

本文将探讨用于将数据从网络源导入Azure SQL数据库的复制数据工具。
简介
假设你需要将数据从CSV文件导入到Azure数据库表中。CSV文件的来源是一个Web URL。通常情况下,我们会在本地目录中下载该文件,然后将数据导入到数据库表中。在《复制数据工具将数据从Azure SQL数据库导出到Azure存储》一文中,我们使用了Azure数据工厂中的复制数据工具,它完成了以下任务。
- 将数据从Azure数据库表中导出到CSV文件中
- 将CSV文件存储到Azure blob存储容器中
复制数据工具包含90多个内置容器,允许你在没有Azure数据工厂实体(链接服务、数据集、管道)专业知识的情况下配置数据加载任务。
前提条件
-
你需要一个用于数据导入的CSV文件的URL。在本文中,我们将参考stats.govt.nz的样本数据集。

-
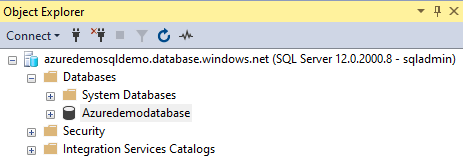
Azure SQL数据库服务器。我们将把CSV文件导入到一个数据库表中。因此,你需要一个Azure数据库。对于这篇文章,我们将使用以下SQL数据库。
-
Azure数据工厂(ADF)V2实例。我们在前面的文章中配置了ADF实例,如下图所示。你可以使用它或使用Azure门户->数据工厂部署一个新的ADF实例。

Azure数据工厂
Azure数据工厂是一个基于云的ETL**(提取-转换-加载**),提供数据驱动的数据转换和移动管道。它包含相互连接的系统,以提供一个端到端的平台。
- 数据摄取。 Azure数据工厂(ADF)有90多个标准连接,用于各种数据源。它包含在一个集中的位置收集数据,以便进行后续处理
- 映射数据流: ADF使用图形界面部署了数据转换。它简化了源和目标任务的配置
- Azure计算。 ADF可以在不部署Azure资源的情况下执行数据驱动的工作流。你可以部署一个ADF服务,并开始部署各种组件和数据整合。
- 数据运营: ADF可以与GitHub和Azure DevOps集成,以简化数据管道的管理。
- 监控。 ADF可以与Azure Monitor、PowerShell、Azure门户健康面板集成。这样一来,你就可以监控脚本和门户的执行进度了
在ADF仪表板上,点击Ingest,启动复制数据工具,进行数据导入和导出。

