

设计和部署 API 以服务于机器学习模型。
Intuition
CLI 应用程序使与模型交互变得更加容易,特别是对于可能不想深入研究代码库的团队成员。但是使用 CLI 为模型提供服务有几个限制:
- 用户需要访问终端、代码库、虚拟环境等。
- 终端上的 CLI 输出不可导出
为了解决这些问题,将开发一个应用程序编程接口 (API),_任何人都_可以通过一个简单的请求与应用程序进行交互。
最终用户可能不会直接与 API 交互,但可能会使用向发送请求的 UI/UX 组件。
服务
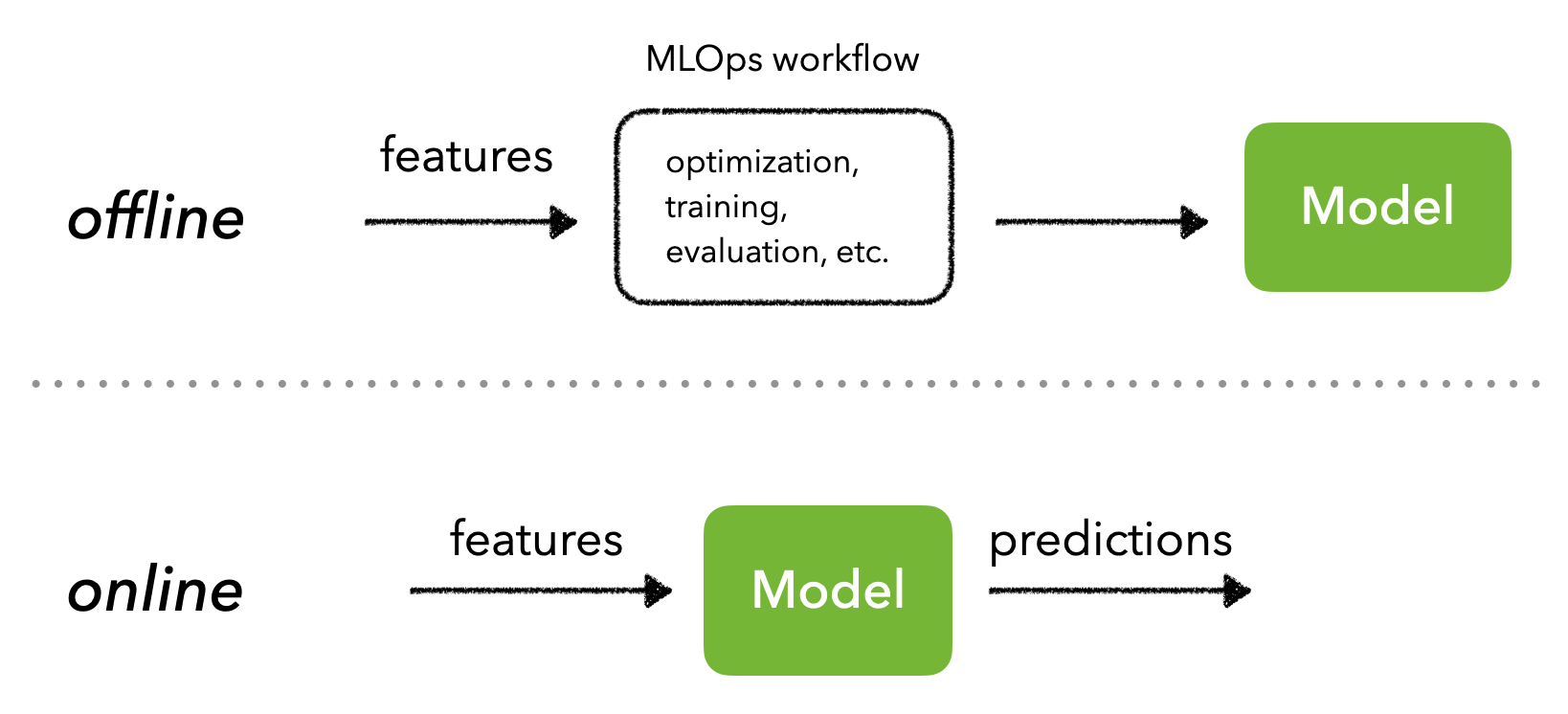
API 允许不同的应用程序实时相互通信。但是在提供预测服务时,需要首先决定是批量还是实时进行,这完全基于特征空间(有限与无限制)。
批量服务
可以对一组有限的输入进行批量预测,然后将其写入数据库以进行低延迟推理。当用户或下游进程实时发送推理请求时,会返回数据库中的缓存结果。
- ✅ 生成和缓存预测,以便为用户提供非常快速的推理。
- ✅ 该模型不需要作为它自己的服务进行旋转,因为它从未实时使用。
- ❌ 如果用户开发了当前预测所基于的旧数据未捕获的新兴趣,则预测可能会变得陈旧。
- ❌ 输入特征空间必须是有限的,因为需要在需要实时预测之前生成所有预测。
批量服务任务
哪些任务适合批量服务?
