

DBA可能在不同的环境中定期导入、导出。你可能会收到指定格式的数据,以便将其导入到数据库表中。
源数据可以是各种格式,如JSON、CSV、ORC、TXT、EXCEL、Parquet。Azure SQL数据库是在云中存储结构化数据的一个流行选择。你可能会将这些EXCEL或其他格式的文件存储到Azure blob存储中。你也可以定期从第三方获得数据,定期导入Azure数据库。
有不同的方法将数据导入Azure数据库。在文章《Azure Automation:使用Azure Logic Apps将数据从Azure Blob Storage导入Azure SQL数据库中,我们探讨了使用逻辑应用程序导入数据的问题。
本文将使用Azure数据工厂将数据从Azure SQL数据库填充(导出)到Azure blob存储。
前提条件
-
**Azure数据存储中的目标数据文件。**你应该有一个存储账户和blob容器来存储Azure数据库的数据
- 存储账户:sourcedataimport
- Blob容器:sourcedata
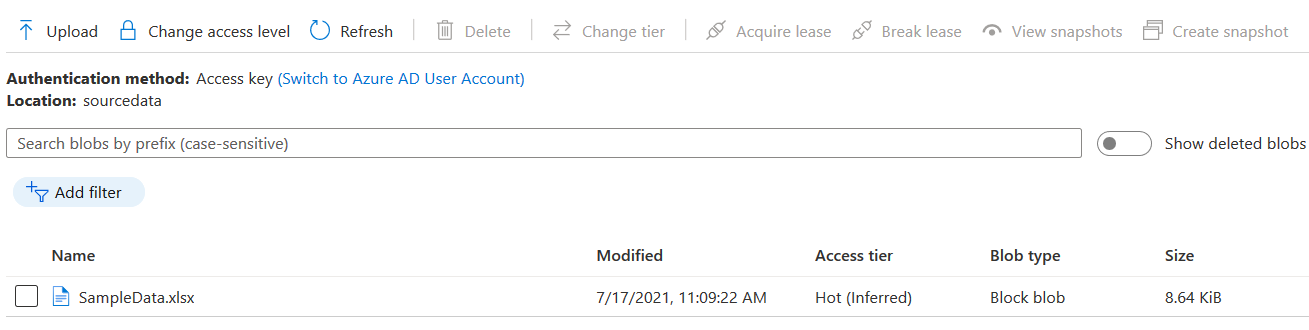
-
源Azure SQL数据库。 你需要一个活跃的Azure数据库来从源文件导入数据
- 服务器名称: azuredemosqldemo.database.windows.net
- 数据库: azuredemodatabase



