

Scikit Learn决策树简介
这是一个关于Scikit learn决策树的概要。基本上,决策树属于监督学习方法,或者我们可以说,非参数方法被用于数据的回归和分类。决策树的主要目的是通过应用简单的决策规则来创建目标数据集的预测模型。通常情况下,决策树内有两个主要实体,如根和子,或者我们可以说是叶子,我们在那里得到我们想要的最终结果。
Scikit Learn决策树的概述
决策树是最经常和最普遍使用的定向人工智能计算之一,可以执行复发和分组任务。决策树计算背后的本能是直截了当的,但同样也是非常强大的。
对于数据集中的每一个质量,选择树计算都会构建一个中心,其中主要特征被设置在根中心。为了评估,我们从根中心开始,沿着符合我们的条件或 "选择 "的比较中心,顺着树的方向努力。这个循环一直持续到到达一个叶子中心,其中包含预测或选择树的结果。
这可能从一开始就听起来像一片混乱,然而你可能不明白的是,你一直在利用选择树来解决你的整个存在的选择而不知道。考虑一个情况,一个人要求你把你的车借给他们一天,你需要就是否借给他们车辆做出选择。有几个因素有助于决定你的选择,其中一些已经记录在下面。
- 这个人是一个亲爱的伙伴还是仅仅是一个同事?如果这个人只是一个同事,请拒绝这个请求;如果这个人是一个伙伴,请进入下一个阶段。
- 要求提供车辆的人是否有趣?假设是这种情况,就把车借给他们,否则就进入下一阶段
- 他们上次归还车辆时,车辆是否受到伤害?如果确实如此,拒绝招揽;如果没有,就把车辆借给他们。
主要启示
- 通过使用决策树,我们可以进行分类和回归的预测。
- 训练算法所需的时间非常少
- 与其他分类算法相比,决策树实施起来非常快速和高效。
- 它还可以帮助我们按照我们的要求对非线性数据进行分类。
Scikit Learn决策树的分类
决策树能够执行多类分类,所以我们需要使用DecisionTreeClassifier。基本上,这个分类器从两个不同的数组中接收输入,例如,A和B,这里的数组A只不过是用来保存训练样本的稀疏形状,而B只不过是用于类别标签的整数值。
首先,我们需要导入所有需要的库,如下所示:
代码
from sklearn.datasets import load_iris
from sklearn import tree
之后,我们需要根据我们的要求导入或加载数据集,这里我们加载的是Iris数据集。接下来,我们需要在dataset.shape的帮助下对数据进行分析。
例子
让我们考虑一个虹膜数据集的例子,这里我们尝试从虹膜数据集中构建树,如下所示。
代码
from sklearn.datasets import load_iris
from sklearn import tree
iriss = load_iris()
X, y = iriss.data, iriss.target
cl = tree.DecisionTreeClassifier()
clf = cl.fit(X, y)
print(clf)
result = tree.plot_tree(clf)
print(result)
解释
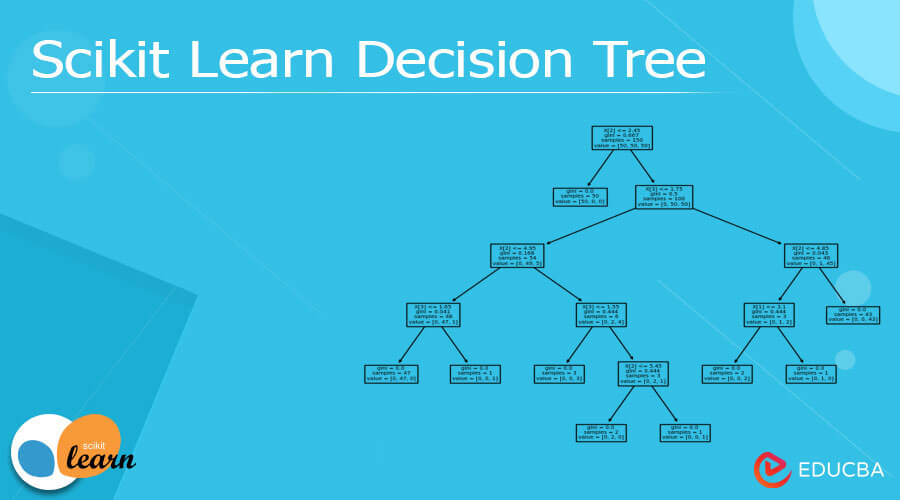
