

Azure SQL数据库是将你的数据库从企业内部迁移到云基础设施的一个流行选择。它使你能够转移到一个完全管理的平台即服务(PaaS),并具有理想的性能和成本效益。
Azure SQL数据库有两种定价模式--DTU和vCores。
基于DTU的购买模式
数据库事务单元(DTU)结合了计算(CPU)、内存、IOPS。你不能增加单个资源,如内存或CPU。但是,你可以增加DTU的数量来增加Azure数据库的资源。这个解决方案适合那些寻找预定义资源配置的客户,他们需要平衡CPU、内存和IO。
x Azure SQL Databases为不同范围的计算、存储提供基本、标准和高级服务层。 你可以很容易地迁移到另一个服务层;但是,在切换期间需要最少的停机时间。
下表对基本、标准和高级服务层进行了比较。
基本服务 | 标准服务 | 高级服务 | |
正常运行时间 SLA | 99.99% | 99.99% | 99.99% |
最大存储尺寸 | 2 GB | 1 TB | 4 TB |
最大DTU | 5 | 3000 | 4000 |
IOPS(约数)* | 每DTU 1-4 IOPS | 每DTU 1-4 IOPS | 每DTU >25 IOPS |
最大的备份保留时间 | 7天 | 35天 | 35天 |
柱状存储索引 | 不支持 | 对S3及以上版本支持 | 支持 |
内存OLTP | 不支持 | 不支持 | 支持的 |
基于vCore的购买模式
术语vCore指的是虚拟核心。在Azure SQL数据库的这种购买模式中,你可以从配置的计算层和无服务器计算层中进行选择。
- 提供的计算层:你为工作负载选择确切的计算资源。
- 无服务器计算层。Azure会根据无服务器层的工作负载活动,自动暂停和恢复数据库。在暂停期间,Azure不向你收取计算资源的费用。
vCore模型有以下服务层级。
一般用途
通用型是默认的服务层,适用于一般工作负载。它提供99.99%的SLA,存储延迟在5到10毫秒之间。
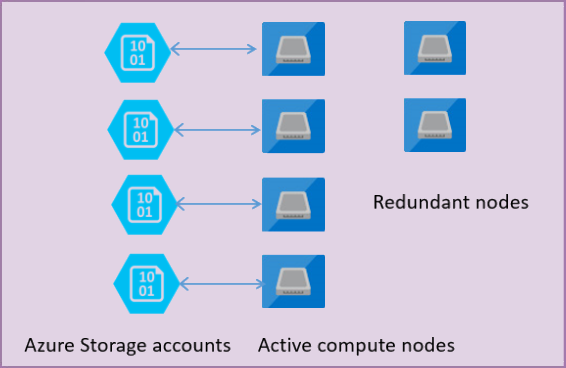
通用服务层有两层。
- 无状态计算层,运行sqlserver.exe进程。它包含暂存和缓存数据,如计划缓存、缓冲池、列存储池。Azure服务结构运行这个有状态的层,包括初始化、控制计算节点的健康状况以及在需要时进行故障切换等任务。
- 有状态的计算层将数据库文件(MDF、LDF)存储在Azure blob存储上。Azure存储有其内置的数据可用性和冗余功能。
