
/* 前后都空 */
else
{
size +=GET_SIZE(FTRP(NEXT_BLKP(bp)))+ GET_SIZE(HDRP(PREV_BLKP(bp)));
fix_linklist(PREV_BLKP(bp)); /*前面的块从链表取下*/
fix_linklist(NEXT_BLKP(bp));/*后面的块从链表取下*/
PUT(FTRP(NEXT_BLKP(bp)),PACK(size,0));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));
bp = PREV_BLKP(bp);
}
insert_to_Emptylist(bp); //头插法
return bp;
}
malloc
由于fit被设计成接口,所以malloc与上面的代码一样,所以就是重写first-fit和place函数
找到block是first-fit的工作
先从链表把找到的块取下,split然后再重新接上链表(调用insert_to_Emptylist函数)是place函数的工作
void *mm_malloc(size_t size)
{
size_t asize;
size_t extendsize;
char *bp;
if(size ==0) return NULL;
if(size <= DSIZE)
{
asize = 2*(DSIZE);
}
else
{
asize = (DSIZE)*((size+(DSIZE)+(DSIZE-1)) / (DSIZE));
}
//asize = round_up(size,8);
if((bp = first_fit(asize))!= NULL)
{
place(bp,asize);
return bp;
}
/*apply new block*/
extendsize = MAX(asize,CHUNKSIZE);
if((bp = extend_heap(extendsize/DSIZE))==NULL)
{
return NULL;
}
place(bp,asize);
return bp;
}
first-fit
static void *fist_fit(size_t size)
{
char *temp = GET(root);
while(temp != NULL)
{
if(GET_SIZE(HDRP(temp))>=asize) return temp; //从首节点开始找寻
temp = GET(NEXT_LINKNODE_RP(temp)); //temp = temp->next
}
return NULL;
}
split(place)
static void place(void *bp,size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp));
fix_linklist(bp);/*先从链表把找到的块取下*/
if((csize-asize)>=(2*DSIZE))
{
PUT(HDRP(bp),PACK(asize,1));
PUT(FTRP(bp),PACK(asize,1));
bp = NEXT_BLKP(bp); //split后的块
PUT(HDRP(bp),PACK(csize-asize,0));
PUT(FTRP(bp),PACK(csize-asize,0));
PUT(NEXT_LINKNODE_RP(bp),0);
PUT(PREV_LINKNODE_RP(bp),0);
coalesce(bp); /*重新接上链表*/
}
else
{
PUT(HDRP(bp),PACK(csize,1));
PUT(FTRP(bp),PACK(csize,1)); /*不切割直接取下来就行*/
}
}
fix_linklist(从链表取block)
p作为我们要取的block
p->prev->next = p->next
p->next->prev = p->prev
inline void fix_linklist(char *p)
{
char *prevp = GET(PREV_LINKNODE_RP(p));
char *nextp = GET(NEXT_LINKNODE_RP(p));
if(prevp == NULL)
{
if(nextp != NULL)PUT(PREV_LINKNODE_RP(nextp),0);
PUT(root,nextp);
}
else
{
if(nextp != NULL)PUT(PREV_LINKNODE_RP(nextp),prevp);
PUT(NEXT_LINKNODE_RP(prevp),nextp);
}
PUT(NEXT_LINKNODE_RP(p),0);
PUT(PREV_LINKNODE_RP(p),0);
}
insert_to_Emptylist(头插法)
inline void insert_to_Emptylist(char *p)
{
char *nextp = GET(root);
if(nextp != NULL)
PUT(PREV_LINKNODE_RP(nextp),p);
PUT(NEXT_LINKNODE_RP(p),nextp); //root
PUT(root,p);
}
free
free 和merge代码分离了,所以free代码就没什么难度了,就是把header和footer置0
void mm_free(void *bp)
{
if(bp == 0)
return;
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
