

本文将探讨Azure Data Studio中的参数化SQL笔记本。
简介
Azure Data Studio中的SQL笔记本或Jupyter笔记本有很好的功能,包括单个文件中的代码和文本。你可以把它连接到所需的连接并执行它。你可以查看集成到SQL笔记本的显示查询结果。因此,你不必迁移不同的控制台。它是一个开源的应用程序,包含实时代码、方程式、可视化和文本。
Azure Data Studio笔记本有不同的内核,如SQL Server、Python、Pyshark、PowerShell、Spark |R、Spark |Scala。
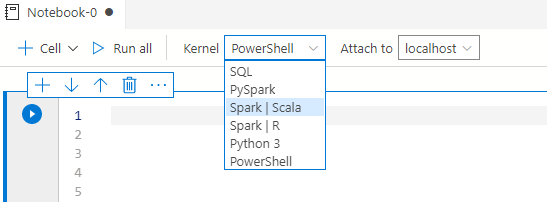
- SQL服务器。为关系型数据库编写T-SQL查询。
- Python内核。为本地开发编写Python脚本
- Spark内核。使用Spark编写Scala和R代码
- PySpark3和PySpark Kernel。要使用spark计算编写Python代码
Azure Data Studio包括对Python、PySpark、PowerShell和.Net交互式内核的参数化支持。 本文探讨了如何用笔记本来使用这些参数化。
前提条件
-
安装最新版本的Azure Data Studio。在本文中,我使用ADS1.30 June 2021版本。
使用Papermill的参数化笔记本
在本节中,我们将使用Python内核创建一个参数化笔记本。启动Azure Data Studio,进入文件->新建笔记本。
在内核中,选择Python 3和Attach to as localhost,如下图所示。

如果Python没有为ADS安装,或者版本较旧,它会提示你安装或升级其版本。 你可以按照编写的说明,重新启动ADS。
点击+Code,使用下面的脚本在Python中安装Papermill包。它在你的ADS中安装了papermill包。
import sys
!{sys.executable} -m pip install papermill --no-cache-dir --upgrade
它下载并安装了papermill包,如下图所示。
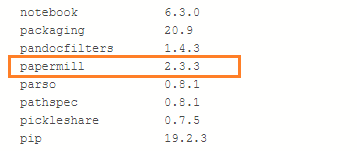
你可以用下面的代码来验证其版本。它在我的环境中的版本是2.3.3
import sys
!{sys.executable} -m pip list
现在,我们可以将现有的单元格转换为参数化单元格。为了演示,我写了一段示例代码,声明了两个参数X和Y的值。
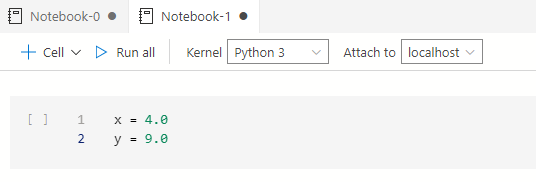
点击eclipse,你可以找到一个选项列表。点击选项--制作参数化单元格。
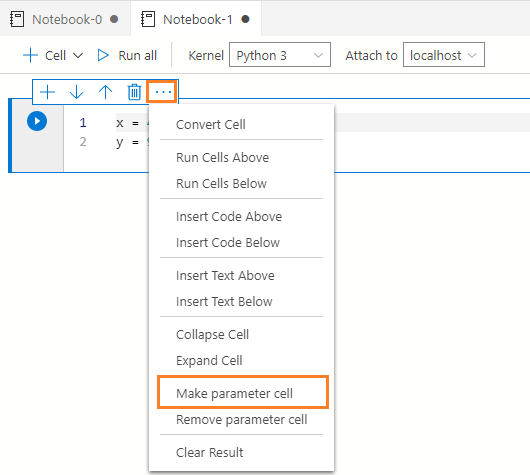
- **注意:**如果你不把一个单元格作为参数单元格,它在ADS中就像一个普通的代码或文本单元格一样。
一旦你点击选项--制作参数单元格,它就会将现有的单元格变成一个参数调用。它显示一个标签--参数,如下图所示。
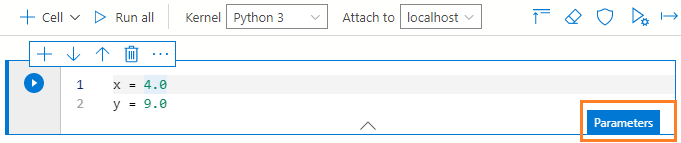
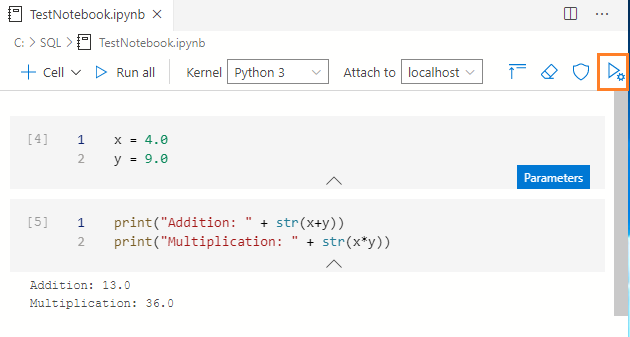
为了调用这些参数,添加一个新的代码单元,并编写python代码来执行两个参数的加法和乘法。
print("Addition: " + str(x+y))
print("Multiplication: " + str(x*y))
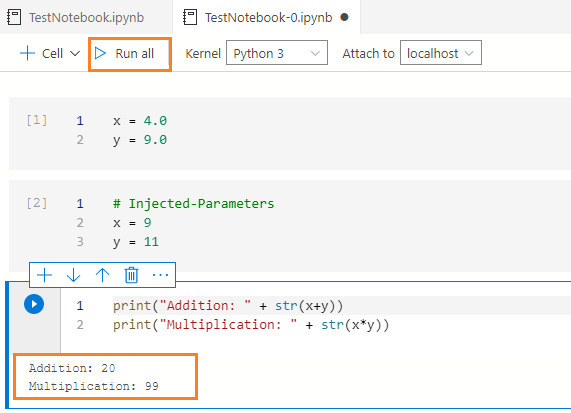
单击 "全部运行 "来执行这两个单元格并使用参数进行计算。你会得到使用参数单元格中指定的值的输出。

