

开启掘金成长之旅!这是我参与「掘金日新计划 · 12 月更文挑战」的第9天,点击查看活动详情
数据挖掘
1.1 什么是数据挖掘
数据挖掘正是借助统计机器学习、深度学习等算法,从大量有噪声的、不完全的、模糊和随机的数据中,提取出隐含在其中的,人们事先不知道的、具有潜在利用价值的信息和知识的过程,从而实现判断和预测的一种技术。
人工智能、机器学习、深度学习
• 机器学习是大数据分析的核心内容。机器 学习解决的是找到将X和Y关联的模型F, 从Data到X的步骤通常是人工完成(特征 工程)。
• 深度学习是机器学习的一部分,其核心是 自动找到对特定任务有效的特征,也即自 动完成Data到X的转换。
• 如果我们的任务Y是模拟人类(自动驾驶、 围棋AlphaGo)的行为,则这类任务称为 人工智能。
机器学习
➢ 机器学习就是用算法解析数据,不断学习,对世界中发生的事做出判断和预测的一项技术。
➢ 机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
➢ 机器学习是对能通过经验自动改进的计算机算法的研究。
➢ 机器学习是用数据或以往的经验,以此优化计算机程序的性能 标准。
“机器学习”只是大数据技术上的一个应用。常用的10大机器学 习(数据挖掘)算法有:决策树、随机森林、逻辑回归、SVM、 朴素贝叶斯、K最近邻算法、K均值算法、Apriori、Adaboost 算法等。
数据挖掘的过程
数据挖掘的只要过程有:
- 定义目标
- 获取数据(常用手段有通过爬虫采集或者下载一些网站发布的数据)、
- 数据探索
- 数据预处理(数据清洗【去掉脏数据】,数据集中【集中】,数据变换【规则化】,数据规约【精简】)
- 挖掘建模(分类,聚类,关联,预测)
- 模型评价与发布
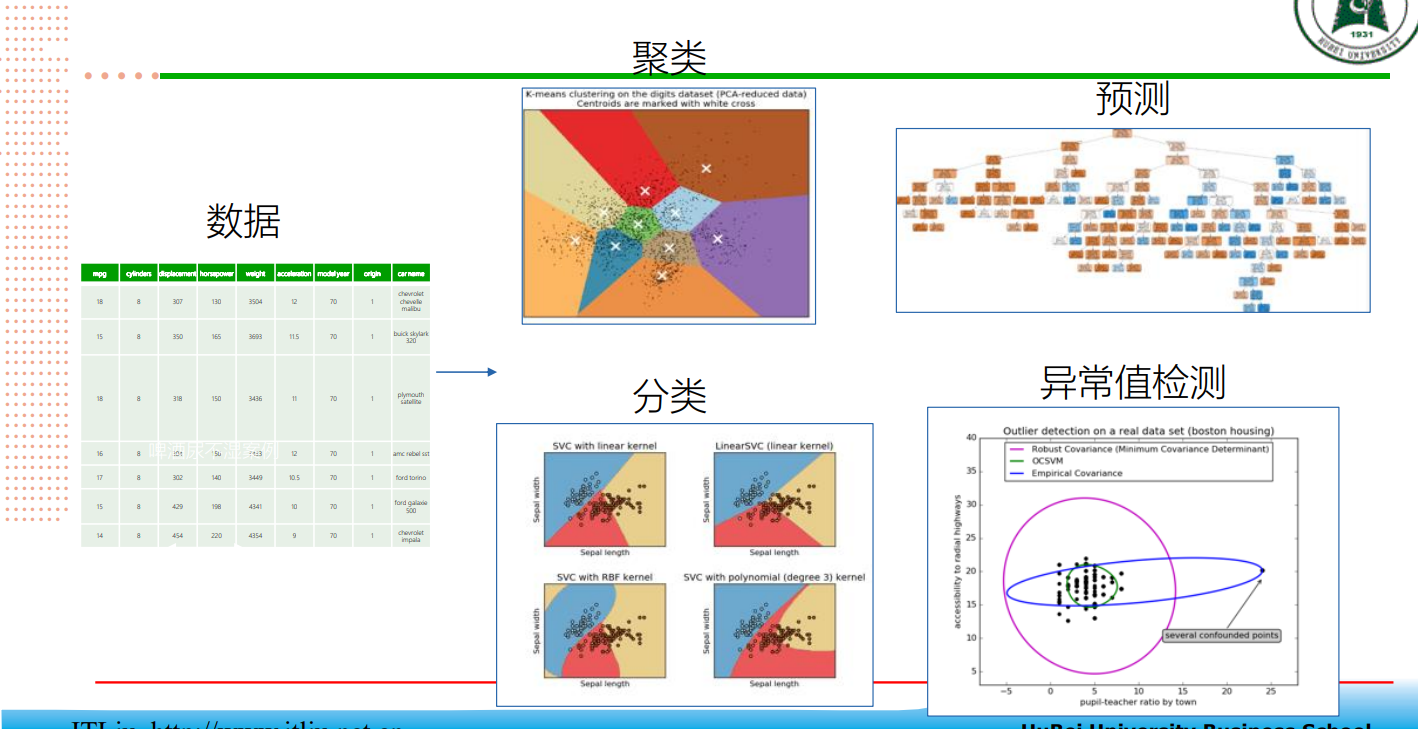
