

绪论
本文是Azure机器学习系列文章的最新内容,即Azure机器学习的集合分类器。在这篇文章的讨论中,我们重点讨论了机器学习的数据清理和特征选择技术。此外,我们还讨论了Azure机器学习中的几个机器学习任务,如分类、聚类、回归、推荐系统和时间序列异常检测。此外,我们还讨论了Azure机器学习服务中的AutoML功能。在AutoML技术中,我们已经确定了如何在AutoML中利用分类。这篇文章是我们之前讨论的分类技术的延伸。
从下图中可以看出,Azure机器学习中有很多两类分类技术。

每个数据建模者都会有这样的问题:如何在这些可用的算法中选择最佳算法。在分类中,我们可以使用准确率、精确度、召回率、F1测量、ROC曲线来选择最佳分类技术。这意味着我们将通过比较评价参数来选择单一技术。
在集合分类器中,我们将研究如何使用多种分类技术进行预测,以便它能产生具有更高精确度的更好的模型,或者它们能避免过度拟合。这就相当于一个病人要找多个专科医生来诊断疾病,而不是依赖一个医生。
下图显示了集合分类的设计方式。
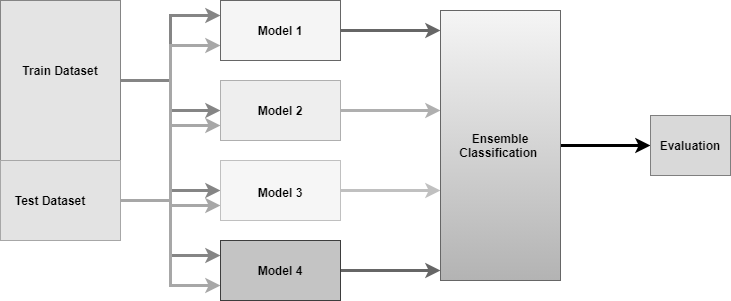
从上图可以看出,多个分类器被组合起来,以定义一个集合分类。
使用Azure机器学习构建标准分类器
让我们首先使用Azure机器学习建立标准分类,正如我们在之前的文章中所讨论的那样。 以下是为实现上述目标而建立的实验,这个实验可以在双类贝叶斯点机的分类器中找到。
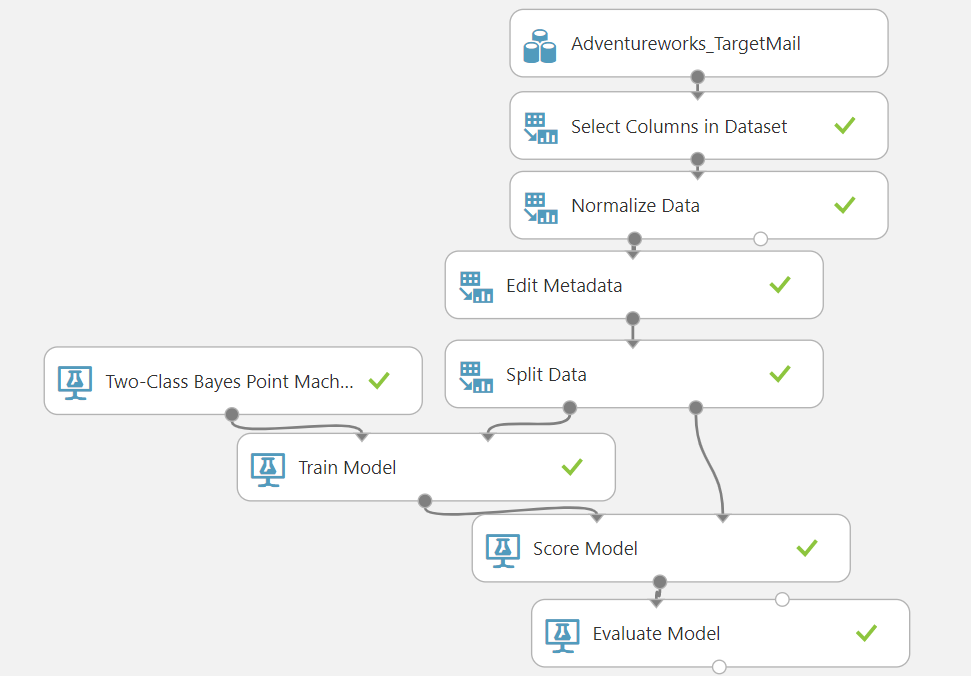
让我们快速了解一下如何进行配置以构建上述分类器。首先,我们选择了本系列文章中一直在使用的Adventureworks数据集。然后,我们使用 "选择数据集中的列 ",删除了不必要的列,如姓名和地址,因为这些列不会影响预测结果。然后,使用 "规范化数据 "控件,用MinMax转换方法对工资和年龄列进行了规范化。接下来,使用编辑元数据(Edit Metadata)控件来表明CustomerKey应该从分类器特征中删除,因为CustomerKey对分类没有贡献,但我们需要Customer Key来加入数据集。
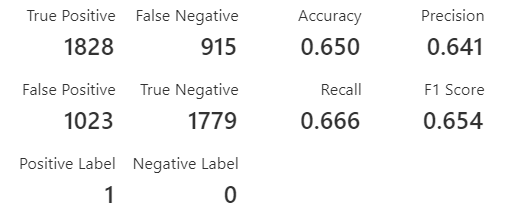
然后将数据按70/30的比例分割,以便进行训练和测试。然后使用双类分类技术的训练模型。然后,Score模型和Evaluate模型控件被用来衡量所建模型的性能,以下是所建模型的评估参数。
在Azure机器学习中配置集合分类器
让我们看看如何在Azure机器学习中把标准分类扩展到Ensemble分类器。在我们讨论这个配置的细节之前,你可以从Ensemble Classification中查看或下载这个实验
下图显示了Azure机器学习中集合分类器的复杂布局。 
请注意,由于实验的复杂性,实验的布局可能不可见,所以你可能要从Azure AI Gallery中查看实验。
以下是我们在Azure机器学习中用于集合分类器的Azure机器学习控件。
控件 | 用途和说明 |
数据集 | 这个控件将从数据集开始,并将使用冒险数据集。 |