在上面的例子中,我们在代码单元中输入了参数值。然而,在这种情况下,我们想在运行时提供数值。因此,为了覆盖现有的(默认)值,你可以点击突出显示的图标--带参数运行--在运行时输入参数。
你会得到一个提示,输入参数的值。如果你不希望输入新的参数值,按键盘上的Escape键。

同样,由于我的笔记本里有两个变量,它提示输入另一个参数的值。

在笔记本中,你可以在注入的参数部分查看输入的参数值。
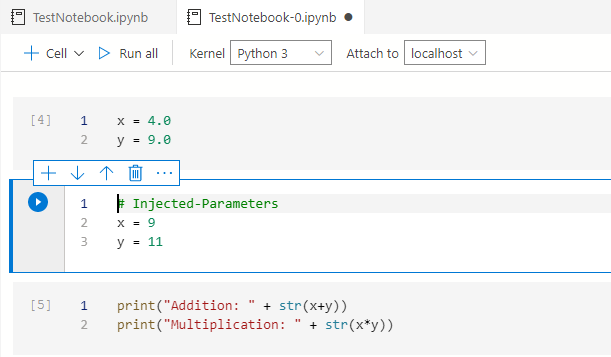
点击 "运行所有"按钮,执行带有注入参数的笔记本并显示结果。在这里你可以注意到,我们有默认值和注入的值。然而,为了计算的目的,ADS使用注入的值,因为它覆盖了默认值。
使用URI执行参数化的笔记本
假设你准备了一个SQL笔记本,你的团队成员可以在输入参数值后执行它。在这种情况下,你可以将SQL笔记本存储在一个仓库中,如GitHub。之后,在任何浏览器中打开URL,输入带有参数值的查询。
ADS笔记本支持HTTP、HTTPS、FILE URI模式的azuredatastudio://microsoft.notebook/open?url= 格式。
因此,从GitHub打开笔记本URI模式的脚本如下。
azuredatastudio://microsoft.notebook/open?url=https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/applications/azure-data-studio/parameterization.ipynb?x=10&y=20
在这个查询中,我们有以下字段。
- azuredatastudio:它指的是笔记本将在Azure Data Studio中打开
- Microsoft.notebook.open?url:输入带有笔记本完整路径的GitHub URL。这里要注意,笔记本的扩展名是.ipynb
- ?x=10&y=20:输入参数名称和它的值
浏览器会提示打开Azure Data Studio的权限。
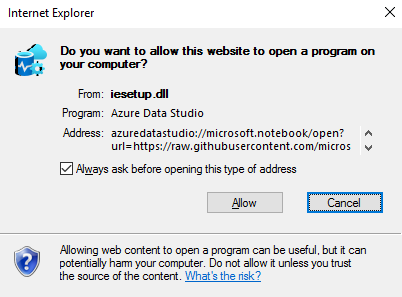
点击允许,就会得到另一个提示,允许笔记本核心扩展名打开URI。
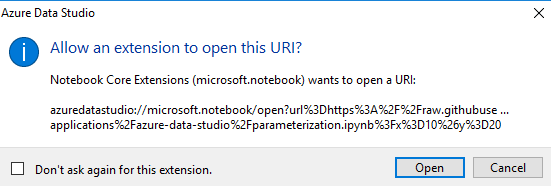
点击打开,并在下一个窗口中输入是。