- 数据集:一组样本的集合。
- 样本:数据集的一行。一个样本包 含一个或多个特征,此外还可能包 含一个标签。
- 特征:在进行预测时使用的输入变 量。
训练集:用于训练模型的数据集
测试集:用于测试模型的数据集
模型:建立数据的输入𝒙和输出𝑦之间的映射关系 𝑦 = 𝑓(𝒙)、
损失函数:𝐿( 𝑓(𝒙𝑖), 𝑦𝑖) = (𝑓 (𝒙𝑖) − (𝑦𝑖)) 2
优化目标:
1.2 数据挖掘算法
数据挖掘的算法主要有传统机器学习算法、基于神经网络的深度学习算法、强化学习以及深化强化学习算法等。
- 传统机器学习:方法首先需要对原始数据做特征工程,提取有效的特征
- 深度学习:不需要额外的特征工程,神经网络自主完成特征的提取
- 强化学习:通过环境给出的奖惩来学习,不需要标签。强化学习是指决策的过程,通过过程模拟和观察来不断学习、通过奖惩与惩罚不断提高决策能力
- 深度强化学习:是指运用了神经网络作为参数结构进行优化的强化学习算法
数据挖掘算法根据是否需要标签又为有监督学习算法、无监督学习算法
-
有监督学习:指数据集中样本带有标签,有明确目标
-
典型方法
- 回归模型:线性回归、岭回归、LASSO和回归样条等
- 分类模型:逻辑回归、K近邻、决策树、支持向量机等
-
-
无监督学习:指数据集中的样本没有标签或者学习过程不借助数据集中的标签,典型的有 Meanshift、Kmeans的等聚类算法以及降维、关联规则挖掘等算法
-
典型方法
- 聚类、降维、关联规则挖掘等
-
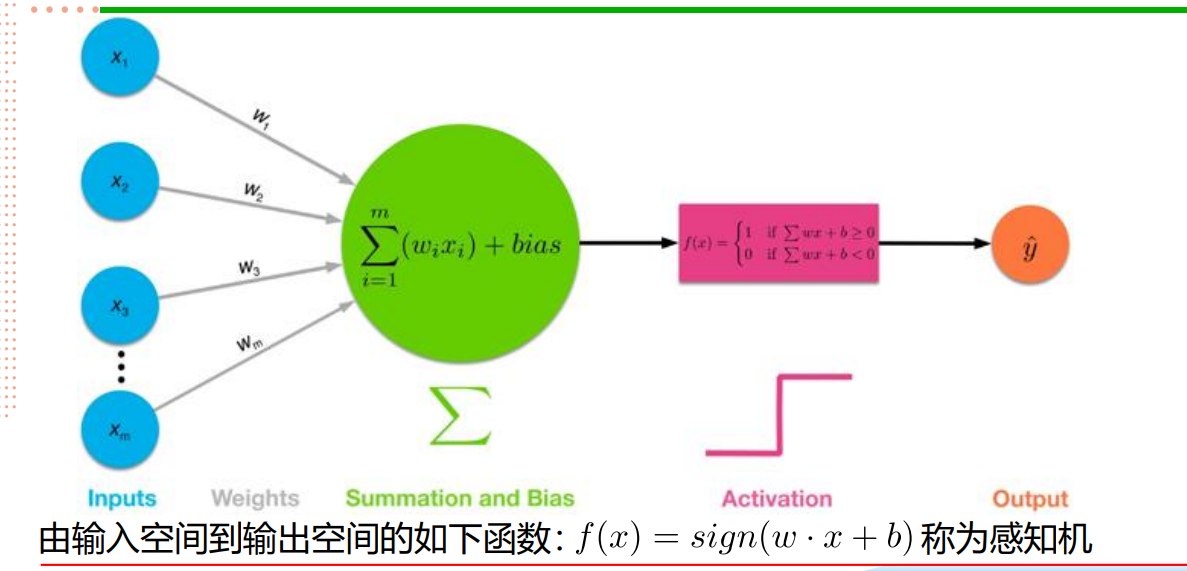
在生物的神经元细胞中,有树突,负责传入外部的感应,即传来的电信号,中间的轴突+髓鞘+施万细胞+郎飞氏结 也可以传输电信号,且电信号的传输是双向的,神经末梢将信号传递给下一个神经细胞。
