


Scikit学习聚类的定义
Scikit learn聚类是一种基于scipy的python学习方法,它是在BSD许可下发布的。Scikit learn主要建立在Python上,它依靠numpy进行线性代数和数组的高速运算。Scikit learn聚类技术允许我们找到类似对象的组,这些对象与其他对象相关,而不是被归入其他组。
scikit learn聚类概述
无标签数据的聚类是通过sklearn.cluster模块进行的。聚类算法有两个变体,一个是在训练数据上实现拟合方法来学习聚类的类,另一个是在训练数据中给出的函数,该函数返回整数标签数组以对应不同的聚类。训练数据的类标签可以在标签属性中找到。
Scikit主要建立在Python上,它在很大程度上依赖于numpy的高速阵列操作。围绕LIBSVM的python包装器将实现对逻辑回归和向量机的支持。使用python实例是不可能实现这种方法的。许多其他的python库,如matplotlib、pandas和numpy都能很好地与scikit learn进行集群。
scikit是一种无监督的ML方法,被用来检测数据样本之间的关联模式和相似性。这些样本根据高度相似的特征被聚类成组。聚类的意义在于,它将确保在未标记的数据下进行分组。聚类被定义为一种将数据点分类到不同群组的方法,而这些群组是基于相似性的。
重要启示
- scikit learn聚类方法是无监督的ML方法之一。它被用来寻找关系模式。
- scikit库包含sklearn.cluster,它被用来对未标记的数据进行聚类。scikit learn有多种聚类方法可用。
方法
scikit库包含一个叫做sklearn cluster的函数,它被用来对未标记的数据进行分类。下面的方法显示scikit learn的聚类方法如下:
- 平均值移动这被用来寻找平滑的样本密度中的斑点。它将通过把数据点移到含有较高密度的聚类中来把数据点分配到聚类中。它将自动设置聚类的数量,而不是依赖任何参数。
- KMeansKMeans中心点的计算和迭代,直到我们没有找到最佳中心点。它将需要预设的聚类规格的数量。这种算法的主要概念是,聚类数据是减少惯性标准,这是将样本分为相等变异的组数。
- 层次聚类-- 这种算法将通过连续合并聚类来创建嵌套聚类。树状图或树状图将代表聚类的层次结构。
- BIRCH-- 这代表了平衡迭代还原聚类和层次结构。这是一个用于对庞大的数据集进行分层聚类的工具。根据给定的数据,它将创建称为CFT的树。
- 谱系聚类-- 这种聚类方法将通过使用相似性矩阵的特征值或谱系来执行较少数量的维度降低。当有多个聚类时,不建议使用这种方法。
- 亲和传播-- 在样本的不同对之间的信息传递理念被使用,直到收敛。这没有必要在运行算法之前提供集群的数量。
- 光学-- 它将代表秩序点,用于识别集群的结构。在空间数据中,这种技术是寻找基于密度的聚类。这种集群的核心逻辑类似于DBSCAN。在组织数据库中的点时,如它将成为最接近的邻居。
- DBSCAN-- 它不过是基于密度的空间聚类应用,通过使用噪声,它是一种基于直觉概念的方法。它将说明集群的密度比那些密集的区域要低。这种聚类是通过使用DBSCAN模块进行的。
参数
下面是scikit聚类的参数。这些参数是基于KMeans聚类法的:
- n_clusters这个参数的数据类型是int,默认值是8。 这将定义所形成的聚类的数量。
- Init这个参数的默认值是k-means++。这个参数用于方法的初始化。
- n_init这个参数的数据类型是int,默认值是10。这个参数定义了算法的运行次数。
- max_iter这个参数的数据类型是int,默认值是300。它将定义算法的最大迭代次数。
- tol这个参数的数据类型是float,默认值是1e-4。这将定义关于不同集群的forbenius norm的相对公差。
- Verbose这个参数的数据类型是int,默认值是0。 这个参数定义了粗略的模式。
- random_state这个参数的数据类型是int,默认值是无。这个参数决定了随机数的生成。
- copy_x如果这个参数为真,那么原始数据不会被修改。
- Algorithm这个参数的默认值是llyod。自动和完整的值已被废弃,并从scikit learn 1.3的版本中删除。
Scikit Learn聚类的例子
下面是scikit learn聚类的例子。我们正在对数字数据集应用KMeans聚类。这个算法将识别相同的数字。
代码
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
scikit = load_digits()
scikit.data.shape
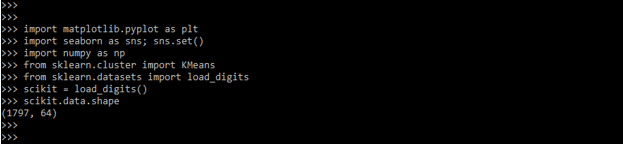
在下面的例子中,我们正在执行KMeans聚类,如下所示。我们定义一个随机状态为零。
代码
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
scikit = KMeans(n_clusters = 12, random_state = 0)
clusters = scikit.fit_predict (digits.data)
scikit.cluster_centers_.shape
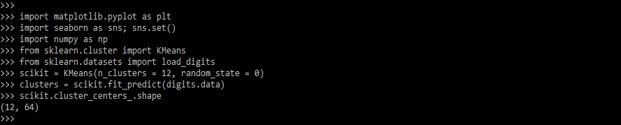
下面的例子显示,scikit learn聚类如下。这个输出显示聚类的数字如下。
**代码 **
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
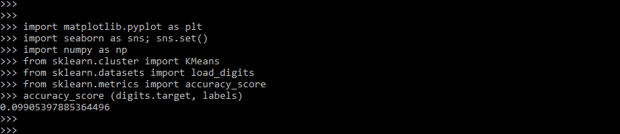
from sklearn.metrics import accuracy_score
accuracy_score (digits.target, labels)
常见问题
1.python中的scikit learn聚类的用途是什么?
Scikit聚类是用来对未标记的数据进行聚类的。有多种类型的方法可用于聚类。
2.在python中使用scikit learn聚类时,我们需要使用哪些库?
在使用seaborn learn聚类时,我们需要使用seaborn、numpy和matplotlib库。
3.3.在Scikit learn聚类中,KMeans聚类的用途是什么?
KMeans算法将计算出中心点,并对其进行迭代,直到找到最佳中心点。
总结
Scikit主要是建立在Python上,它在很大程度上依赖于numpy的高速阵列操作。Scikit学习聚类技术可以让我们找到相似对象的组,这些对象与其他对象相关,而不是进入其他组。