显示答案
根据现有用户的观看历史推荐他们喜欢的内容。然而,在第二天处理他们的历史记录之前,_新用户可能只会收到一些基于他们明确兴趣的通用推荐。_即使不进行批量服务,缓存非常流行的输入特征集(例如,明确兴趣的组合导致某些推荐内容)可能仍然有用,以便可以更快地提供这些预测。
实时服务
还可以提供实时预测,通常是通过使用适当的输入数据向 API 发出请求。

- ✅ 可以产生更多最新的预测,从而产生更有意义的用户体验等。
- ❌ 需要托管微服务来处理请求流量。
- ❌ 需要实时监控,因为输入空间是无限的,这可能会产生错误的预测。
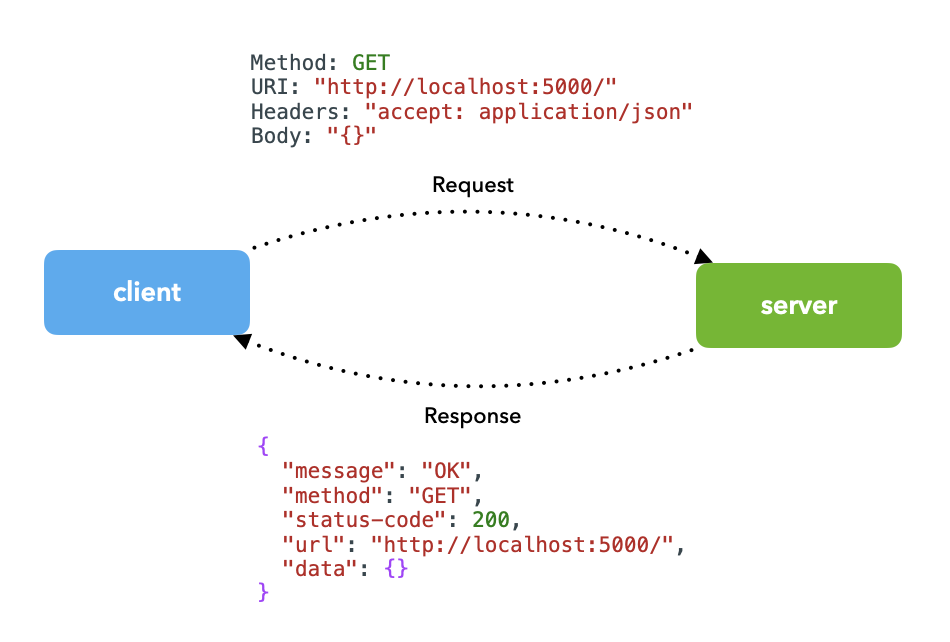
在本课中,将创建启用实时服务所需的 API。在情况下,交互涉及客户端(用户、其他应用程序等)向服务器发送带有适当输入的_请求_(例如预测请求)(应用程序具有经过训练的模型)并接收_响应_(例如预测)作为回报。
要求
用户将以请求的形式与 API 进行交互。让看一下请求的不同组成部分:
URI
统一资源标识符 (URI) 是特定资源的标识符。
https:// localhost: 8000 /models/{modelId}/ ?filter=passed #details
方法
方法是对 URI 定义的特定资源执行的操作。有许多可能的方法可供选择,但以下四种是最受欢迎的,它们通常被称为CRUD ,因为它们允许您创建、读取、更新和删除。
GET: 获取资源。POST: 创建或更新资源。PUT/PATCH: 创建或更新资源。DELETE: 删除资源。
note
您可以使用
POSTorPUTrequest 方法来创建和修改资源,但主要区别在于PUT幂等性,这意味着您可以重复调用该方法,并且每次都会产生相同的状态。然而,POST多次调用可能会导致创建多个实例,因此每次都会更改整体状态。
POST /models/<new_model> -d {} # error since we haven't created the `new_model` resource yet
POST /models -d {} # creates a new model based on information provided in data
POST /models/<existing_model> -d {} # updates an existing model based on information provided in data
PUT /models/<new_model> -d {} # creates a new model based on information provided in data
PUT /models/<existing_model> -d {} # updates an existing model based on information provided in data
可以使用cURL通过以下选项执行 API 调用:
用法:curl [选项...]
