

这篇文章解释了如何管理SQL数据库的内存优化文件组。内存优化的文件组包含内存优化的表和表变量。我已经写了两篇文章,解释了我们如何将基于磁盘的表迁移到内存优化的表。现在,我们将学习如何在SQL数据库中添加内存优化的文件组。我将在文章中介绍以下内容。
- 使用SQL Server管理工作室和T-SQL查询在SQL数据库中添加内存优化的文件组
- 在一个特定的文件组中创建一个内存优化的表
我正在使用 SQL Server 2019 和 stackoverflow2010 数据库。Stackoverflow数据库包含表。首先,让我们看看如何添加一个内存优化的文件组。
使用SSMS添加内存优化的文件组
要添加一个内存优化的文件组,打开SSMS并连接到SQL Server数据库引擎🡪展开数据库🡪右键单击Stackoverflow2010并选择属性。
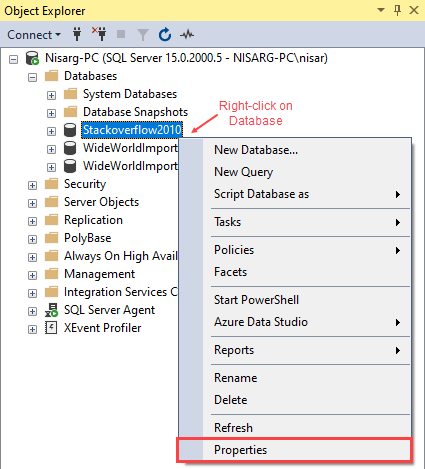