它从GitHub URI下载笔记本并显示你注入的参数值。你可以运行它来显示结果。

用于PowerShell内核的参数化笔记本
PowerShell脚本有助于自动化DBA的东西。你可以用PowerShell以简化的方式执行各种任务。 对于这篇文章,我们不会专注于PowerShell脚本。我们的主要动机是使用笔记本执行有参数的PowerShell脚本。
假设我们自动化了一个恢复[AdventureWorks]数据库的任务。它包括以下步骤。
- 从GitHub URL下载备份文件--"github.com/Microsoft/s…
- 我们将备份文件保存到本地目录中
- 在指定的实例上恢复数据库
我们的要求是对URL、备份目录、SQL实例和数据库名称使用变量。在ADS中创建一个笔记本,选择内核为PowerShell并输入以下PS代码。
$BakURL = "https://github.com/Microsoft/sql-server-samples/releases/download/adventureworks/AdventureWorks2016.bak";
$BakFile = "c:/Temp/AdventureWorks2016.bak";
$SQLinstance="sqlnode3"
$DBName="Mydemodb"
如前所示,右键单击单元格eclipse,将此单元格转换为参数单元格。你会得到参数标签。

现在,打开另一个代码单元,输入恢复数据库备份的脚本。这个脚本使用的参数是备份URL、备份目录、SQL实例和数据库名称。
- Invoke-WebRequest从指定的备份URL下载备份文件,并将其保存在变量$BakFile指定的位置。
- Restore-SqlDatabase cmdlet使用这些变量所指定的值来恢复数据库
Invoke-WebRequest -Uri $BakURL -OutFile $BakFile;
Restore-SqlDatabase -ServerInstance SQLinstance -BackupFile $BakFile -Database $DBName -AutoRelocateFile
整个笔记本的代码看起来如下。

如果我们直接用这些参数的明确值来运行笔记本,它就会采用默认值并执行PS脚本。要明确输入变量的值,请点击带参数运行图标。
它显示参数的默认值。你可以输入一个新的值或按回车键移动到一个新的参数窗口。

对于备份文件目录,我将其修改为C:\Temp\AdventureWorks.bak

我使用参数$SQLinstance的默认值。

接下来,我指定$DBName变量的值为MydemoNotebookDB。

一旦我们输入最后一个参数值,它就会带着新的单元格注入的参数返回笔记本。在这个注入的参数中,你可以看到两个参数的值--DBName。我们对SQLInstance参数使用了默认值。它只显示那些我们需要用默认值覆盖的参数值。

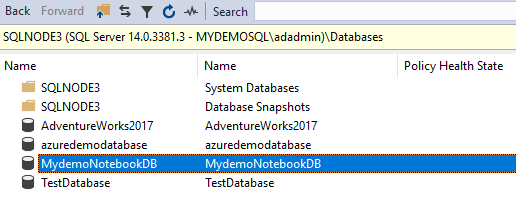
点击运行全部,你可以看到数据库[MydemoNotebookDB]在SQL实例[SQLNode3]中被恢复。
总结
本文探讨了Azure Data Studio的SQL笔记本功能--参数化笔记本。它使用户能够部署一个标准的脚本,需要一些参数值作为输入。你可以传递参数值并运行该脚本。你可以把它用于Python、PowerShell脚本自动化的SQL DBA任务。