-X, --request HTTP 方法(即 GET)
-H, --header 要发送到请求的标头(例如身份验证)
-d, --data 数据到 POST、PUT/PATCH、DELETE(通常是 JSON)
...
例如,如果想要 GET all models, cURL 命令将如下所示:
curl -X GET "http://localhost:8000/models"
header
标头包含有关特定事件的信息,通常在客户端的请求和服务器的响应中都可以找到。它的范围可以从他们将发送和接收的格式类型、身份验证和缓存信息等。
curl -X GET "http://localhost:8000/" \ # method and URI
-H "accept: application/json" \ # client accepts JSON
-H "Content-Type: application/json" \ # client sends JSON
body
正文包含处理请求可能需要的信息。它通常是在/请求方法期间发送POST的JSON 对象。PUT``PATCH``DELETE
curl -X POST "http://localhost:8000/models" \ # method and URI
-H "accept: application/json" \ # client accepts JSON
-H "Content-Type: application/json" \ # client sends JSON
-d "{'name': 'RoBERTa', ...}" # request body
response
从服务器收到的响应是发送的请求的结果。响应还包括标题和正文,其中应包含正确的 HTTP 状态代码以及显式消息、数据等。
{
"message": "OK",
"method": "GET",
"status-code": 200,
"url": "http://localhost:8000/",
"data": {}
}
可能还希望在响应中包含其他元数据,例如模型版本、使用的数据集等。下游消费者可能感兴趣的任何内容或可能对检查有用的元数据。
根据具体情况,有许多HTTP 状态代码可供选择,但以下是最常见的选项:
| 代码 | 描述 |
|---|---|
200 OK | 方法运行成功。 |
201 CREATED | POST或PUT方法成功创建资源。 |
202 ACCEPTED | 该请求已被接受处理(但处理可能不会完成)。 |
400 BAD REQUEST | 由于客户端错误,服务器无法处理请求。 |
401 UNAUTHORIZED | 您缺少必需的身份验证。 |
403 FORBIDDEN | 你不被允许做这个操作。 |
404 NOT FOUND | 找不到您要查找的资源。 |
500 INTERNAL SERVER ERROR | 系统进程某处出现故障。 |
501 NOT IMPLEMENTED | 此资源上的操作尚不存在。 |
最佳实践
在设计 API 时,需要遵循一些最佳实践:
- URI 路径、消息等应尽可能明确。避免使用神秘的资源名称等。
- 使用名词而不是动词来命名资源。请求方法已经考虑了动词(✅
GET /users不是 ❌GET /get_users)。 - 复数名词(✅
GET /users/{userId}不是 ❌GET /user/{userID})。 - 在 URI 中使用破折号表示资源和路径参数,但使用下划线表示查询参数 (
GET /nlp-models/?find_desc=bert)。 - 向用户返回适当的 HTTP 和信息性消息。
应用
将在一个单独的app目录中定义 API,因为将来可能会有额外的包,例如tagifai,不希望应用程序附加到任何一个包。在app目录中,将创建以下脚本:
mkdir app
cd app
touch api.py gunicorn.py schemas.py
cd ../
app/
├── api.py - FastAPI app
├── gunicorn.py - WSGI script
└── schemas.py - API model schemas
api.py:将包含 API 初始化和端点的主脚本。gunicorn.py:用于定义 API worker 配置的脚本。schemas.py:将在资源端点中使用的不同对象的定义。
快速API
将使用FastAPI作为框架来构建 API 服务。还有很多其他框架选项,例如Flask、Django,甚至是非基于 Python 的选项,例如Node、Angular等。FastAPI 结合了这些框架的许多优点,并且正在迅速成熟并被更广泛地采用。它的显着优势包括:
- 用 Python 开发
- 高性能_
- 通过pydantic进行数据验证
- 自动生成的文档
- 依赖注入
- 通过 OAuth2 确保安全
pip install fastapi==0.78.0
# Add to requirements.txt
fastapi==0.78.0
您对框架的选择还取决于您团队的现有系统和流程。然而,随着微服务的广泛采用,可以将特定应用程序包装在选择的任何框架中并公开适当的资源,以便所有其他系统都可以轻松地与之通信。
初始化
第一步是api.py通过定义标题、描述和版本等元数据在脚本中初始化 API:
# app/api.py
from fastapi import FastAPI
# Define application
app = FastAPI(
title="TagIfAI - Made With ML",
description="Classify machine learning projects.",