一个名为 "数据库属性"的对话框打开。在对话框中,选择 "文件组 "选项。在MEMORY OPTIMIZED FILEGROUP部分,点击添加文件组。
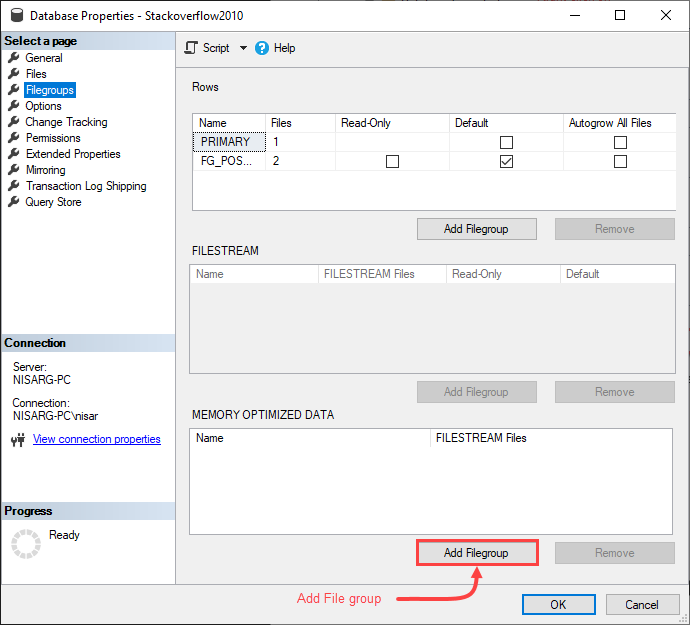
将在文件组网格视图中创建一行。在网格视图的列中指定所需的内存优化文件组的名称。名称列中指定内存优化文件组的名称。
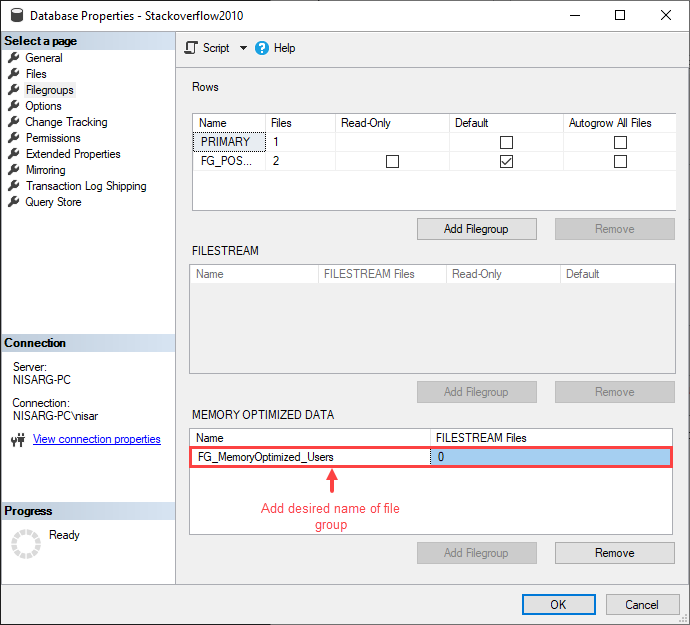
点击确定,创建一个文件组。现在,我们必须向FG_MemoryOptimized_Users文件组添加一个数据文件。要做到这一点,在数据库属性对话框中点击文件,然后点击添加。
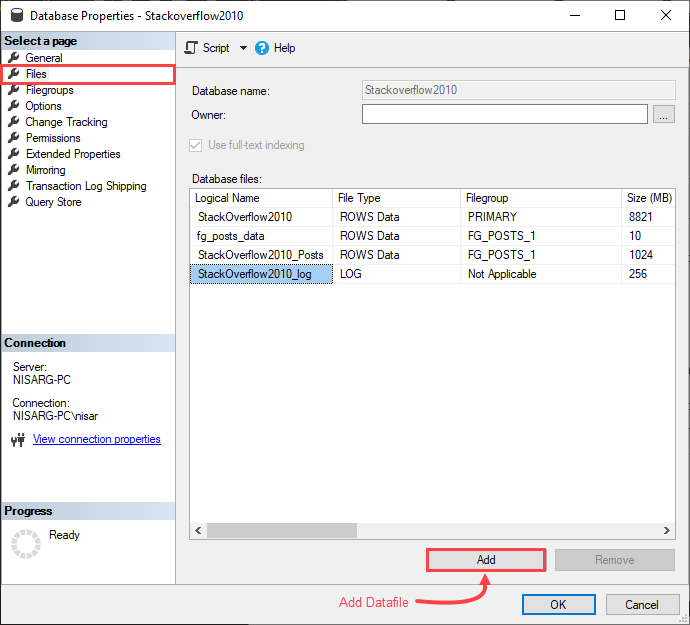
在数据库文件网格视图中的一行,将被添加。指定以下细节。
- 逻辑名称:指定所需的内存优化文件组的逻辑名称
- 文件类型:在文件类型栏中选择FILESTREAM数据
- 文件组:文件组名称将被自动检索
- 路径:在路径栏中,指定你要存储内存优化表的位置。
以下是数据库属性的文件面板的截图。