在本文中,我们将使用内置复制任务。在任务周期中,我们使用默认选项--现在运行一次。

你可以选择时间表或翻滚窗口进行额外的调度配置,如下图所示。

源数据存储的配置
在源数据存储中,选择源类型为HTTP。你可以对HTTP和HTTPS URL使用这个源。

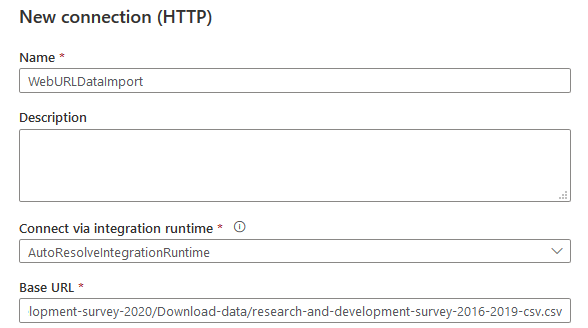
点击新建连接。在新连接(HTTP)窗口中,指定一个名称、描述(可选),并在基础URL部分指定CSV文件的Web URL。
默认情况下,它使用基本认证,要求你输入认证数据源的凭证。 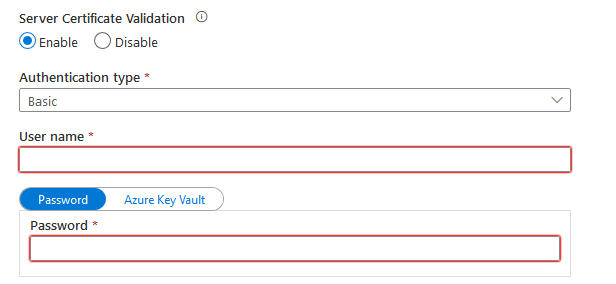
对于Web URL,我们不要求任何证书来访问CSV文件。在创建连接之前,点击测试连接以验证与Web URL的连接。
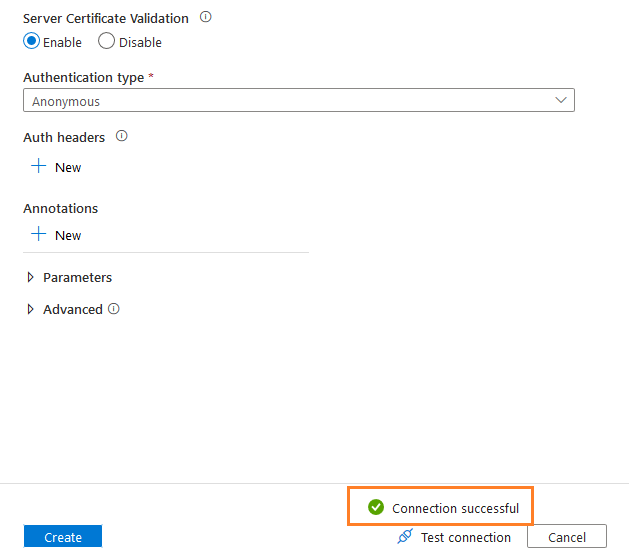
点击 "创建",就会返回到带有基本URL信息的源数据存储页面。
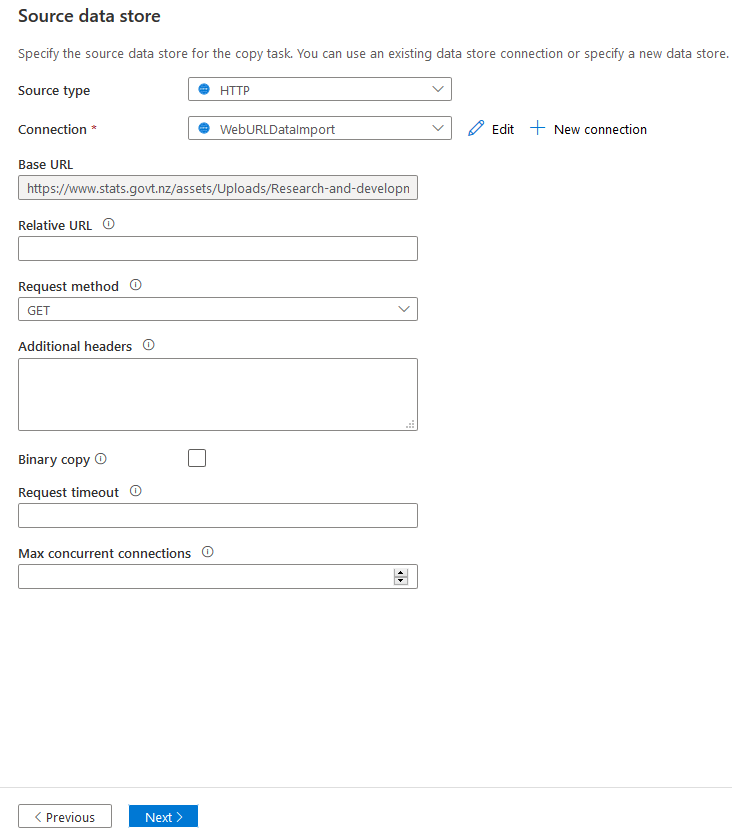
点击 "下一步",它就启动了文件格式设置页面。