从上面的例子中,首先,我们需要导入虹膜数据集以及sklearn树包,如图所示,之后我们使用DecisionTreeClassifier方法和plot.tree函数,如上面的代码所示。执行后,我们得到如下结果,如下面的截图所示。
Scikit Learn 决策树回归
基本上,决策回归突出了一个项目,并在构建树的过程中训练了一个模型,以预见未来的信息,从而提供重要的不间断结果。持续的结果意味着结果不是离散的,也就是说,它不是仅仅由一组离散的、已知的数字或值来解决。为了实现,我们需要遵循以下几个步骤:
- 首先,我们需要导入所有需要的库
- 第二步,我们需要初始化数据集并打印它。
- 第三步,我们需要选择1个数据集的所有行和列。
- 在下一步,我们需要选择两个数据集的所有行和列。
- 现在拟合数据集的决策回归。
- 在下一步,我们需要对数值进行预测并查看结果。
例子
代码
from sklearn.datasets import load_iris
from sklearn import tree
iriss = load_iris()
X, y = iriss.data, iriss.target
cl = tree.DecisionTreeRegressor()
clf = cl.fit(X, y)
print(clf)
result = tree.plot_tree(clf)
print(result)
解释
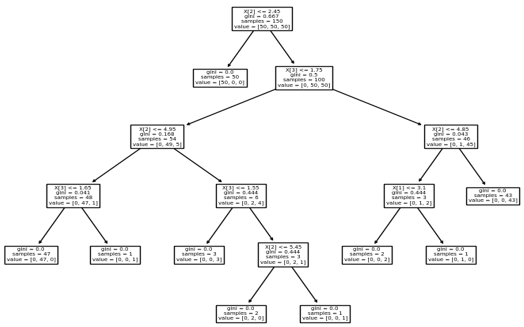
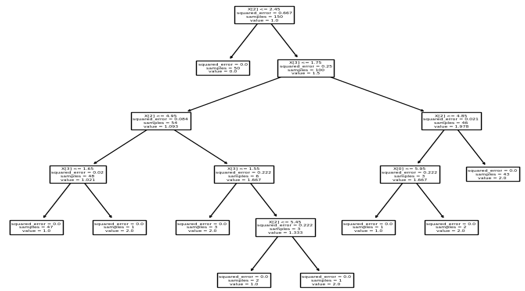
最终结果显示在下面的截图中:
参数
- 准则: 用来确定分割数据集的质量
- 分割器:它用于定义哪种策略最适合从树上分割每个节点。
- max_depth: 通过使用这个参数,我们可以定义树的最大长度。
- min_samples_split: 通过使用这个参数,我们可以定义最小样本的数量。
- min_samples_leaf: 通过使用这个参数,我们可以定义叶子节点的最小样本数。
- max_features: 当我们想获得最佳分割时,我们可以使用这个参数来定义特征的数量。
- random_state: 这个参数用来显示用于洗数据的随机数,它为用户提供不同的选项。
它还提供不同的参数,如max_leaf_nodes、min_impurity_decrease、min_impurity_split和class_weight。
常见问题
1.哪种算法是用来创建决策树的?
**答:**实际上,它属于监督学习算法,所以基本上它使用CART算法,另一方面,对于分裂,它使用Gini和熵。
2.什么是决策树?
答: 基本上,树是一种基于不同条件的机器学习算法。通常情况下,决策树由叶子节点和根节点组成,叶子节点我们可以从根节点创建,而所有的节点我们都是在不同参数的帮助下创建的,如基尼指数、熵等。
3.什么是不同类型的决策树算法?
答: 基本上有不同类型的决策树算法,如ID3、C4.5、C5.0和CART。
总结
在这篇文章中,我们试图探索Scikit Learn的决策树。我们已经看到了Scikit Learn线性决策树的基本思想,以及这些Scikit Learn线性决策树的用途和特点。文章的另一个要点是,我们可以看到Scikit Learn决策树的基本实现。