version="0.1",
)
第一个端点将是一个简单的端点,希望显示一切都按预期工作。端点的路径将只是/(当用户访问基本 URI 时),它将是一个GET请求。这个简单的端点通常用作健康检查,以确保应用程序确实启动并正常运行。
# app/api.py
from http import HTTPStatus
from typing import Dict
@app.get("/")
def _index() -> Dict:
"""Health check."""
response = {
"message": HTTPStatus.OK.phrase,
"status-code": HTTPStatus.OK,
"data": {},
}
return response
通过第 4 行中的路径操作装饰器让应用程序知道端点位于,/并且返回带有200 OKHTTP 状态代码的 JSON 响应。
在实际
api.py脚本中,您会注意到甚至索引函数看起来也不同。别担心,正在慢慢地将组件添加到端点并在此过程中证明它们的合理性。
Launching
正在使用Uvicorn,这是一个快速的ASGI服务器,可以在单个进程中运行异步代码来启动应用程序。
pip install uvicorn==0.17.6
# Add to requirements.txt
uvicorn==0.17.6
可以使用以下命令启动应用程序:
uvicorn app.api:app \ # location of app (`app` directory > `api.py` script > `app` object)
--host 0.0.0.0 \ # localhost
--port 8000 \ # port 8000
--reload \ # reload every time we update
--reload-dir tagifai \ # only reload on updates to `tagifai` directory
--reload-dir app # and the `app` directory
INFO: Will watch for changes in these directories: ['/Users/goku/Documents/madewithml/mlops/app', '/Users/goku/Documents/madewithml/mlops/tagifai']
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
INFO: Started reloader process [57609] using statreload
INFO: Started server process [57611]
INFO: Waiting for application startup.
INFO: Application startup complete.
请注意,只重新加载对特定目录的更改,因为这是为了避免重新加载不会影响应用程序的文件,例如日志文件等。
如果想管理多个 uvicorn 工作者以在应用程序中启用并行性,可以将Gunicorn与 Uvicorn 结合使用。这通常在将处理有意义的流量的生产环境中完成。已经包含了一个app/gunicorn.py带有可定制配置的脚本,可以使用以下命令启动所有工作人员:
gunicorn -c config/gunicorn.py -k uvicorn.workers.UvicornWorker app.api:app
还将这两个命令添加到README.md文件中:
uvicorn app.api:app --host 0.0.0.0 --port 8000 --reload --reload-dir tagifai --reload-dir app # dev
gunicorn -c app/gunicorn.py -k uvicorn.workers.UvicornWorker app.api:app # prod
Requests
现在应用程序正在运行,可以GET使用几种不同的方法提交请求:
-
在浏览器上访问端点http://localhost:8000/
-
cURL
curl -X GET http://localhost:8000/ -
通过代码访问端点。在这里,展示了如何使用 Python 中的requests库来完成它,但它可以使用大多数流行的语言来完成。您甚至可以使用在线工具将您的 cURL 命令转换为代码!
import json import requests response = requests.get("http://localhost:8000/") print (json.loads(response.text)) -
使用Postman等外部工具,这对于托管测试非常有用,您可以保存并与其他人共享等。
对于所有这些,将从 API 中看到完全相同的响应:
{
"message": "OK",
"status-code": 200,
"data": {}
}
装饰器
在GET \上面的请求响应中,关于实际请求的信息并不多,但是有 URL、时间戳等详细信息很有用。但是不想为每个端点单独执行此操作,所以让使用装饰器自动将相关元数据添加到响应中
# app/api.py
from datetime import datetime
from functools import wraps
from fastapi import FastAPI, Request
def construct_response(f):
"""Construct a JSON response for an endpoint."""