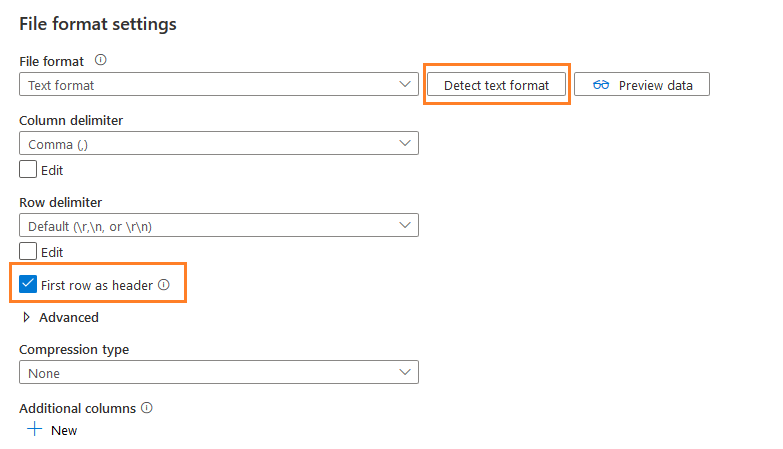
你会得到一个选项--检测文本格式。它自动检测文件格式,列定界符,行定界符。如下图所示,它已经自动选择了选项--第一行作为标题。
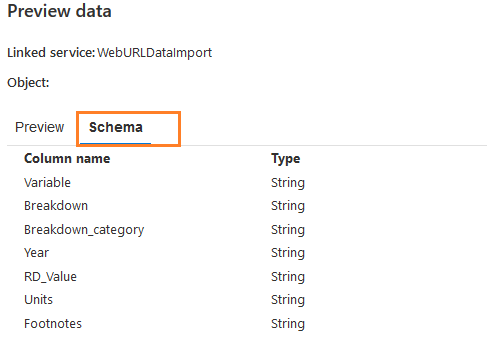
点击选项--预览数据。它打开一个弹出式窗口,显示来自源文件的几行数据。你可以验证数据格式。如果它不正确,你需要修改文件格式设置并再次预览数据。
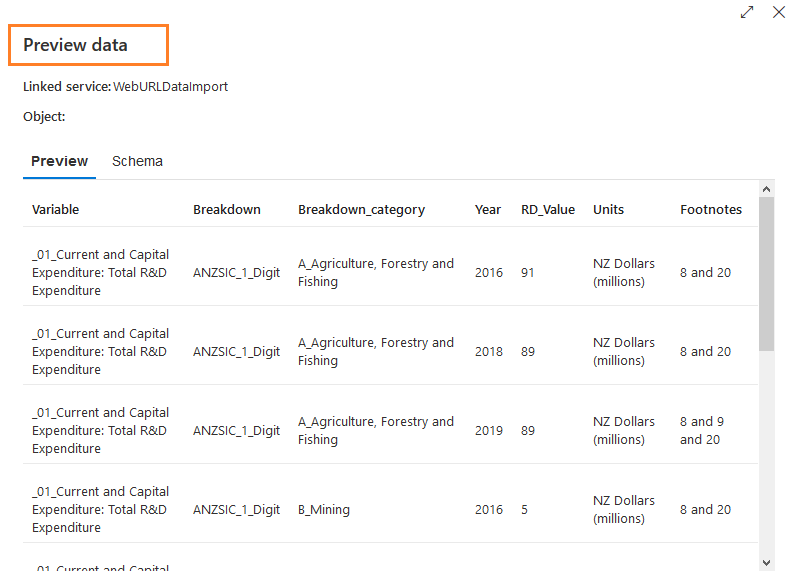
在这个预览数据页面,点击模式,检查源数据的列和它们的类型。如下图所示,它使用的列数据类型是字符串。
目标数据源配置
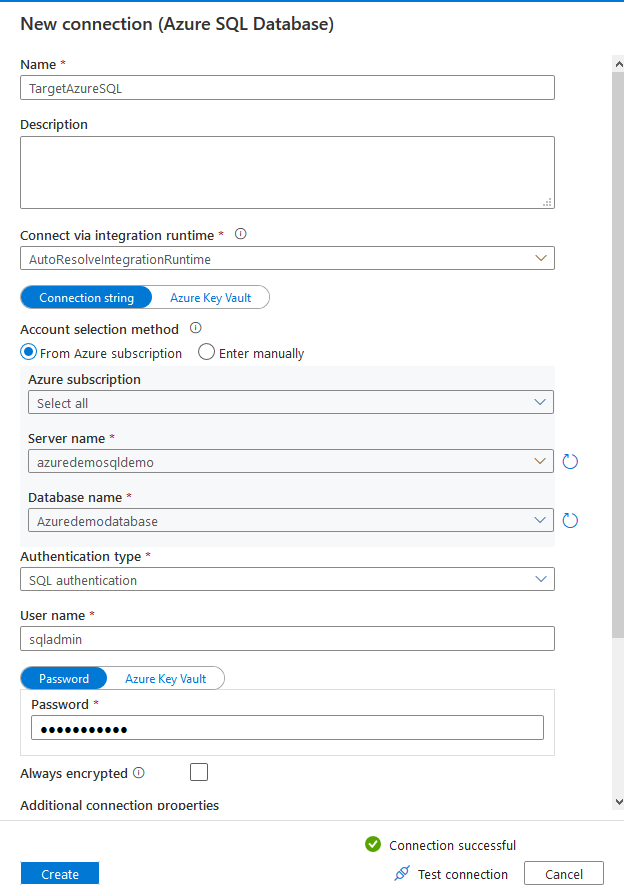
在下一页,从下拉列表中选择目标数据源。对于这篇文章,我们选择Azure SQL数据库。