PUT(NEXT_LINKNODE_RP(bp),0);
PUT(PREV_LINKNODE_RP(bp),0);
coalesce(bp);
}
realloc
跟上面没有区别,因为realloc就是malloc的包装函数
void *mm_realloc(void *ptr, size_t size)
{
size_t oldsize;
void *newptr;
/* If size == 0 then this is just free, and we return NULL. */
if(size == 0)
{
mm_free(ptr);
return 0;
}
/* If oldptr is NULL, then this is just malloc. */
if(ptr == NULL)
{
return mm_malloc(size);
}
oldsize = GET_SIZE(HDRP(ptr));
newptr = mm_malloc(size);
/* If realloc() fails the original block is left untouched */
if(!newptr)
{
return 0;
}
/* Copy the old data. */
oldsize = GET_SIZE(HDRP(ptr));
if(size < oldsize) oldsize = size;
memcpy(newptr, ptr, oldsize);
/* Free the old block. */
mm_free(ptr);
return newptr;
}
结果
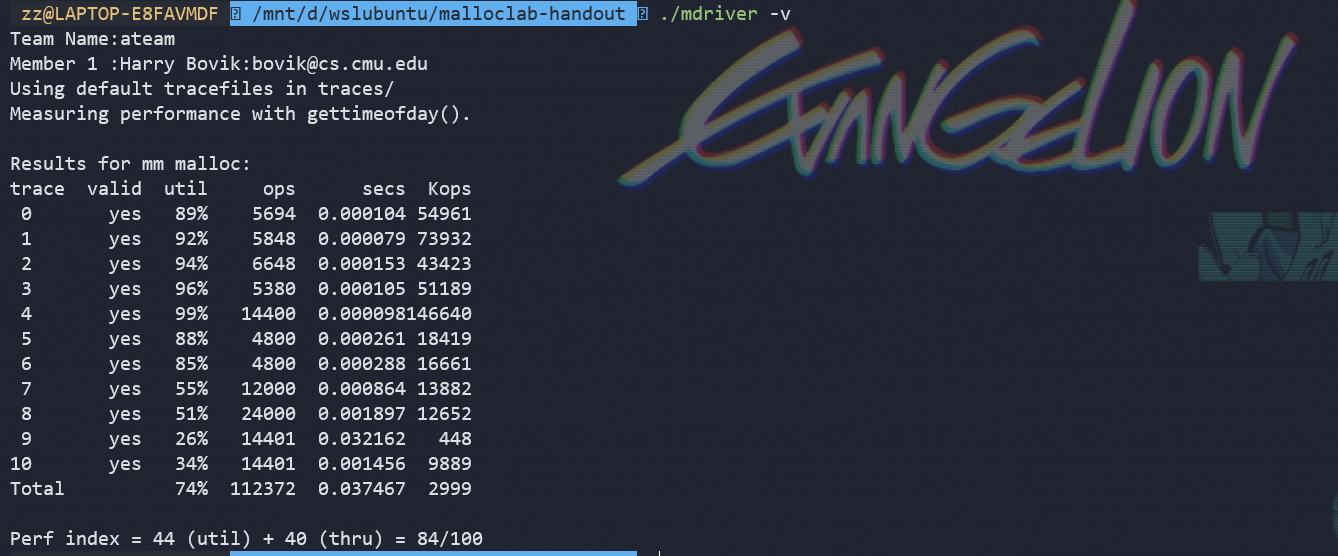
分析:
1.与上面有什么不同吗?
找寻blcok是遍寻链表,在malloc 和free是多了从链表取节点和最后重新挂上的步骤
2.那个pdf真的很有用
分离链表(Segregated Free Lists)
其实分离链表与显式没有什么大的区别,就是多维护几个链表而已,而多几个链表也意味着多几个root
而block结构和显式是一样的
宏
#define GET_HEAD(num) (char *)(long)((heap_listp + WSIZE * num)) //通过num找到链表的root
init
多的root在init时就要体现出来,所以我把inti分成两部分:第一部分还是照旧分配4个块 ,第二部分是进行root的分配
并且按照与显式的布局一样把root放在首的后面,序言块的前面.root的数量用root_num表示(自己想要多少个链表就要多少个)。并且root的结构也变了,现在root只占4字节(因为只要有next就行)
int mm_init(void)
{
if((heap_listp = mem_sbrk((4+root_num)*WSIZE)) == (void *)-1)
return -1;
/* 初始化root*/
for(int i = 0; i < root_num; i++){
PUT(heap_listp + i*WSIZE, NULL);
}
PUT(heap_listp + root_num * WSIZE, 0);
/*
* 序言块和结尾块均设置为已分配, 方便考虑边界情况
*/
PUT(heap_listp + ((1 + root_num )*WSIZE), PACK(DSIZE, 1)); /* 填充序言块 */
PUT(heap_listp + ((2 + root_num )*WSIZE), PACK(DSIZE, 1)); /* 填充序言块 */
PUT(heap_listp + ((3 + root_num )*WSIZE), PACK(0, 1)); /* 结尾块 */
/* 扩展空闲空间 */
if(extend_heap(CHUNKSIZE/WSIZE) == NULL)
return -1;
return 0;
}
void *extend_heap(size_t words)
{
/* bp总是指向有效载荷(prev) */
char *bp;
size_t size;
/* 根据传入字节数奇偶, 考虑对齐 */
size = (words % 2) ? (words+1) * WSIZE : words * WSIZE;
/* 分配 */
if((long)(bp = mem_sbrk(size)) == -1)
return NULL;
/* 设置头部和脚部 */
PUT(HDRP(bp),PACK(size,0)); //设置header 其实就是设置old结束块,因为mem_sbrk返回old mem_brk(指向结束块)
PUT(FTRP(bp),PACK(size,0));
PUT(NEXT_LINKNODE_RP(bp),0); //设置next
PUT(PREV_LINKNODE_RP(bp),0);
PUT(HDRP(NEXT_BLKP(bp)),PACK(0,1)); //set new 结束块
/* 判断相邻块是否是空闲块, 进行合并 */
return coalesce(bp);
}
merge(coalesce)
唯一有变化的就是insert插入链表有变化(但把任务交付给了insert_to_list函数)
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
/*coalesce the block and change the point*/
/* 前后都不空 */
if(prev_alloc && next_alloc)
{
//什么也不做,待会直接返回bp
}
/* 前不空后空 */