@wraps(f)
def wrap(request: Request, *args, **kwargs) -> Dict:
results = f(request, *args, **kwargs)
response = {
"message": results["message"],
"method": request.method,
"status-code": results["status-code"],
"timestamp": datetime.now().isoformat(),
"url": request.url._url,
}
if "data" in results:
response["data"] = results["data"]
return response
return wrap
在第 10 行传入了一个Request实例,因此可以访问请求方法和 URL 等信息。因此,端点函数也需要将此 Request 对象作为输入参数。一旦从端点函数接收到结果f,就可以附加额外的细节并返回更多信息的响应。要使用这个装饰器,只需要相应地包装函数。
@app.get("/")
@construct_response
def _index(request: Request) -> Dict:
"""Health check."""
response = {
"message": HTTPStatus.OK.phrase,
"status-code": HTTPStatus.OK,
"data": {},
}
return response
{
message: "OK",
method: "GET",
status-code: 200,
timestamp: "2021-02-08T13:19:11.343801",
url: "http://localhost:8000/",
data: { }
}
还有一些应该注意的内置装饰器。已经看到了路径操作装饰器(例如@app.get("/")),它定义了端点的路径以及其他属性。还有事件装饰器( @app.on_event()),可以使用它来启动和关闭应用程序。例如,使用 ( @app.on_event("startup")) 事件来加载模型以用于推理的工件。将其作为事件执行的好处是,服务在完成之前不会启动,因此不会过早处理任何请求并导致错误。类似地,可以用 ( ) 来执行关闭事件@app.on_event("shutdown"),例如保存日志、清理等。
from pathlib import Path
from config import config
from config.config import logger
from tagifai import main
@app.on_event("startup")
def load_artifacts():
global artifacts
run_id = open(Path(config.CONFIG_DIR, "run_id.txt")).read()
artifacts = main.load_artifacts(model_dir=config.MODEL_DIR)
logger.info("Ready for inference!")
文档
当定义一个端点时,FastAPI 会根据它的输入、输入、输出等自动生成一些文档(遵守OpenAPI标准)。可以通过在 api 运行时转到任何浏览器上的端点来访问Swagger UI以获取文档/docs.
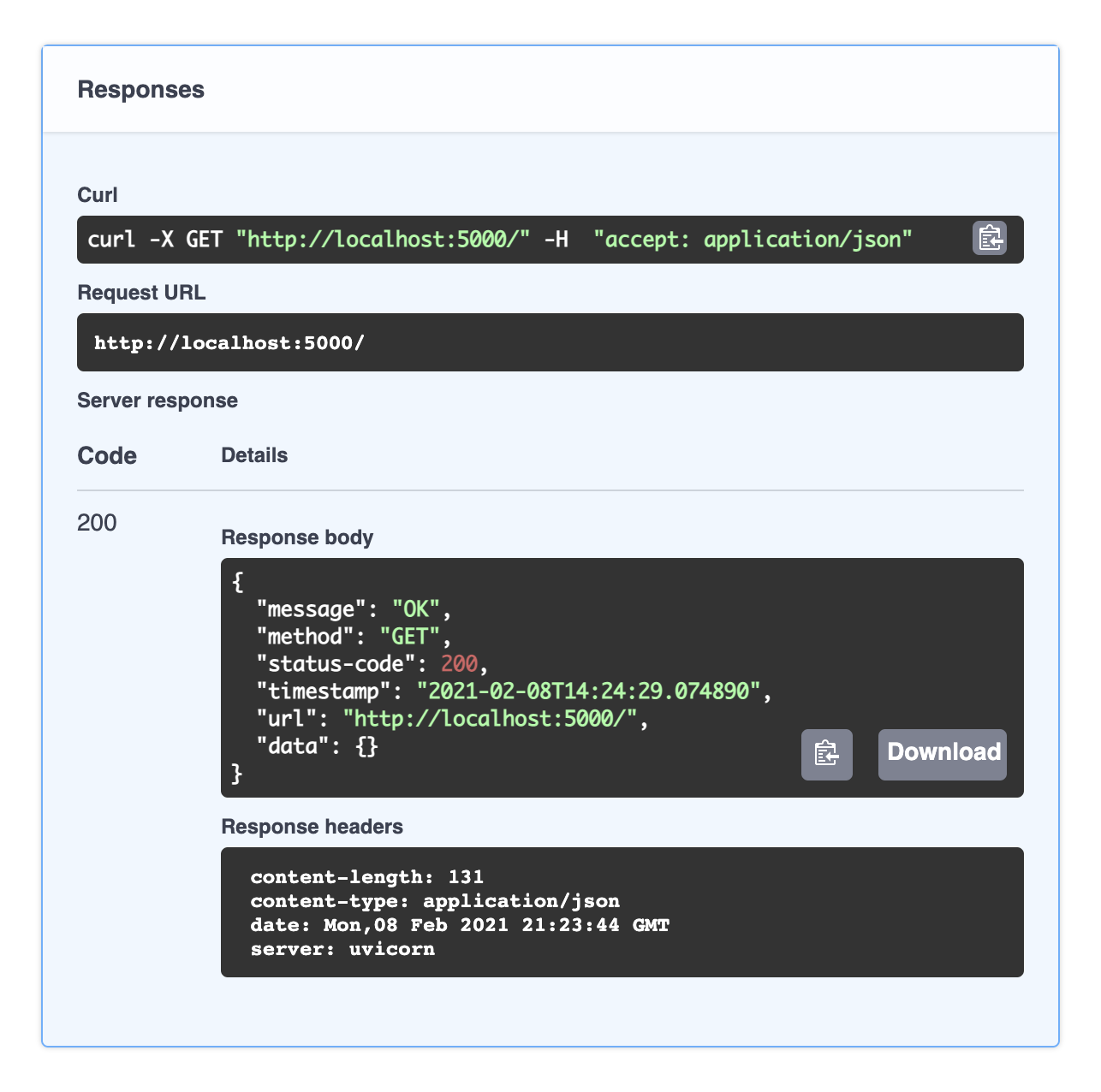