选择Azure SQL数据库服务器、数据库、认证类型,并输入导入数据的凭证。
一旦你创建了一个目标数据存储连接,它就会显示一个额外的配置,如下图所示。
- 来源。HTTP文件
- 目标:空白

这个工具可以在Azure SQL数据库中为你自动创建SQL表。不过,我建议你事先根据源列及其数据类型来部署表。在这篇文章中,我创建了一个数据类型为varchar的演示表。
CREATE TABLE DemoImport ( 变量 varchar(2000)。 细分 varchar(1000), 细分类别 varchar(2000), 年份 varchar(2000), RD_Value varchar(2000), 单位 varchar(2000), 脚注 varchar(2000) ) |
在你现有的Azure SQL数据库中创建表,并点击选项 -使用现有的表。不要选择选项 -用源模式自动创建一个目标表,而是从下拉列表中选择表。

在这里,我们使用表[dbo].[DemoImport]来导入存储在Web URL中的CSV文件中的数据。

在下一页,验证你的源(CSV)和目标(SQL表)之间的列映射。在类型栏中,它显示了源和目的列的数据类型。

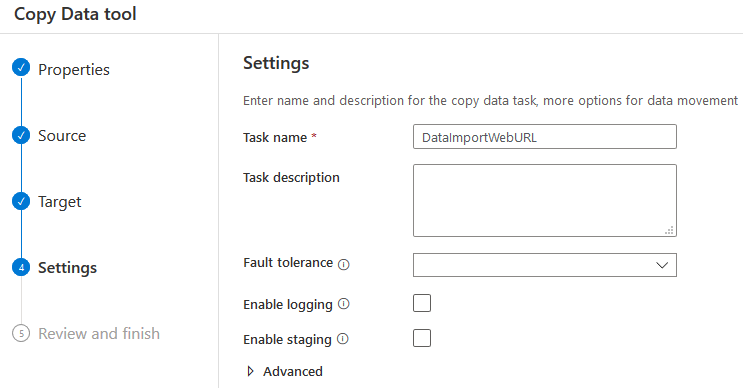
如果有许多映射问题或剩下的列,点击新的映射,从源和目的地选择列。输入配置的复制工具任务的名称。其余的选项,如任务描述、容错、日志,是可选的。
摘要页以图形方式显示源和目的数据源。你可以验证或修改配置,如果有的话。