Azure数据工厂
我们需要一个Azure数据工厂实例来填充数据。为此,请导航到Azure服务中的数据工厂。
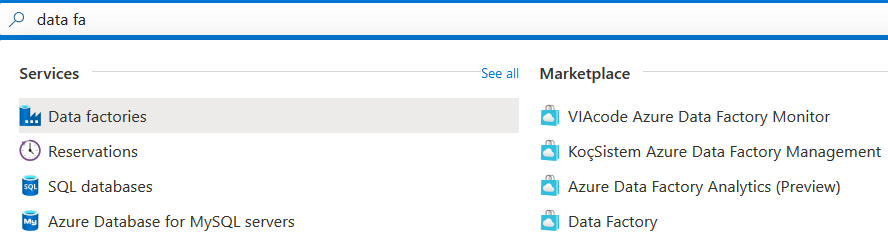
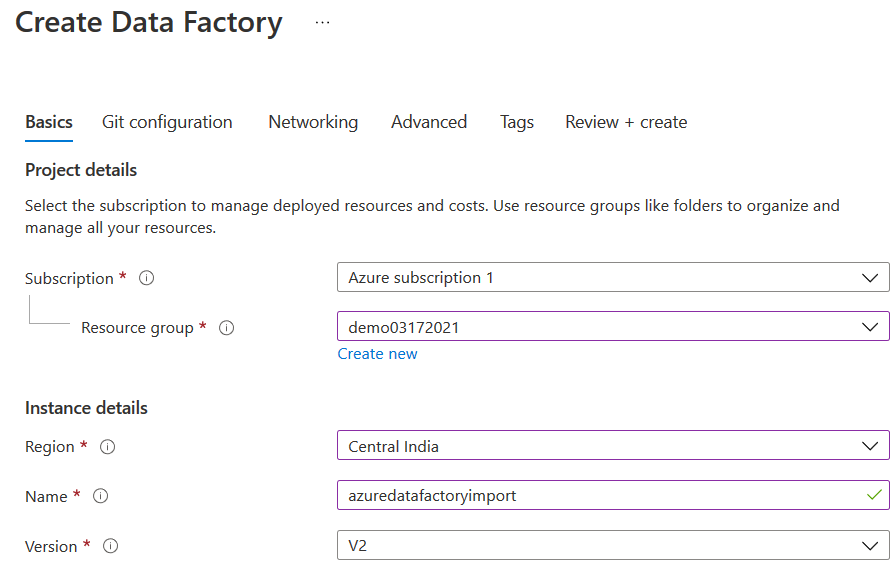
如果你有一个现有的数据工厂实例,你可以使用它。否则,请点击创建。输入资源组、区域、名称和版本。
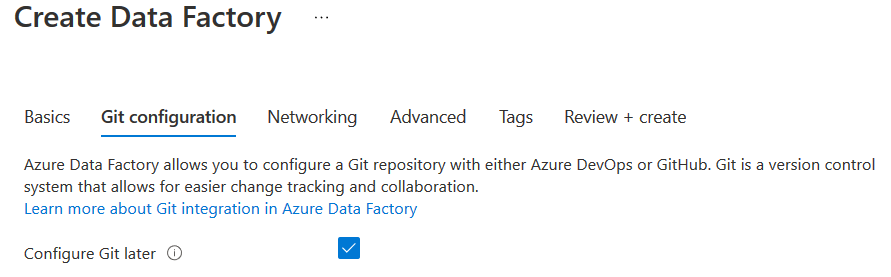
在下一页,Git配置,选择选项 -稍后配置Git。这个选项跳过了用Azure DevOps或GitHub配置Git仓库的过程。
部署Azure Data Factory实例,你会看到以下概览页面。

向下滚动并点击打开Azure Data Factory工作室。
它会打开另一个浏览器标签,并给出以下页面。

Azure数据工厂中的复制数据工具可以从90多个数据源中以最佳方式进行数据导入。
- 它简化了你不了解链接服务、管道、数据集、触发器的数据导入过程。
- 复制数据工具会自动创建数据工厂资源,以便在选定的目的地或汇入地数据存储中复制数据库。
- 你可以在编写的时候验证数据。这有助于在开始时避免任何潜在的错误。
- 它还提供了编辑数据工厂资源的灵活性,以便进行定制和实施复杂的业务逻辑。
点击Ingest瓦片 ,启动复制数据工具。你有两个选项。
- 内置复制任务。内置的复制任务有预先配置的复制任务,它不需要太多的定制。
- **元数据驱动的复制任务(预览)。**元数据驱动任务允许你配置参数化的管道,外部控制表,用于管理大规模的数据拷贝

选择内置复制任务并点击下一步。

在这里,我们需要创建源数据存储和目标数据存储的连接。
源数据存储
- 源类型。从下拉选项中选择Azure SQL数据库
- 连接。点击+新连接,并指定一个连接名称
-
在这里,我们选择Azure订阅,逻辑SQL服务器实例和Azure数据库名称
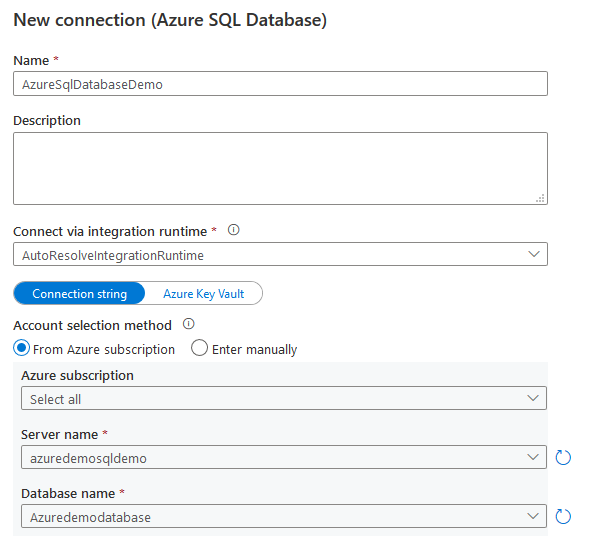
-
选择SQL认证,并输入连接到Azure数据库的用户名和密码
-
点击测试连接以验证与Azure数据库的连接是否成功
-
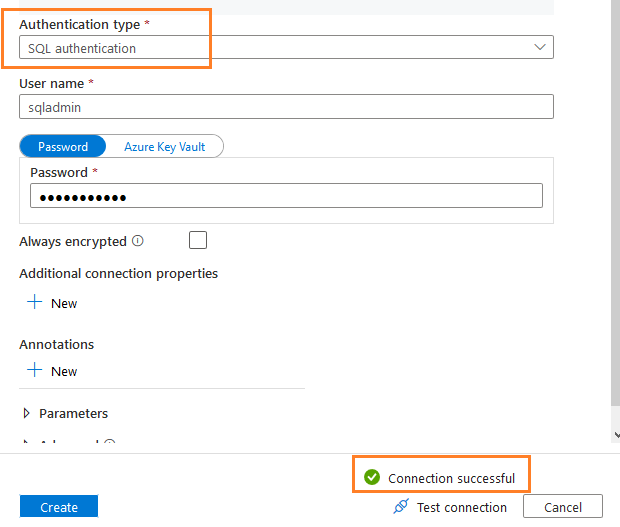
单击 "创建"。在下一页,它列出了现有的数据库表。你可以选择表的数据源。例如,我选择了SalesLT模式中的以下表。