单击端点 > Try it out>Execute以查看服务器的响应将是什么样子。由于这是一个GET没有任何输入的请求,请求正文是空的,但对于其他方法,需要提供一些信息(将在发出POST请求时说明这一点)。
请注意,端点是在 UI 中的部分下组织的。可以tags在脚本中定义端点时使用:
@app.get("/", tags=["General"])
@construct_response
def _index(request: Request) -> Dict:
"""Health check."""
response = {
"message": HTTPStatus.OK.phrase,
"status-code": HTTPStatus.OK,
"data": {},
}
return response
资源
在为 API 设计资源时,需要考虑以下问题:
-
[USERS]: 谁是最终用户?这将定义需要公开哪些资源。- 想要与 API 交互的开发人员。
- 想要测试和检查模型及其性能的产品团队。
- 想要对传入项目进行分类的后端服务。
-
[ACTIONS]:用户希望能够执行哪些操作?- 给定输入集的预测
- 性能检查
- 检查训练参数
查询参数
@app.get("/performance", tags=["Performance"])
@construct_response
def _performance(request: Request, filter: str = None) -> Dict:
"""Get the performance metrics."""
performance = artifacts["performance"]
data = {"performance":performance.get(filter, performance)}
response = {
"message": HTTPStatus.OK.phrase,
"status-code": HTTPStatus.OK,
"data": data,
}
return response
请注意,在这里传递了一个可选的查询参数filter来指示关心的性能子集。可以GET像这样在请求中包含这个参数:
curl -X "GET" \
"http://localhost:8000/performance?filter=overall" \
-H "accept: application/json"
这只会产生通过查询参数指示的性能子集:
{
"message": "OK",
"method": "GET",
"status-code": 200,
"timestamp": "2021-03-21T13:12:01.297630",
"url": "http://localhost:8000/performance?filter=overall",
"data": {
"performance": {
"precision": 0.8941372402587212,
"recall": 0.8333333333333334,
"f1": 0.8491658224308651,
"num_samples": 144
}
}
}
路径参数
下一个端点将是GET用于训练模型的参数。这一次,使用了一个路径参数args,它是 URI 中的必填字段。
@app.get("/args/{arg}", tags=["Arguments"])
@construct_response
def _arg(request: Request, arg: str) -> Dict:
"""Get a specific parameter's value used for the run."""
