

前言
赶了两个礼拜公司的需求,再重新想要提笔写文章就很容易拖延症犯了。所以特地给自己的key result上加了写文章的任务。
关于原型,我也一直在思考应该写哪些方面的内容,能不能存在一些稍微不同也有所启发的点,而不是重复继承八股之类的东西。
所以还是从历史开始吧。
开端
在JavaScript还被称为Mocha的时候,原型就已经在设计之中了。Brendan Eich在最初设计时基于对Self语言的认可,选择了带有单个原型链接的委托机制,来创建动态的对象模型。但并没有在JavaScript1.0中实现,而是到了JavaScript1.1时出现了对prototype的定义,也就是原型的定义。
原型本质上就是一个对象,只不过它是一种特殊的对象,其自身的属性与所有由构造函数所创建的对象所共享。也就是说它是一个为其他对象提供属性的对象。
所以先抛去跟函数相关的那些内容,就能深的理解为什么说JavaScript是基于对象的语言了。那就是它本质就是一个个对象与对象之间的链接。
先给一个实例代码:
function Foo(x) {
this.x = x
}
const bar = new Foo(1)
const baz = new Foo(2)
此刻只关注对象的情况:
图中除了Null之外全都是JS对象,之所以使用单向箭头链接,就表明了他们对象之间的关系,是单向性的,最终将一个个对象串起来,这其实就是所谓的原型链。 原型和原型链最主要和最实质的内容其实就这点东西。
对象之前存在着共享机制,从底下看起,如果需要访问bar对象里的一个属性,比如name之类,它会先在自身对象内部查找是否存在着个属性,如果存在就直接返回值,而如果不存在就会往上一层指向的prototype对象里寻找,假设此时Foo.prototype里是有一个name属性,值为xavier。那bar对象就会返回这个值。
同时假设之后修改了Foo.prototype里name属性的值,变成了parker。那么对于bar和baz对象来说,之后他们所获取的name属性都会变成parker。这就是所谓的共享。一个原型对象底下可能会有无数的对象,它身上所有的属性都共享给底下的对象,但自身的修改也会影响底下所有对象之后获取值的改变。