你也可以使用查询从一个表导出数据或连接多个表。

点击 "下一步"。如果你想过滤数据或指定属性,如查询超时、隔离级别、分区选项,请在高级页面中指定。

目标数据存储
我们需要选择Azure blob存储,以便在目标数据存储中以CSV格式导出这些表。

添加一个新的连接,输入连接名称、Azure订阅、存储账户名称。你可以测试该连接,以验证复制数据工具可以连接到目标Azure Blob存储。
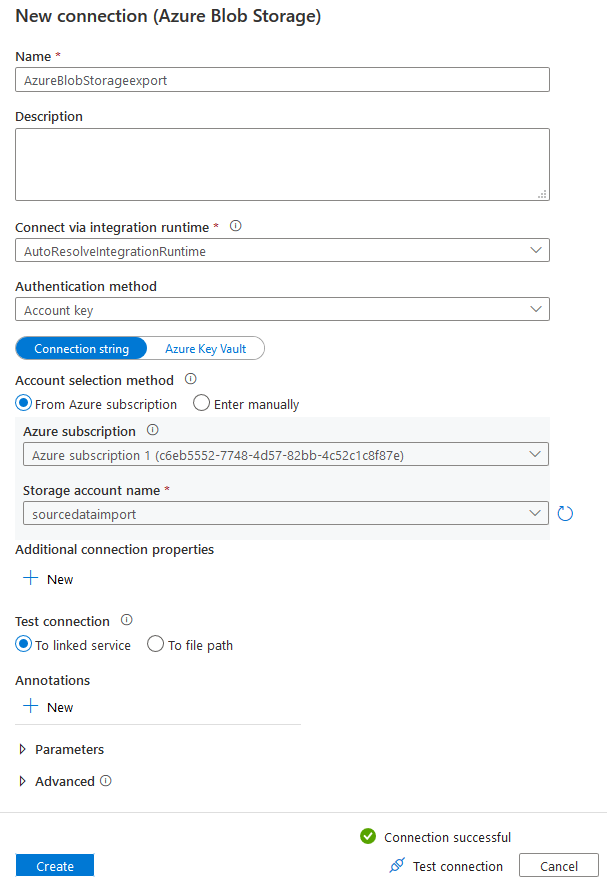
单击 "创建",它将带你回到目标数据存储页面。在这里,你可以看到我们配置的目标类型和连接。在文件夹路径中,浏览到我们要以CSV格式导出表格的blob容器。
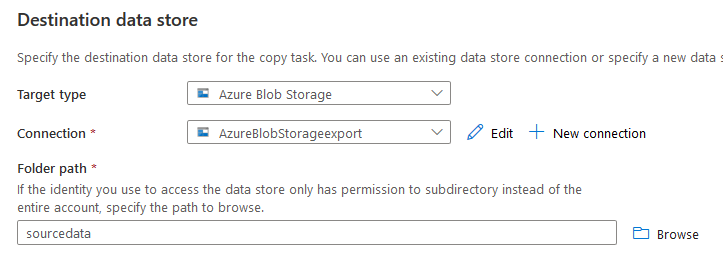
默认情况下,它使用文件名后缀为.txt。根据我们的要求,我把它改为CSV。

