

多年来,人类一直有一个乌托邦式的目标,即建造能够像人一样思考和行为的智能机器。其中一个最吸引人的概念是使计算机能够 "看到 "并理解其周围的环境。
由于人工智能和处理能力的发展,计算机视觉技术已经在融入我们的日常生活方面取得了长足的进步。人工智能的分支--计算机视觉,重点是开发和利用数字系统来处理、检查和解释视觉输入。
一个神经网络预测图片中的项目,并在物体检测中使用边界框来识别它们,这是一种复杂的图像分类类型。因此,术语 "物体检测 "是指识别和定位图像中属于几个既定分类之一的项目。
YOLO就是这样一种物体检测算法。在这篇文章中,我们将谈论YOLO、YOLOv3的结构、它的相关性以及相关的关切。
什么是YOLO?
"你只看一次",或称YOLO,是CNN的一个系列,值得注意的是,它产生的结果几乎与最先进的技术相当,使用单一的端到端模型,可以实时识别物体。
这个程序在一张照片中搜索并识别各种物体(实时)。找到的照片的类别概率是给定的,YOLO中的物体检测是作为一项回归任务进行的。
YOLO利用一个卷积神经网络(CNN)来实时识别物体。顾名思义,该方法只需要通过神经网络进行一次前向传播来检测物体。
只有一个阶段的物体检测设计被称为单阶段物体检测器。它们将物体的检测视为一个直接的回归问题。这表明,在整个画面中,只用一个算法运行来做预测。
使用CNN同时预测多类概率和边界框。简单地说,网络直接从输入图片中输出类别概率和边界框坐标。
这些模型不包括区域提议阶段,即区域提议网络,它通常是两阶段项目检测器的一个组成部分,即图片中可能包含物体的区域。
YOLO算法有不同的变体。最流行的版本是YOLO v1、v3、v4和v5。 2022年,YOLOv6和YOLOv7在接近的几天内发布。
什么是YOLOv3?
一种名为YOLOv3的实时物体识别算法可以识别电影、直播或静态照片中的物体。YOLO机器学习技术使用深度CNN的特性来识别物体。
YOLO的第一版是在2015年开发的,而第三版是在2018年开发的。YOLOv3特征检测器的架构受到ResNet和FPN(特征金字塔网络)等知名架构的影响。
为了在不同的空间压缩下处理图像,YOLOv3特征检测器的代号Darknet-53有52个类似ResNet的跳过连接的卷积,以及类似FPN的共3个预测头。
最初,YOLOv3算法将一张图片划分为一个网格。每个网格单元预示着在上述预定分类中表现良好的项目周围存在特定数量的边界框(也称为锚框)。
每个边界框只检测一个项目,它有一个相应的信心分数,表明它期望该预测的正确性。来自原始数据集的地面真实盒的尺寸被聚类,以确定最典型的尺寸和形状,然后用于创建边界盒。
与YOLOv2一样,YOLOv3在各种输入分辨率下表现良好。与它的竞争对手Faster-RCNN-ResNet50(一种采用ResNet-50作为骨干的更快的RCNN架构)相比,YOLOv3在COCO-2017验证集中用尺寸为608 x 608的输入照片进行测试时,获得了37的mAP(平均准确度)。
其他设计,如Mobilenet-SSD,获得了30的mAP。然而,它们花了YOLOv3类似的时间来识别图片。
YOLOv3的意义
在速度、准确性和类别特异性方面,YOLOv3和早期版本有很大的不同。YOLOv2和YOLOv3在准确性、速度和结构方面是两极分化。在YOLOv3之前的两年,即2016年,YOLO v2发布。
虽然YOLOv3正式利用了Darknet-53,但YOLOv2是采用Darknet-19作为其骨干特征提取器。我们可以从YOLOv3的研究中观察到ResNet101比Darknet-52要快1.5倍。精度与ResNet-152相同,但速度快了2倍,所以显示的精度不需要在Darknet骨干网之间进行精度和速度的权衡。
从平均精度(mAP)和联合之上的交集(IOU)值来看,YOLOv3是快速而精确的。下面这张图是从YOLOv3出版物中更新获得的,显示了使用不同算法和骨干网识别微小、中等和大图片的平均精度(AP)。对于该变量,AP越大,就越准确。
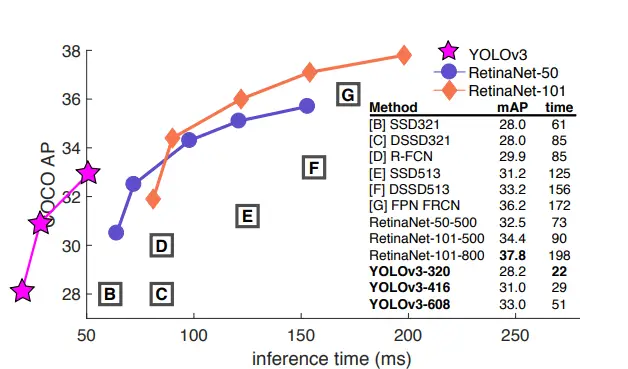
由于YOLO在识别小物品方面有多么糟糕,YOLOv2中对小物品的精度是其他算法无法比拟的。与其他算法相比,如RetinaNet(21.8)或SSD513,它对小物品的AP第二低,表现很差(AP=5.0)。
YOLOv3在现实生活中的应用
- **安全。**YOLO可以被运用在安全系统中,在一个区域内实施安全。
- **自主车辆。**在无人驾驶车辆中,YOLO算法可以用来寻找附近的东西,如其他汽车、行人和停车信号。由于没有人类司机在操作汽车,物体检测在自主车辆中进行,以防止事故。
最终,YOLO算法将在我们的计算机和移动设备中发挥传统人脸检测系统的作用。为了实时识别人、物体和其他目标,无人机或机器人等采用机器视觉的技术,将开始拥抱YOLO。
YOLOv3的问题
尽管非常精确,但YOLOv3有一个缺陷--它是倾斜的(指有偏见)。如果用较大的物体来训练它,它就不能准确地识别较小范围内的相同事物。
与RetinaNet相比,YOLOv3在速度和准确性方面确实表现出了权衡,因为RetinaNet的训练时间比YOLOv3长。只有通过更大的数据集,才能使YOLOv3的准确性与RetinaNet的准确性相当。
一个突出的例子是交通检测模型,由于有大量的不同汽车的照片,可以利用大量的数据来训练这个模型。另一方面,在难以收集大量数据集的情况下,YOLOv3不能成为利用利基模型的最佳选择。
与Faster R CNN相比,它的召回率较低,定位误差较大。由于每个网格只能建议两个边界框,YOLOv3在识别附近的物品方面很困难。此外,它很难检测到微小的东西。
最后的思考
YOLO彻底改变了物体检测相关的计算机视觉研究,是一种极其快速和精确的物体识别技术。
被称为Darknet-53的新特征提取,以及YOLOv3架构的很大一部分,在YOLOv4和YOLOv5版本中经历了重大变化。计算机视觉专家社区也对Ultralytics采用YOLOv5这个模型名称表示不赞同。
然而,YOLOv4已经被公众接受,被认为是YOLOv3的合法进步,而这个名称也没有那么大的分歧。另一方面,YOLOv5有未经验证的证据来支持其高于YOLOv4的进步。