else if(prev_alloc && !next_alloc)
{
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
fix_linklist(NEXT_BLKP(bp));/*后面的块从链表取下*/
PUT(HDRP(bp), PACK(size,0));
PUT(FTRP(bp), PACK(size,0));
}
/* 前空后不空 */
else if(!prev_alloc && next_alloc)
{
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
fix_linklist(PREV_BLKP(bp)); /*前面的块从链表取下*/
PUT(FTRP(bp),PACK(size,0));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));
bp = PREV_BLKP(bp);
}
/* 前后都空 */
else
{
size +=GET_SIZE(FTRP(NEXT_BLKP(bp)))+ GET_SIZE(HDRP(PREV_BLKP(bp)));
fix_linklist(PREV_BLKP(bp)); /*前面的块从链表取下*/
fix_linklist(NEXT_BLKP(bp));/*后面的块从链表取下*/
PUT(FTRP(NEXT_BLKP(bp)),PACK(size,0));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));
bp = PREV_BLKP(bp);
}
insert_to_list(bp); //头插法但要找到自己的root(通过GET_HEAD宏)
return bp;
}
search
通过大小找自己的root num
int search(size_t size)
{
int i;
for(i = 4; i <=root_num; i++){
if(size <= (1 << i)) //alige to 8
return i-4;
}
return i-4;
}
insert_to_list
通过search找到root num,再同过GET_HEAD宏找到root,再进行头插法
跟显式的inser_to_Emptylist只有找root一个改变
inline void insert_to_list(char *p)
{
int num = search(GET_SIZE(HDRP(p)));
char *root = GET_HEAD(num);
char *nextp = GET(root);
if(nextp != NULL)
PUT(PREV_LINKNODE_RP(nextp),p);
PUT(NEXT_LINKNODE_RP(p),nextp); //root
PUT(root,p);
}
fix_linklist(从链表取block)
和显式还是只多了一步找root
inline void fix_linklist(char *p)
{
size_t size = GET_SIZE(HDRP(p));
/* 根据块大小找到头节点位置 */
int num = search(size);
char *root = GET_HEAD(num);
char *prevp = GET(PREV_LINKNODE_RP(p));
char *nextp = GET(NEXT_LINKNODE_RP(p));
if(prevp == NULL)
{
if(nextp != NULL)PUT(PREV_LINKNODE_RP(nextp),0);
PUT(root,nextp);
}
else
{
if(nextp != NULL)PUT(PREV_LINKNODE_RP(nextp),prevp);
PUT(NEXT_LINKNODE_RP(prevp),nextp);
}
PUT(NEXT_LINKNODE_RP(p),0);
PUT(PREV_LINKNODE_RP(p),0);
}
malloc
由于fit被设计成接口,所以malloc与上面的代码一样,所以就是重写first-fit和place函数
在不同的链表找到block是first-fit的工作
先从链表把找到的块取下,split然后再重新接上链表(调用insert_to_list函数)是place函数的工作
void *mm_malloc(size_t size)
{
size_t asize;
size_t extendsize;
char *bp;
if(size ==0) return NULL;
if(size <= DSIZE)
{
asize = 2*(DSIZE);
}
else
{
asize = (DSIZE)*((size+(DSIZE)+(DSIZE-1)) / (DSIZE));
}
if((bp = first_fit(asize))!= NULL)
{
place(bp,asize);
return bp;
}
/*apply new block*/
extendsize = MAX(asize,CHUNKSIZE);
if((bp = extend_heap(extendsize/DSIZE))==NULL)
{
return NULL;
}
place(bp,asize);
return bp;
}
first-fit
- 先从对应的大小类的空闲链表中查找
- 如果找不到,则到下一个更大的大小类查找
- 如果都找不到,则扩展堆
- 相比于显式,只是多了找root和换root两步
static void *find_fit(size_t asize)
