

本文的目的是提供关于参数嗅探是如何发生在临时查询中以及如何影响其性能的见解。
案例研究:无法触及的遗留代码
用户开始抱怨购买应用程序的电子邮件发送模块的性能。这一小段代码通过采取不同的参数找到电子邮件表中的行数。然而,当电子邮件表的总行数达到非常大的数字时,这段代码开始在性能方面运行得很差。在软件开发团队分析了应用程序的性能后,他们意识到一个遗留的子程序代码影响了应用程序的性能。这个子程序只是在执行一个特别的查询,而这个查询会导致一些参数值的等待时间非常长。之后,他们写了一个模拟代码来确定根本问题。

最后,他们诊断出这个问题,当某个值作为参数传给查询时,应用程序等待的时间是不可接受的。首先,该团队试图在应用程序代码上克服这个问题。不幸的是,由于文档不足,他们无法猜测其对应用程序的影响,所以团队挫败了对应用程序源代码的任何修改,然后决定在SQL Server方面找到一个解决方案。
在本文的下一节中,我们将试图找出这个案例研究中问题的原因。除此之外,我们将讨论一些替代解决方案的利弊。然而,首先,在我们进入细节之前,我们要看一下一些基本的概念。
预先要求
我们将创建一个样本表,用于本文的下一部分,并用一些合成数据来填充它。
CREATE TABLE EmailList(
Id INT PRIMARY KEY IDENTITY(1,1)
,usermailname VARCHAR(100)
, mailadress VARCHAR(100))
GO
DECLARE @I AS INT =1
WHILE @I<= 5000000
BEGIN
IF @I%2 = 0 OR @I%3 =0 OR @I%5 =0 OR @I%7=0
BEGIN
INSERT INTO EmailList VALUES('defaultmail','defaultmail@mail.com')
END
ELSE
BEGIN
INSERT INTO EmailList VALUES(CONCAT(@I,'mail_adress'),CONCAT(@I,'mail_adress@mail.com'))
END
SET @I =@I+1
END
CREATE INDEX IX_mailadress_001 ON EmailList (mailadress)
什么是临时查询?
Ad-hoc是一个源于拉丁语的单词,在英语中的意思是 "为了这个特定的目的"。ad-hoc查询是指没有参与任何预定义查询(存储过程、函数、视图等)的单一查询,它也是非参数化查询。例如,下面这个查询是一个临时查询。
SELECT * FROM Foo WHERE Bar >10
临时查询是如何存储在SQL Server查询计划缓存中的?
SQL Server可以缓存一个临时查询的查询计划。然而,要想让一个查询重新使用缓存的执行计划,其语法必须与缓存的查询绝对相同。如,添加空格或任何注释将被优化器认为是一个新的查询,并将导致一个新的查询计划被创建。这个工作原理的主要缺点是当数据库接受密集的临时查询请求时,过多的查询编译可能会给数据库引擎带来沉重的工作负担。下面的图片说明了同一查询的不同缓存查询计划,因为有空格字符。