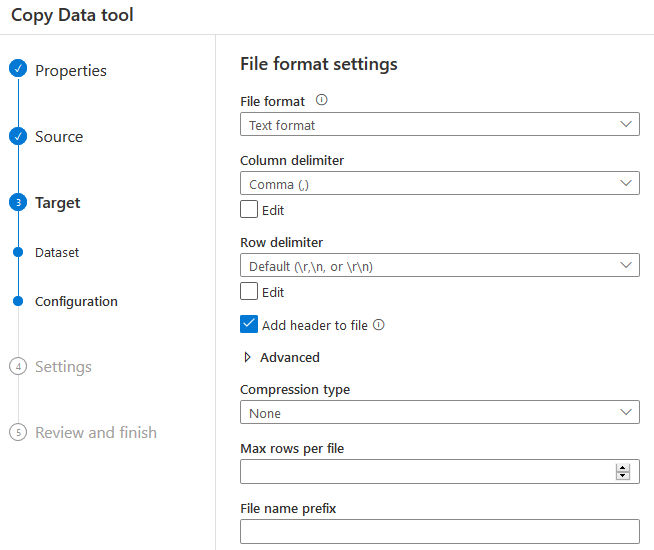
在下一页,你可以配置文件格式设置。可用的选项如下。
- 文件格式(文本格式、AVRO格式、JSON、ORC和Parquet)。
- 列分界符(默认 - 逗号(,))。
- 行定界符
- 在文件中添加标题。要使用第一行作为列标题
- 压缩类型
- 编码
在设置页面,输入任务名称和描述。你可以在这个页面上配置一致性检查、日志记录。 在演示中我们将跳过这些选项。
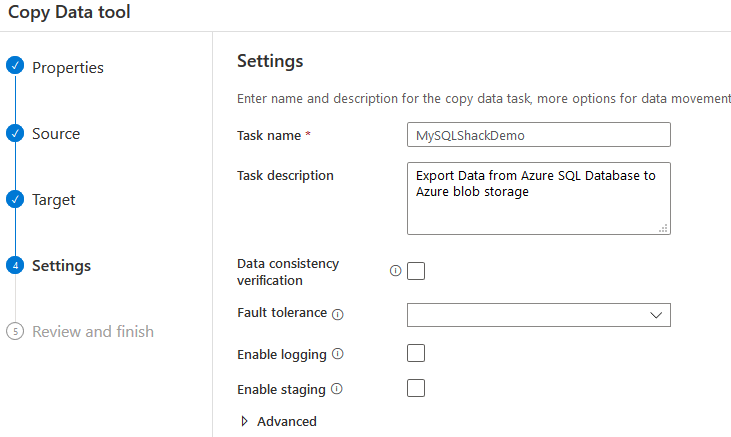
在最后一页,在Azure Data Factory v2的复制数据工具中查看数据流和到目前为止完成的配置。

点击下一步,它就会部署工作流。在最初的步骤中,你会创建一个数据集、管道和它们的验证。

它完成了从Azure数据库的数据导出,并将各个表作为一个单独的CSV文件存储在blob存储中。

你可以到存储账户和blob容器中查看这些导出的表。

你可以点击单个文件,将其下载并打开Microsoft excel来查看其数据。例如,在下面的截图中,我们有SalesLTCustomer.CSV的数据

监控Azure数据工厂中的管道运行
你可以使用ADS仪表板监控当前运行的管道或工作流程。点击作者和管线运行。默认情况下,它显示最近的24个数据。你可以改变过滤器以获得所需的数据。
在下面的截图中,我们看到管道的状态。你也可以用触发的列来区分手动触发和预定触发。