不过存在一种情况,就是假设baz对象本身含有name属性值为Silver,那么不论Foo.prototype原型对象里的name值怎么改,它都会直接返回对象本身里的name属性,而不是继续向上搜索。
其实如果本身是科班出生的程序员,直接就能明白,这种对象与原型的关系,实际上就是单向链表。
__proto __
之前上面的图里既然画了箭头,这箭头必然是需要存在实际的实现,或者说有个名字来指代。在JavaScirpt1.2中,就把它命名为了__proto__, 之所以加下划线,本义上是为了将它当做一个隐式伪属性给隐藏起来,但后面浏览器直接实现了可以直接调用,所以后面就被划归到规范里成了实际属性了。
那么此刻的图就可以升级为:
所以完全可以将__proto__理解单向链表里的next。如果在内存中的实际情况,它们俩实际保存都是引用地址。
prototype
这里说到的prototype特指的是函数的prototype。
对于函数foo来说,foo存在__proto__, 证明了它本身也是一个对象。并且它的原型是Function.prototype。
而foo中也存在prototype,这个prototype是为了当存在foo变成构造函数时,通过它而产生的实例对象的原型将会指向这个prototype。
所以它是之后对象实例的原型对象,而不是函数foo的原型对象。 一定要把这二者区分清楚。
也就是当把一个函数当成正常函数调用时,完全可以把它的prototype当做不存在。它只有在函数作为构造函数时才产生效果。
同时把一个函数当成对象时,对它进行处理的原型指向也是通过__proto__,也依旧跟prototype没有关系。
当且仅当一个函数作为构造函数使用时,它的prototype将会作为它所产生的实例对象的原型对象。
原型链
在上面已经提及,对象和对象通过隐式属性__proto__连接最后会形成一个链条,就是所谓的原型链。原型链就是一条单向链表。
原型链作用主要有两点,
第一个点就是作为对象的关联,每个对象都必然存在自身的唯一的原型对象,可以通过原型链来查找。第二个点就是作为对象的属性访问的路径,当我们需要访问一个对象的属性时,是存在可能沿着原型链一路查找上去直至返回结果或者返回undefined。这实际上就是链表的遍历。