{
int num = search(asize);
/* 如果找不到合适的块,那么就搜索下一个更大的大小类 */
while(num < root_num) {
char *temp = GET(GET_HEAD(num));
while(temp != NULL){
if(GET_SIZE(HDRP(temp))>=asize) return temp; //从首节点开始找寻
temp = GET(NEXT_LINKNODE_RP(temp)); //temp = temp->next
}
/* 找不到则进入下一个大小类 */
num++;
}
return NULL;
}
split(place)
place函数与上面没什么不同,因为有关链表的操作都是调用函数,只是函数会有不同
static void place(void *bp,size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp));
fix_linklist(bp);/*先从链表把找到的块取下*/
if((csize-asize)>=(2*DSIZE))
{
PUT(HDRP(bp),PACK(asize,1));
PUT(FTRP(bp),PACK(asize,1));
bp = NEXT_BLKP(bp); //split后的块
PUT(HDRP(bp),PACK(csize-asize,0));
PUT(FTRP(bp),PACK(csize-asize,0));
PUT(NEXT_LINKNODE_RP(bp),0);
PUT(PREV_LINKNODE_RP(bp),0);
coalesce(bp); /*重新接上链表*/
}
else
{
PUT(HDRP(bp),PACK(csize,1));
PUT(FTRP(bp),PACK(csize,1)); /*不切割直接取下来就行*/
}
}
free
free和上面代码是一样的,因为涉及到链表的代码都交给coalesce函数了
void mm_free(void *bp)
{
if(bp == 0)
return;
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
PUT(NEXT_LINKNODE_RP(bp),NULL);
PUT(PREV_LINKNODE_RP(bp),NULL);
coalesce(bp);
}
realloc
跟上面没有区别,因为realloc就是malloc的包装函数,而且我也不打算优化
void *mm_realloc(void *ptr, size_t size)
{
size_t oldsize;
void *newptr;
/* If size == 0 then this is just free, and we return NULL. */
if(size == 0)
{
mm_free(ptr);
return 0;
}
/* If oldptr is NULL, then this is just malloc. */
if(ptr == NULL)
{
return mm_malloc(size);
}
oldsize = GET_SIZE(HDRP(ptr));
newptr = mm_malloc(size);
/* If realloc() fails the original block is left untouched */
if(!newptr)
{
return 0;
}
/* Copy the old data. */
oldsize = GET_SIZE(HDRP(ptr));
if(size < oldsize) oldsize = size;
memcpy(newptr, ptr, oldsize);
/* Free the old block. */
mm_free(ptr);
return newptr;
}
结果

分析:
相比显式就是多管理几个链表,所以对应的函数,就多了关于找root换root的步骤
另外在做的时候有错误是关于寻找next的时候,关于地址直接解引用导致segment fult,找死我了
总结
1.我是想把我从0开始到实现的全过程记录下来,可能会显得繁琐导致可能没什么人看。(也很正常,毕竟我实际在想的时候,思维就会转圈,不是说思维是螺旋上升的吗),过程中很多segment fault 但是我的大部分是宏的问题,后来我的宏就是照书硬抄,问题就少了很多。
2.我还是想把我代码的一遍一遍迭代的过程说清楚,说明他们之间有什么不同,具体是怎么优化的(其实也没有很具体,毕竟我数学很不好),而且如果是慢慢迭代上来的就会发现没什么难的(大概),显式比隐式多了链表,分离比显式多了几个链表
3.红黑树我就没打算写了(我这个代码水平有限,时间也有限),但是如果你对它很感兴趣可以去看b站的一个up(我觉得他超强的)(第三种实现:红黑树哔哩哔哩bilibili)
4.本来的重点就是关注malloc 和free的实现,所以对realloc就没什么优化
5.最近我突然听到曹格的格格blue专辑,我天超好听。
参考:
1.最早是看到a malloc tutorial(wiki-prog.infoprepa.epita.fr/images/0/04…)这个pdf和blog(danluu.com/malloc-tuto…)开始有想法的
2.上面提到的up yaaangmin(yaaangmin的个人空间哔哩哔哩bilibili)
3.是参考了许多blog对malloc lab的实现(太多了我就不列举了)
4.书上的源代码csapp.cs.cmu.edu/3e/ics3/cod…