进一步的步骤是验证复制的运行环境。

它完成以下任务。
- 创建源和目标数据集
- 创建管线
- 创建触发器
- 启动触发器
点击完成,查看管道运行情况。如下图所示,其状态为成功。

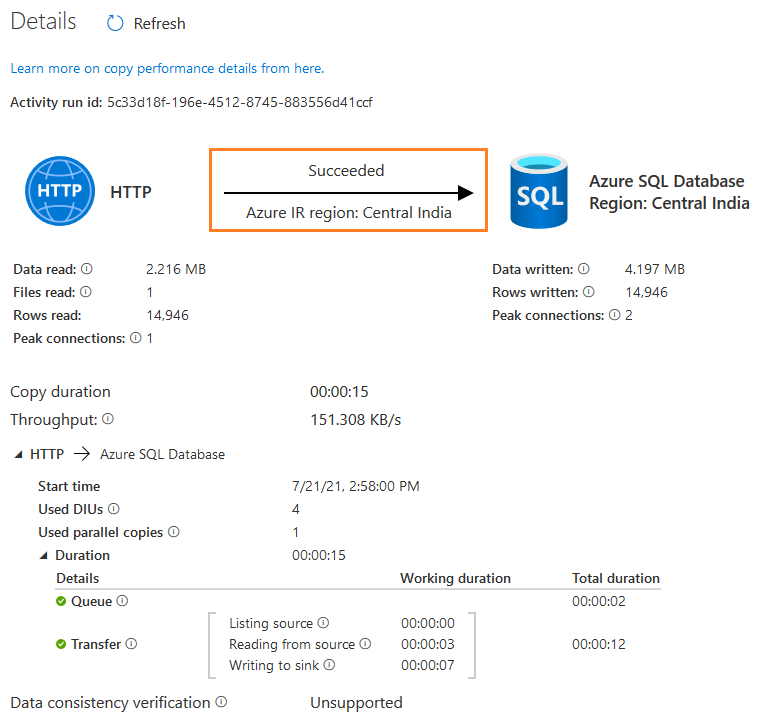
将鼠标悬停在活动运行上,点击详细信息。
 它为监控数据流提供了有用的信息。 捕获的信息如下。
它为监控数据流提供了有用的信息。 捕获的信息如下。
- 读取的数据。从源数据存储中获取的数据总量,包括在这次运行中复制的数据和数据,从上次失败的执行中恢复的数据。
- 读取的文件。从源数据存储中复制的文件总数,包括本次运行中复制的文件和从上次失败的运行中恢复的文件
- 读取的行数
- 源峰值连接。在复制活动运行期间建立到源数据存储的并发连接的峰值数量。
- 写入的数据。写入/提交到水槽的实际数据量。其大小可能与数据读取大小不同,因为它与每个数据存储的数据存储方式有关。
- 写的行数。拷贝到sink的行数。这个指标不适用于按原样复制文件而不进行解析的情况,例如,当源和汇的数据集是二进制格式类型或其他具有相同设置的格式类型时
- 目标峰值连接。在复制活动运行期间建立到汇入点数据存储的并发连接的峰值数量。
- 复制持续时间
- 吞吐量(KB/秒)
- 已用DIU - 拷贝期间的有效数据整合单位
- used parallel copies:复制期间的有效并行副本
- 从源头读取的工作时间 - 从源数据存储中检索数据所花费的时间量
- 写入水槽--将数据写入水槽数据存储的时间量
你可以连接到Azure SQL数据库,验证行数(14,946),并查看导入的数据。

总结
本文探讨了Azure数据工厂的复制数据工具,用于使用Web源将数据导入Azure SQL数据库。ADS为数据导入、导出提供了快速的解决方案,具有各种数据源和可定制的管道。它消除了将文件下载到本地目录并导入的要求。

你好!我是Rajendra Gupta,数据库专家和架构师,帮助企业快速有效地实施Microsoft SQL Server、Azure、Couchbase、AWS解决方案,修复相关问题,并以超过14年的经验进行性能调试。
我是《DP-300 Administering Relational Database on Microsoft Azure》一书的作者。我在MSSQLTips、SQLShack、Quest、CodingSight和SeveralNines上发表了650多篇技术文章。
我是最大的关于单一主题的免费在线文章集之一的创建者,他的50篇关于SQL ServerAlways On Availability Groups的系列文章。
基于我对SQL Server社区的贡献,我在2019年、2020年和2021年连续被评为SQLShack著名的年度最佳作者(排名第二),并在2020年获得MSSQLTIPS的冠军奖。
个人博客:
www.dbblogger.comI,我一直对新的挑战感兴趣,所以如果你需要咨询帮助,请联系我[:rajendra.gupta16@gmail.com](mailto:rajendra.gupta16@gmail.com)