理论上的原型链就是如此,但实际在实现时例如V8引擎对于原型链的实现并不是将链直接作用在对象上,而是还存在一个Maps用于对象的优化,然后在Maps上连接原型。
对于JavaScript中的对象来说,可能会存在一个构造函数生成了多个对象实例的情况,这些对象具有完全相同的属性,但可能属性值不同。所以引擎对于对象的优化上,会将这类对象抽出一个形状,用于保存属性名和特性,而在对象中存储相对应的值即可。
const foo = {a: 1, b: 2, c: {d: 9}}
const bar = {a: 3, b: 4, c: {d: 10}}
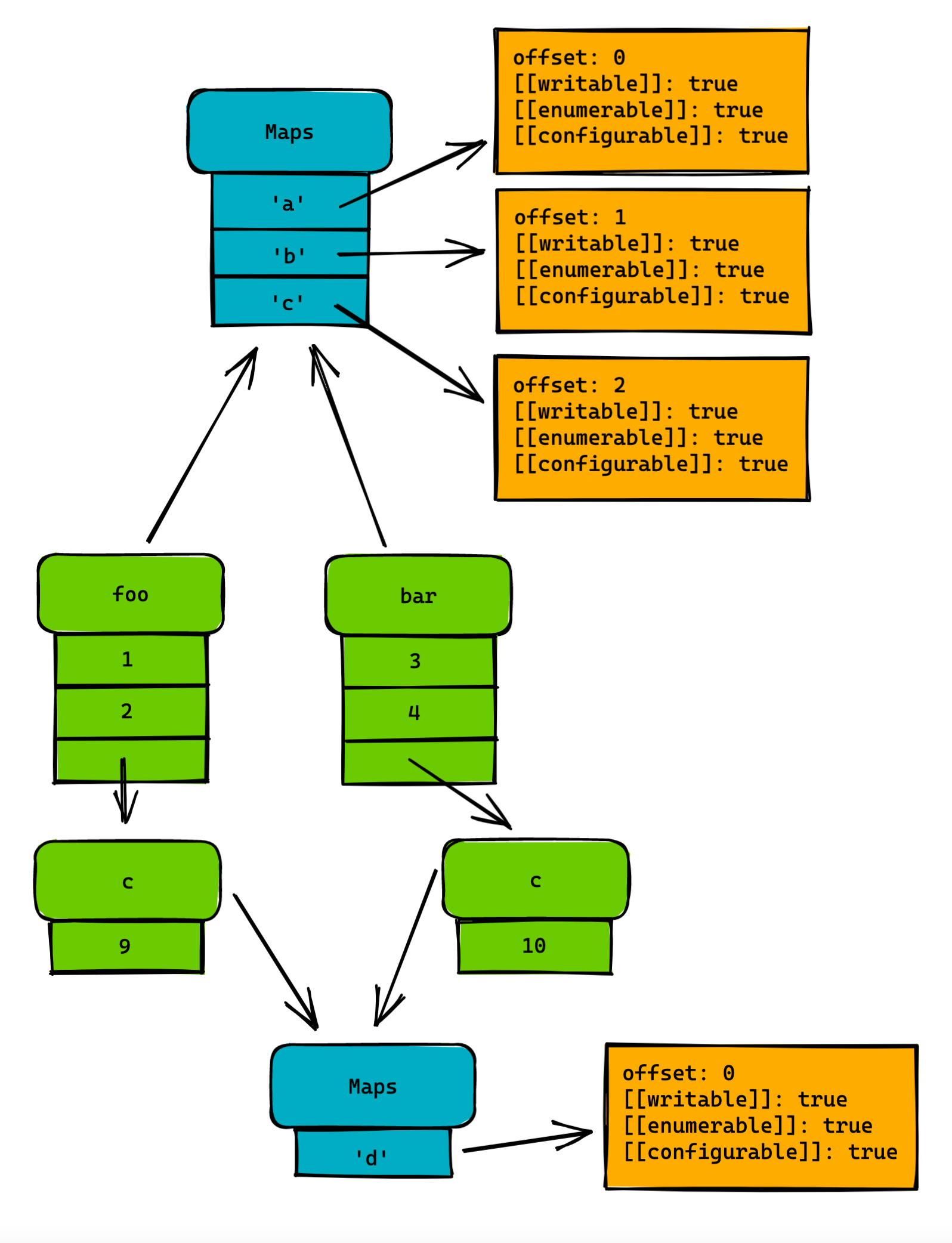
图中绿色的代表对象Object,蓝色代表形状Maps, 橙色代表保存的对象特性。可以看到,假设现在需要访问foo.a的值,对于引擎来说是先去查找foo的Maps找到'a'里储存的偏移量offset为0,然后到foo对象里取出偏移量为0的值也就是1。
这种优化可以省去大量重复属性名在内存中的保存,节省了内存。
现在开始加入原型链的部分,将foo作为bar的原型对象。
const foo = {
x: 1,
getX: function() {
return this.x
}
}
const bar = {x: 2}
Object.setPrototypeOf(bar, foo)
const value = bar.getX()
此刻画出的图应该是bar通过__proto__指向foo,foo和bar都有各自的Maps,其中foo的第二个属性恰好是个函数getX。
那么当代码到了最后得到value的值时,实际上是执行了三步:
- bar对象查找自身Maps形状中不存在getX
- 通过原型链向上查找到自身的原型foo
- 在原型foo的Maps中找到了getX, 获取到偏移量offset为1,则在foo偏移为1处找到函数getX
对于这种常见的操作来说,相当于每次都需要检查对象一次(Maps),然后对对象的原型检查2次 (找到原型与Maps),如果涉及的原型链足够长,那么就是1+2N的查询次数。
对于遍历Maps的操作是不能省的,所以只有在找原型这里进行优化。将找原型与Maps进行合并,通过对象的Maps找到自身的原型,当自身原型如果有修改时,也会更新成另一个新的Maps,保证既能查找属性,又保证一定能连接到原型上。