选择数据集中的列 | 这个控件将用于从现有的数据集中选择列,因为所有的属性都不是下一层次所需要的。 |
归一化数据 | 使用MinMax归一化技术来归一化客户的年收入和年龄。 |
编辑元数据 | 这个控件的使用有两个原因。
|
分割数据 | 由于这是一种分类技术,我们需要两个独立的数据集来训练和测试模型。 这个控件用于以70/30的分布来分割训练/测试数据集的数据。 |
双类提升决策树 | 这五种分类算法用于Azure机器学习中的集合分类器。 |
双类神经网络 | |
双类支持向量机 | |
二类逻辑回归 | |
双类决策丛林 | |
培训模型 | 五种控制的Train模型被用来训练上述分类技术的数据集。 |
分数模型 | 使用得分模型对每个分类算法进行测试。 |
评估模型 | 评估模型被用来评估每种分类技术的准确性。 |
连接数据 | 连接数据控制被用来连接来自五个不同分类训练模型的数据流。 |
应用SQL转换 | SQL查询被用来得出集合分类的分类结果。本实验使用了其中两个控件来定义两种不同方法的分类,即投票和称重。 |
执行Python脚本 | 我们写了一个Python脚本来计算不同的分类评估参数,如准确率、精确度、召回率和集合分类的F1度量。 |
现在让我们看看如何在Azure机器学习中为合集分类器创建一个实验。在这个实验中,使用了五种两类分类技术。五个配置中的一个配置(双类提升决策树)如下图所示。

上述数据流在数据集中选择列之后的输出如下图所示。
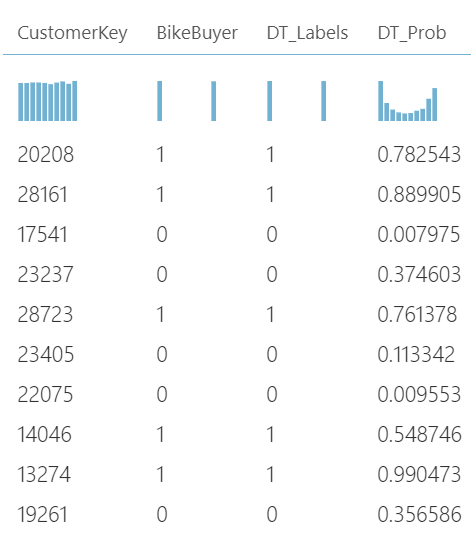
CustomerKey是识别客户的关键,Bike buyer属性是自行车买家的实际值。 DT_Labels表示决策树对自行车买家的预测,DT_Probs表示预测的概率。
这是对其他四种两类分类技术进行的,即两类神经网络、两类支持向量机、两类逻辑回归和两类决策丛林。在完成所有五种分类技术的预测后,使用连接数据控制将所有技术连接起来,输出结果如下。

下一步是在五种分类完成后应用合集技术。
定义合集分类器的第一个技术是投票技术。这意味着,在五个分类中,最终的分类将取决于最大的票数。例如,在五个分类中,如果有三个或更多的分类被列为自行车买家的是,那么集合分类将是是。
下一个技术是根据每个技术的权重来定义集合分类。如下表所示,根据准确性分配不同的权重。
技术 | 准确率 | 权重 |
双类提升决策树 | 0.80 | 0.23 |
双类神经网络 | 0.75 | 0.21 |
双类支持向量机 | 0.62 | 0.17 |
双类逻辑回归 | 0.65 | 0.18 |
双类决策丛林 | 0.76 | 0.21 |
下图是这个实验的最后部分。
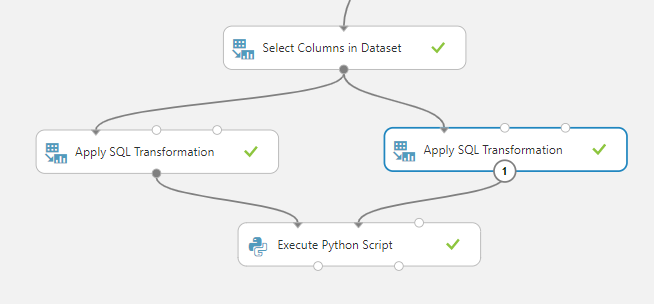
两个Apply SQL Transformation控件都是用来将现有数值转换为集合分类器的。第一个查询是用于投票,第二个查询是用于加权技术。
SELECT CustomerKey
,BikeBuyer
,(DT_Labels + NN_Labels + SVM_Labels + LR_Labels + DJ_Labels) / 5 AS Pred