简单和强制查询参数化
SQL Server查询参数化设置提供了简单和强制参数化选项。我们可以在数据库属性中找到这个设置。
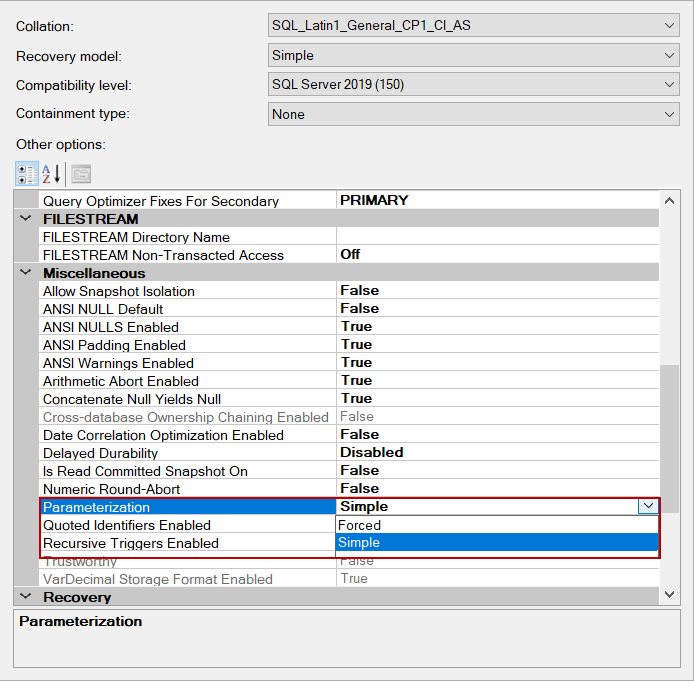
在简单参数化模式下,查询优化器可能决定对一些简单的查询进行参数化。为此,明确定义的值被参数化,这样新生成的查询计划就可以对不同的值进行重复使用。如果一个专门的查询包含以下表达式,该查询不会在简单模式下进行参数化。
- JOIN
- 输入
- BULK INSERT
- UNION
- INTO
- DISTINCT
- 顶部
- GROUP BY
- HAVING
- 计算
- 交叉/外部应用
- 子查询
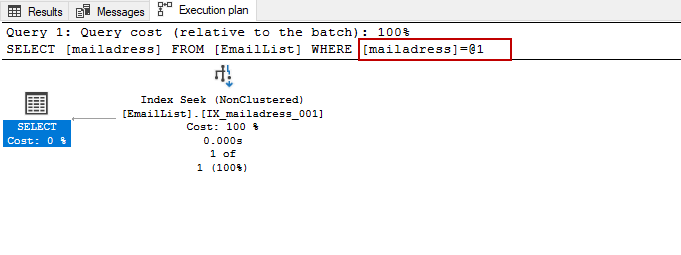
SQL Server会对这个简单的查询进行参数化处理,这种情况可以在查询计划缓存中看到。
SELECT mailadress FROM EmailList WHERE mailadress = '13mail_adress@mail.com'
SELECT plan_handle,UseCounts,RefCounts, Cacheobjtype, Objtype, TEXT AS SQL
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
where text like '%EmailList%'
and text not like '%plan_handle%'
and objtype = 'Prepared'

当我们用不同的值运行同一个查询时,将使用为前一个查询创建的计划。
SELECT mailadress FROM EmailList WHERE mailadress = '23mail_adress@mail.com'
</p>
<p>
<img style="margin: 0px auto; display: block;" src="https://www.sqlshack.com/wp-content/uploads/2022/06/execution-plan-parameter-list.png" class="wp-image-79367" alt="Execution plan Parameter List" />
</p>
<p>
Under the forced parameterization mode, SQL Server will try to parameterize every ad-hoc query disregarding their simplicity and other expressions.
</p><h2>Identify the case study problem: Ad-hoc query bad parameter sniffing</h2>
<p>
As we stated before, SQL Server is caching and reusing the compiled query plans, so that with this working principle reduces the query execution times and saves memory and CPU resources. The drawback of this mechanism occurs when the cached query plan does not show an effective performance for certain parameter values. Generally, this problem is experienced in the stored procedures, but we also face this problem in ad-hoc queries. At first, we'll run a query that filters out an infrequent value in the table. The execution plan of this query will be parameterized and cached into the plan cache in this manner.
</p>
<pre lang="tsql">
SELECT count(Id) FROM EmailList WHERE mailadress = '13mail_adress@mail.com'</strong>

SELECT plan_handle,UseCounts,RefCounts, Cacheobjtype, Objtype, TEXT AS SQL
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
where text like '%EmailList%'
and text not like '%plan_handle%'
and objtype = 'Prepared'

现在,我们将执行一个查询,过滤掉表中的一个高密度值。
SELECT COUNT(Id) FROM EmailList WHERE mailadress = 'defaultmail@mail.com'

查询优化器决定对这个高密度值使用缓存的查询计划,但是这个缓存的查询计划并没有显示出有效的性能。当我们在查询中使用OPTION(RECOMPILE)提示时,优化器会在每次执行查询时重建执行计划。我们将这个提示添加到我们的查询中,并分析重新编译的执行计划。
SELECT COUNT(Id) FROM EmailList WHERE mailadress = 'defaultmail@mail.com'
OPTION (RECOMPILE)