所以图中的表示就修改为:
此时,对于bar.getX()这样的操作来说,操作的步骤就节省为了1+N的次数上。并且从图上也可以得知, 原型链的连接就发生了变化,不在是bar直接指向foo,而是bar的Maps指向foo。印证了最初说的原型链的实现中,其实是通过Maps来进行连接,而不直接作用在对象与对象之间。
假设此刻代码又发生了修改:
const foo = {
x: 1,
getX: function() {
return this.x
}
}
const bar = {x: 2}
Object.setPrototypeOf(bar, foo)
const baz = {
x: 3,
getX: function() {
return this.x * 3
}
}
Object.setPrototypeOf(bar, baz)
const value = bar.getX()
图中的变化就是:bar的Maps会更新成新的一个,并且指向新的原型baz。
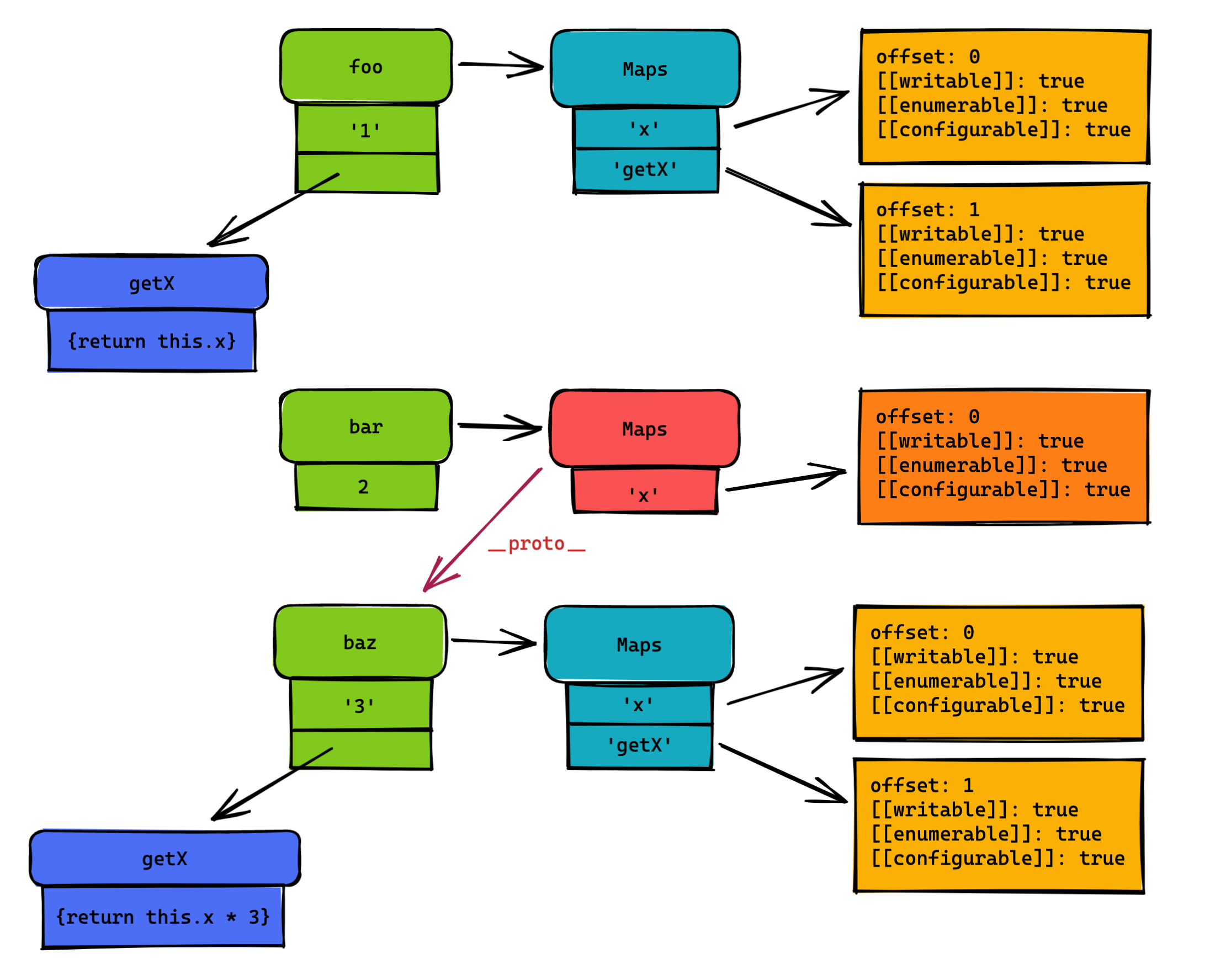
其实之后v8引擎还对查询做了更多的优化,将检查次数从1+N再压缩到常量级。不过这就不属于解释原型链的范畴了,就像图中baz和foo对象虽然属性完全相同,但他们不会被合并成一个Maps,因为baz此刻为原型对象,是单独拥有一个Maps,方便后续的优化。
在原型链这块上,只需要理解,实际上原型链的底层实现里,并不是对象指向到对象的即可。 以及如非必要,不要去修改原型上的内容。会导致性能下降。
本质
其实对于原型来说,它最最最本质的内容就是对象与对象。之所以在最初使用new创建对象,而不是直接用对象创建对象,主要是为了看起来像Java。甚至之后ES6里使语法糖包裹的class语法,本质上也是为了看起来像Java,而隐藏原型。
因而对于最基础的掌握来说,确实就是要明白,JavaScript对象是怎么创建出来的,对象和对象之间的关联是什么。
对此我推荐阅读一下 深入理解 JavaScript 原型 这篇文章,尤其从第五点之后的下半段篇幅,是对原型之外的扩展,而不仅只局限在js原型上。能读懂的话受益匪浅。