点击管道名称,获得组件的图形视图。

向下滚动,得到活动运行历史。例如,我们将数据从Azure SQL数据库表中导出到Azure blob存储。因此,在活动运行中,它显示了单个表的来源和目的地细节。

要获得进一步的细节,将鼠标指针悬停在任何活动行上。它给出了以下选项。
- 输入
- 输出
- 细节

输入。点击输入选项卡,获得源、目的地和文件格式的JSON数据。

输出
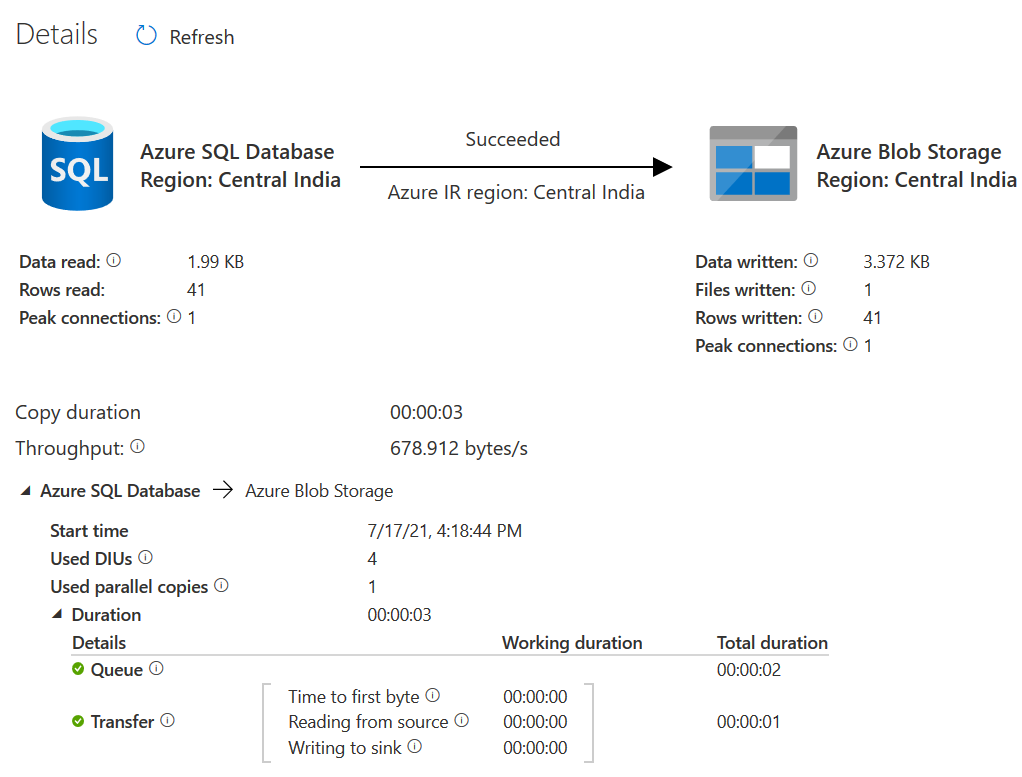
在输出部分,你可以查看信息,如读取的行数、复制的行数、读取的数据、写入的数据、计费时长、吞吐量、Azure SQL数据库的来源和目的地细节。
- ***注意:*关于定价部分的更多细节,可以参考数据工厂的定价

细节。 细节部分以图形方式概述了源、目的地、任务状态、Azure集成服务运行时间、吞吐量、开始时间、结束时间。你可以用这个窗口来查看你从输入和输出选项卡上得到的细节。
你也可以在甘特图中查看活动信息。点击顶部的甘特图,它将表格式的活动日志转换为图形格式。点击图表,显示JSON格式的信息,如下图所示。

总结
本文探讨了Azure Data Factory复制数据工具,将Azure SQL数据库数据导出为CSV格式。 它将这些CSV文件存储到Azure blob存储中。这个复制数据工具有90多个内置容器,可以在管道项目中配置和使用,用于数据传输或转换。你可以安排管道在指定的时间和频率自动执行它。

你好!我是Rajendra Gupta,数据库专家和架构师,帮助企业快速有效地实施Microsoft SQL Server、Azure、Couchbase、AWS解决方案,修复相关问题,以及性能调优,拥有超过14年的经验。
我是《DP-300 Administering Relational Database on Microsoft Azure》一书的作者。我在MSSQLTips、SQLShack、Quest、CodingSight和SeveralNines上发表了650多篇技术文章。
我是最大的关于单一主题的免费在线文章集之一的创建者,他的50篇关于SQL ServerAlways On Availability Groups的系列文章。
基于我对SQL Server社区的贡献,我在2019年、2020年和2021年连续被评为SQLShack著名的年度最佳作者(排名第二),并在2020年获得MSSQLTIPS的冠军奖。
个人博客:
www.dbblogger.comI,我一直对新的挑战感兴趣,所以如果你需要咨询帮助,请联系我[:rajendra.gupta16@gmail.com](mailto:rajendra.gupta16@gmail.com)