response = {
"message": HTTPStatus.OK.phrase,
"status-code": HTTPStatus.OK,
"data": {
arg: vars(artifacts["args"]).get(arg, ""),
},
}
return response
可以GET像这样执行请求,其中param是请求 URI 路径的一部分,而不是它的查询字符串的一部分。
curl -X "GET" \
"http://localhost:8000/args/learning_rate" \
-H "accept: application/json"
会收到这样的回复:
{
"message": "OK",
"method": "GET",
"status-code": 200,
"timestamp": "2021-03-21T13:13:46.696429",
"url": "http://localhost:8000/params/hidden_dim",
"data": {
"learning_rate": 0.14688087680118794
}
}
还可以创建一个端点来生成所有使用的参数:
查看
GET /args
@app.get("/args", tags=["Arguments"])
@construct_response
def _args(request: Request) -> Dict:
"""Get all arguments used for the run."""
response = {
"message": HTTPStatus.OK.phrase,
"status-code": HTTPStatus.OK,
"data": {
"args": vars(artifacts["args"]),
},
}
return response
可以
GET像这样执行请求,其中param是请求 URI 路径的一部分,而不是它的查询字符串的一部分。
curl -X "GET" \
"http://localhost:8000/args" \
-H "accept: application/json"
会收到这样的回复:
{
"message":"OK",
"method":"GET",
"status-code":200,
"timestamp":"2022-05-25T11:56:37.344762",
"url":"http://localhost:8001/args",
"data":{
"args":{
"shuffle":true,
"subset":null,
"min_freq":75,
"lower":true,
"stem":false,
"analyzer":"char_wb",
"ngram_max_range":8,
"alpha":0.0001,
"learning_rate":0.14688087680118794,
"power_t":0.158985493618746
}
}
}
模式
现在是时候定义预测端点了。需要使用想要分类的输入,因此需要定义在定义这些输入时需要遵循的模式。
# app/schemas.py
from typing import List
from fastapi import Query
from pydantic import BaseModel
class Text(BaseModel):
text: str = Query(None, min_length=1)
class PredictPayload(BaseModel):
texts: List[Text]
在这里,将一个对象定义为一个名为PredictPayload的对象列表。每个对象都是一个默认的字符串,并且必须至少有 1 个字符。Text``texts``Text``None
note
可以
PredictPayload这样定义:class PredictPayload(BaseModel): texts: List[str] = Query(None, min_length=1)
但是想创建非常明确的模式,以防将来想要合并更多的验证或添加额外的参数。
现在可以在预测端点中使用这个有效载荷:
from app.schemas import PredictPayload
from tagifai import predict
@app.post("/predict", tags=["Prediction"])
@construct_response
def _predict(request: Request, payload: PredictPayload) -> Dict:
"""Predict tags for a list of texts."""
texts = [item.text for item in payload.texts]
predictions = predict.predict(texts=texts, artifacts=artifacts)
response = {
"message": HTTPStatus.OK.phrase,
"status-code": HTTPStatus.OK,
"data": {"predictions": predictions},
}
return response
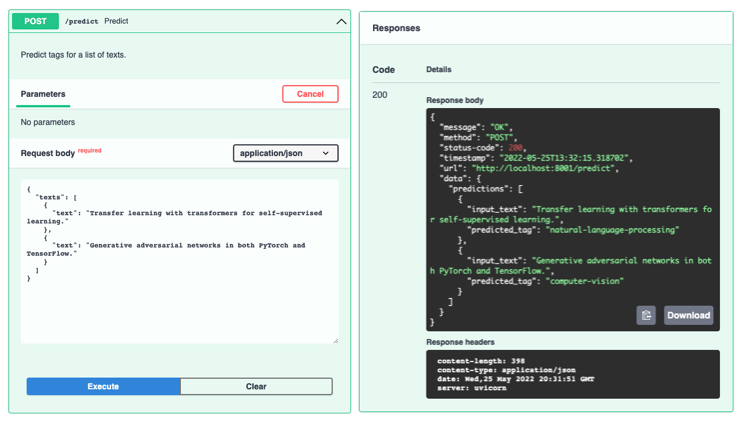
PredictPayload当想要使用/predict端点时,需要遵守架构:
curl -X 'POST' 'http://0.0.0.0:8000/predict' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"texts": [
{"text": "Transfer learning with transformers for text classification."},
{"text": "Generative adversarial networks for image generation."}
]
}'
{
"message":"OK",
"method":"POST",