正如我们所看到的,优化器对同一个查询完全产生了不同的查询计划。首先,它决定了一个并行的查询计划,它还在rowstore功能上使用了批处理模式。很快,问题就发生了,因为对于这个值来说,缓存的查询计划性能是次优的。
使用sp_create_plan_guide
sp_create_plan_guide允许我们在不明确干扰查询语法的情况下,在查询中添加一些查询提示。OPTION(RECOMPILE)提示可以作为克服参数嗅探问题的解决方案,所以如果我们在查询中注入这个提示,就可以消除这个案例研究中的问题。在向SQL Server发送之前,查询的语法将被System.Data.SqlClient类转换为以下命令。
exec sp_executesql N'SELECT COUNT(Id) FROM [EmailList] WHERE mailadress=@MailAdrr',N'@MailAdrr varchar(200)',@MailAdrr='13mail_adress@mail.com'</strong>
我们可以通过sp_create_plan_guide存储过程为这个查询添加OPTION(RECOMPILE)提示,而不用改变应用程序的任何代码,如下所示。
EXEC sp_create_plan_guide
@name = N'FixPurchaseAppAdHoc',
@stmt = N'SELECT COUNT(Id) FROM [EmailList] WHERE mailadress=@MailAdrr',
@type = N'SQL',
@module_or_batch = NULL,
@params = N'@MailAdrr varchar(200)',
@hints = N'OPTION (RECOMPILE)'
我们可以在以下查询的帮助下显示创建的计划指南。
SELECT * FROM sys.plan_guides

在创建计划指南后,从购买应用邮件模块发出的查询将被重新编译。这种状态可以通过sql_statement_recompile事件来监控。

正如我们所看到的,优化器重新编译查询,而不考虑所有参数的值,这样我们在每次执行查询时都会得到新的查询计划。结果,通过这一改变,应用程序的性能下降到极限值以下。要放弃创建的计划指南。
EXEC sp_control_plan_guide N'DROP', N'FixPurchaseAppAdHoc'
GO
禁用参数嗅探
SQL Server在数据库级别提供了一个参数嗅探的设置。当我们禁用这个设置时,优化器在编译查询时考虑平均数据分布。这个设置可以在数据库范围配置中找到。
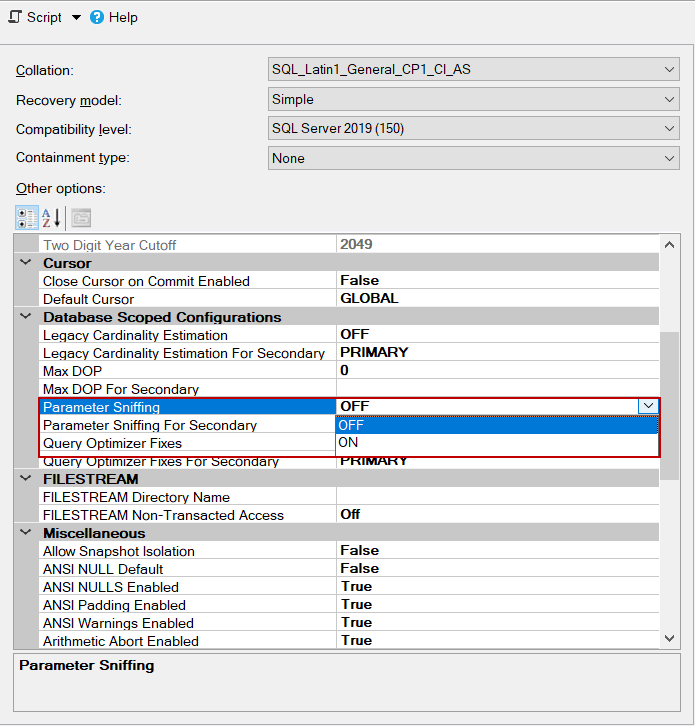
禁用参数嗅探选项后,优化器将使用密度向量而不是统计直方图来计算估计行数。
exec sp_executesql N'SELECT COUNT(Id) FROM [EmailList] WHERE mailadress=@MailAdrr',N'@MailAdrr varchar(200)',@MailAdrr='defaultmail@mail.com'

我们可以得到估计的行数,将总的行数与密度相乘。
DBCC SHOW_STATISTICS(EmailList,'IX_mailadress_001')

提示: 我们可以使用Google进行复杂的数学计算。

禁用参数嗅探并不是摆脱不良参数嗅探的有效方法,它可能对其他临时查询和存储过程造成性能问题。然而,在一些特殊情况下,它可以解决参数嗅探的问题。
总结
在这篇文章中,我们讨论了一个关于临时查询参数嗅探问题的案例研究。在不改变查询结构的情况下解决参数嗅探问题是非常困难的,但对于这个案例,我们很幸运地找到了解决方法。