,(DT_Prob + NN_Prob + SVM_Prob + LR_Prob + DJ_Prob) / 5 AS Prob
FROM t1;
SELECT CustomerKey
,BikeBuyer
,CASE
WHEN ((DT_Labels * 0.23) + (NN_Labels * 0.21) + (SVM_Labels * 0.17) + (LR_Labels * 0.18) + (DJ_Labels * 0.21)) >= 0.5
THEN 1
ELSE 0
END AS Pred
,((DT_Prob * 0.23) + (NN_Prob * 0.21) + (SVM_Prob * 0.17) + (LR_Prob * .18) + (DJ_Prob * .21)) AS Prob
FROM t1;
集合分类被定义后,下一个选项是在下面列出的python脚本中计算不同的分类评估参数。
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
def azureml_main(dataframe1 = None, dataframe2 = None):
acc1 = accuracy_score(dataframe1["BikeBuyer"], dataframe1["Pred"])
pre1 = precision_score(dataframe1["BikeBuyer"], dataframe1["Pred"])
rec1 = recall_score(dataframe1["BikeBuyer"], dataframe1["Pred"])
f11 = f1_score(dataframe1["BikeBuyer"], dataframe1["Pred"])
acc2 = accuracy_score(dataframe1["BikeBuyer"], dataframe2["Pred"])
pre2 = precision_score(dataframe1["BikeBuyer"], dataframe2["Pred"])
rec2 = recall_score(dataframe1["BikeBuyer"], dataframe2["Pred"])
f12 = f1_score(dataframe1["BikeBuyer"], dataframe2["Pred"])
data = [["Voted",acc1,pre1,rec1,f11],["Weighted",acc2,pre2,rec2,f12]]
df = pd.DataFrame(data,columns=['Type','Accuracy','Precision','Recall','F1'])
return df,
以下是不同集合分类技术的评估参数。
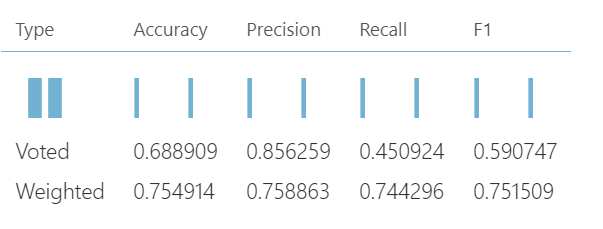
总结
Azure机器学习中的集合分类器是一种改进的分类技术,它结合了多种分类方法。这种技术将引入更高的准确性,并避免分类中的过度拟合。本文介绍了投票和加权的集合分类器技术。