点击 "确定"来添加数据文件。现在,运行下面的查询来填充内存优化文件组的细节。
SELECT [databasefile].NAME AS [FileName],
[filegroup].NAME AS [File_Group_Name],
[filegroup].type_desc,
physical_name [Data File Location],
size / 128 AS [Size_in_MB],
state_desc [State of FILE],
growth [Data file growth]
FROM sys.database_files [databasefile]
INNER JOIN sys.filegroups [filegroup]
ON [databasefile].data_space_id = [filegroup].data_space_id
查询输出

正如你在上图中看到的,文件组已经创建。你可以查看内存优化文件组中的数据文件。 D:\FG_MemoryOptimized_Users\FG_MemoryOptimized_Users位置。

现在,让我们使用T-SQL查询在SQL数据库中创建一个内存优化的文件组。
使用T-SQL查询添加内存优化的文件组
我们可以使用 alter database add filegroup contains语句,在现有的SQL数据库中添加一个文件组。添加一个内存优化文件组的语法如下。
ALTER DATABASE <database_name> ADD FILEGROUP <file_group_name> CONTAINS MEMORY_OPTIMIZED_DATA
在语法上。
- database_name:指定你要添加内存优化文件组的数据库名称。
- file_group_name:指定你想添加到SQL数据库的文件组名称。
- CONTAINS:你可以指定你想在文件组中存储的数据类型。我们想添加内存优化的数据,所以指定MEMORY_OPTIMIZED_DATA
在我们的案例中,我们要在Stackoverflow2010数据库中添加FG_MemoryOptimized_Posts。要做到这一点,运行以下查询语句。
ALTER DATABASE [Stackoverflow2010] ADD FILEGROUP [FG_MemoryOptimized_Posts] CONTAINS MEMORY_OPTIMIZED_DATA
一旦文件组被添加,让我们在FG_MemoryOptimized_Posts文件组中添加一个数据文件。在内存优化的文件组中添加数据文件。要添加一个数据文件,我们可以使用 更改数据库添加数据文件到文件组语句。添加数据文件的语法如下。
ALTER DATABASE <database_name> ADD FILE (NAME= <logical_file_name>, FILENAME=<Memory_Optimized_Filegroup_Location> ) TO FILEGROUP <FILE_GROUP_NAME>
在语法上。
- database_name:指定你要添加内存优化文件组的数据库名称
- file_group_name:指定你想添加到数据库的文件组名称
- ADD FILE: 指定要添加到文件组的数据文件的细节。在ADD FILE关键字中,我们必须指定以下参数
- logical_file_name:指定所需的文件组的名称
- Memory_Optimized_Filegroup_Location:指定你要存储内存优化数据的目录的位置
- file_group_name:指定你要添加数据文件的文件组名称。文件组名称必须在TO FILEGROUP关键字之后指定。
在我们的例子中,我们想在FG_MemoryOptimized文件组中添加一个名为 DF_MemoryOptimized_Posts(内存优化数据)在 FG_MemoryOptimized_Posts 文件组中。添加一个数据文件,运行下面的命令。
ALTER DATABASE [Stackoverflow2010] ADD FILE ( NAME = N'DF_MemoryOptimized_Posts', FILENAME = N'D:\FG_MemoryOptimized_Posts' ) TO FILEGROUP [FG_MemoryOptimized_Posts]
一旦添加了数据文件,运行下面的查询来查看文件组的列表。
use StackOverflow2010
go
SELECT [databasefile].NAME AS [FileName],
[filegroup].NAME AS [File_Group_Name],
[filegroup].type_desc,
physical_name [Data File Location],
size / 128 AS [Size_in_MB],
state_desc [State of FILE],
growth [Data file growth]
FROM sys.database_files [databasefile]
INNER JOIN sys.filegroups [filegroup]
ON [databasefile].data_space_id = [filegroup].data_space_id
查询输出

正如你所看到的,名为 DF_MemoryOptimized_Posts 的数据文件已经被添加到FG_MemoryOptimized_Posts 文件组中。
在内存优化的文件组中创建一个表
现在,让我们创建一个简单的表,名为想要在FG_MemoryOptimized_Posts 文件组中创建一个名为tblArchivedPosts的表,创建表的查询将如下。
CREATE TABLE [tblArchivedPosts]
(
[Id] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED,
[AcceptedAnswerId] [int] NULL,
[AnswerCount] [int] NULL,
[Body] [nvarchar](max) NOT NULL,
[ClosedDate] [datetime] NULL,
[CommentCount] [int] NULL,
[CommunityOwnedDate] [datetime] NULL,
[CreationDate] [datetime] NOT NULL,
[FavoriteCount] [int] NULL,
[LastActivityDate] [datetime] NOT NULL,
[LastEditDate] [datetime] NULL,
[LastEditorDisplayName] [nvarchar](40) NULL,
[LastEditorUserId] [int] NULL,
[OwnerUserId] [int] NULL INDEX IX_tblArchivedPosts_OwnerUserId NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000),
[ParentId] [int] NULL,
[PostTypeId] [int] NOT NULL,
[Score] [int] NOT NULL,
[Tags] [nvarchar](150) NULL,
[Title] [nvarchar](250) NULL,
[ViewCount] [int] NOT NULL
) WITH (MEMORY_OPTIMIZED=ON)
GO
一旦查询成功执行,让我们验证表是否在FG_MemoryOptimized_Posts文件组中创建。要做到这一点,运行以下查询
use StackOverflow2010
go
select t.object_id [Object ID], t.name [Table Name],f.name [Filegroup Name],durability_desc [Durability],f.type_desc [Filegroup Type] from
sys.tables t inner join sys.filegroups f on t.lob_data_space_id=f.data_space_id
where lob_data_space_id=3
查询输出

正如你所看到的,tblArchivedPosts表是在FG_MemoryOptimized_Posts文件组中。
总结
在这篇文章中,我们学习了如何在现有数据库中创建一个内存优化的文件组。我们学习了以下内容。
- 使用SQL Server management studio和T-SQL查询在SQL数据库中添加多个内存优化的文件组。
- 在一个特定的文件组中创建一个内存优化的表。