下面的那一张简图:x1,x2,....xi...xn,是初始传入的数据,w1,w2,....wi,...wn,是参数权重,可以调整,中间的圆圈圈就是核心,负责计算,类似于细胞核,y=...,这个公式就是计算式。
神经网络--神经元与感知机
多层感知机(MLP)
-
多个神经元以全连接层次相连
-
这种网络称为前馈神经网络,也称为多层感知机(MLP)
-
万能逼近原理:MLP能够逼近任何函数
- 函数逼近:𝑦 = 𝐹(𝑥) = 𝑓3(𝑊3, 𝑓2(𝑊2, 𝑓1( 𝑊1, 𝑥 ))
过度拟合问题
模型过于复杂(例如参数过多),导致所选模型对已知数据预测得很好,但对未知数据预测很差。
过拟合的图:泛化误差的走势是先下降后上升,这个是因为过拟合的原因
正则化
- 正则化是模型选择的典型方法
- 在误差函数上加一个正则项,正则项通常为参数向量的范数
- 在训练误差和模型复杂度之间的权衡
检验与模型选择
-
交叉验证:基本想法是重复地使用数据。将数据集随机切分,将切分的数据集组合为训练集和测试集,在此基础上反复进行训练,测试和模型选择。
-
K折交叉验证:
- 随机地将数据切分为𝑘个互不相同 大小相同的子集;
- 每次利用𝑘−1个子集的数据训练模型,余下的数据测试模型;
- 最后选择在𝑘次测评中取平均性能最好的模型。
-
1.3 数据挖掘目的
数据挖掘的主要目的是从已知的大量数据中发现潜在的规律。如通过数据挖掘掌握趋势和模式、做出预测以及求最优解等
不同的数据挖掘目的采用的算法不一样,回归、分类算法的目的是基于训练集数据建立数据的输入 x (特征)和输出 y (标签)之间的映射关系,也就是模型。区别在于分类算法的标签是离散的,而回归算法的标签是连续的。
数据挖掘的过程:
- 确定研究目标
- 获取数据(下载、爬取数据)
- 数据探索(初步了解数据)
- 数据预处理(缺失值、离群值、标准化、编码、离散化)
- 建模:要试一下各种方法,找到一个稍微好一点的模型
- 评价(返回、建模)
- 发布(OK) 。