"status-code":200,
"timestamp":"2022-05-25T12:23:34.381614",
"url":"http://0.0.0.0:8001/predict",
"data":{
"predictions":[
{
"input_text":"Transfer learning with transformers for text classification.",
"predicted_tag":"natural-language-processing"
},
{
"input_text":"Generative adversarial networks for image generation.",
"predicted_tag":"computer-vision"
}
]
}
}
验证
内置
在BaseModel这里使用 pydantic 的对象,因为它为所有的模式提供了内置的验证。在例子中,如果一个Text实例少于 1 个字符,那么服务将返回相应的错误消息和代码:
curl -X POST "http://localhost:8000/predict" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"texts\":[{\"text\":\"\"}]}"
{
"detail": [
{
"loc": [
"body",
"texts",
0,
"text"
],
"msg": "ensure this value has at least 1 characters",
"type": "value_error.any_str.min_length",
"ctx": {
"limit_value": 1
}
}
]
}
Custom
还可以使用装饰器在特定实体上添加自定义验证@validator,就像确保列表texts不为空一样。
class PredictPayload(BaseModel):
texts: List[Text]
@validator("texts")
def list_must_not_be_empty(cls, value):
if not len(value):
raise ValueError("List of texts to classify cannot be empty.")
return value
curl -X POST "http://localhost:8000/predict" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"texts\":[]}"
{
"detail":[
{
"loc":[
"body",
"texts"
],
"msg": "List of texts to classify cannot be empty.",
"type": "value_error"
}
]
}
最后,可以在类schema_extra下添加一个对象Config来描述示例的PredictPayload外观。当这样做时,它会自动出现在端点的文档中(单击Try it out)。
class PredictPayload(BaseModel):
texts: List[Text]
@validator("texts")
def list_must_not_be_empty(cls, value):
if not len(value):
raise ValueError("List of texts to classify cannot be empty.")
return value
class Config:
schema_extra = {
"example": {
"texts": [
{"text": "Transfer learning with transformers for text classification."},
{"text": "Generative adversarial networks in both PyTorch and TensorFlow."},
]
}
}
产品
为了使 API 成为一个独立的产品,需要为用户和资源创建和管理一个数据库。这些用户将拥有用于身份验证的凭据,并使用他们的权限与服务进行通信。当然,可以显示一个渲染的前端,以使所有这些与 HTML 表单、按钮等无缝连接。这正是旧 MWML 平台的构建方式,利用 FastAPI 为每天 500K+ 的服务请求提供高性能。
如果您正在构建产品,那么我强烈建议您使用这个生成模板来开始。它包括您的产品所需的主干架构:
- 数据库(模型、迁移等)
- 通过 JWT 进行身份验证
- 带有 Celery 的异步任务队列
- 通过 Vue JS 可定制的前端
- Docker 集成
- 那么多!
但是,对于大多数 ML 开发人员来说,由于微服务的广泛采用,不需要做所有这些。设计良好的 API 服务可以与所有其他服务(与框架无关)无缝通信,将适合任何流程并为整个产品增加价值。主要重点应该是确保服务正常工作并不断改进,这正是下一组课程将关注的内容(测试和监控)
模型服务器
除了将模型包装为单独的、可扩展的微服务之外,还可以使用专门构建的模型服务器来托管模型。模型服务器提供具有 API 层的注册表,以无缝检查、更新、服务、回滚等多个版本的模型。它们还提供自动扩展以满足吞吐量和延迟需求。流行的选项包括BentoML、MLFlow、TorchServe、RedisAI、Nvidia Triton Inference Server等。
模型服务器因其在整个团队中标准化模型部署和服务流程的能力而被广泛采用——实现无缝升级、验证和集成。
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

本文主体源自以下链接:
@article{madewithml,
author = {Goku Mohandas},
title = { Made With ML },
howpublished = {\url{https://madewithml.com/}},
year = {2022}
}
本文由mdnice多平台发布