- 它支持5GB至4TB的SQL数据库,支持5GB至3TB的无服务器计算。
关键业务
关键业务层适用于需要最高复原力和每个副本最高数据库IO性能的关键应用。它在Multi-AZ配置中提供99.995%的可用性和1-2毫秒的低存储延迟。
关键业务服务层还使用地理复制提供了5秒的保证RPO和30秒的RTO。此外,你可以在关键业务层使用5GB到4TB的存储。
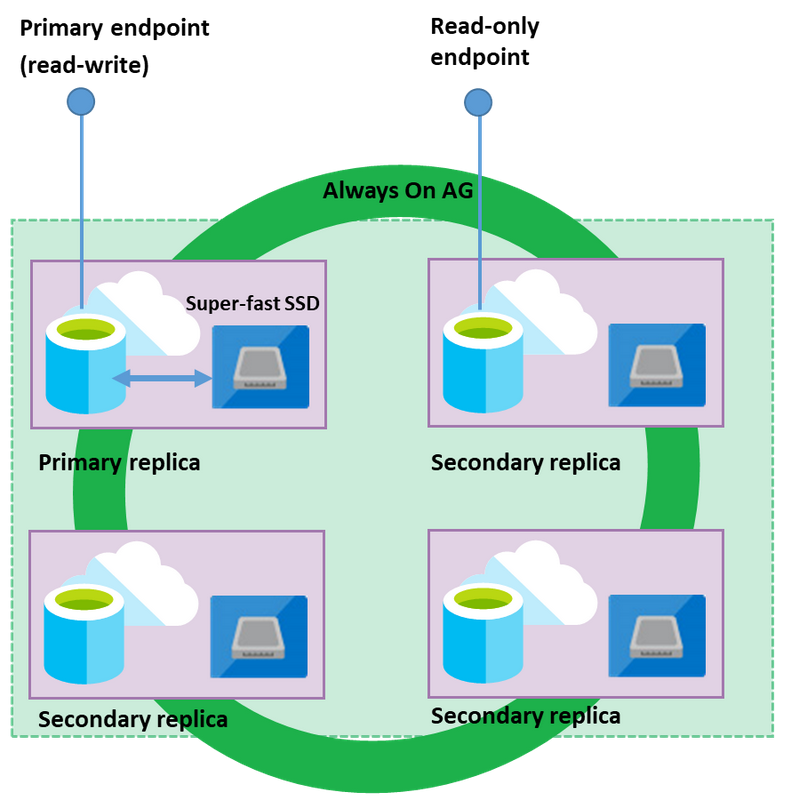
在这种模式下,SQL Server进程(sqlserver.exe)和基础数据库文件(MDF、LDF)都存在于同一个节点上。它使用本地连接的超高速固态硬盘,为数据库工作负载提供极低的延迟。它还使用Always On可用性组来维护数据库节点的集群。三个次级副本从主节点接收数据。在主节点发生故障的情况下,次要副本接管了主副本的角色,并开始响应数据库查询。主端点总是指向当前的活动副本。
关键业务服务层也使用读出功能,将只读工作负载卸载到其中一个辅助副本。同样,它可能会提高主数据库的性能,因为你可以把工作,如报告查询,卸载到辅助数据库。同样,这个功能在关键业务服务层是可用的,没有任何额外的费用。

你可以在连接字符串中指定参数,以便与主副本或辅助只读副本连接。
- ApplicationIntent=Readonly。连接被重定向到第二只只读副本
- ApplicationIntent=Readonly(默认)。连接发生在主副本上
超大规模(Hyperscale
Hyperscale服务层适用于高度可扩展的存储需求。它提供了高性能和可扩展性,Azure SQL数据库的自动规模最高可达100TB。
Hyperscale数据库包含以下组件。
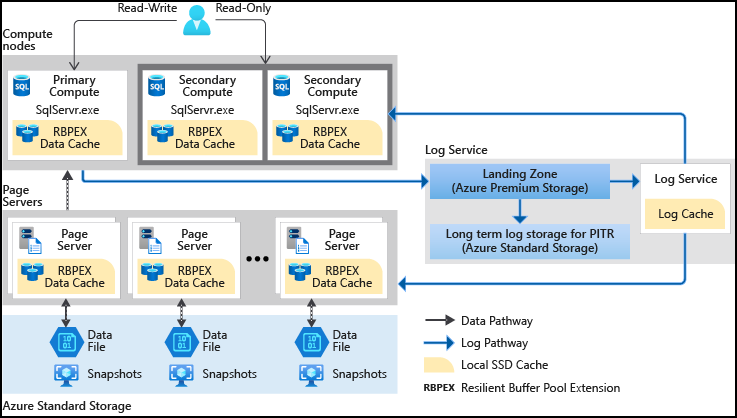
-
计算节点。计算节点使用基于SSD的缓存,称为弹性缓冲池扩展(RBPEX)。它确保了获取数据页的最小网络往返次数。主计算节点为所有读写工作负载服务。次级节点作为热备节点工作,如果需要,你可以卸载读工作负载。
-
页面服务器。页面服务器负责超大规模数据库中的一个页面子集。每个页面服务器控制多达1TB的数据。页面服务器的工作是在需要时向计算节点提供数据库页面。它还在交易更新其数据时保持页面的更新。它使用一个日志服务,以便页面被更新。如架构图所示,这些页面服务器也使用RPBEX数据缓存以获得快速响应。
-
日志服务。日志服务接收主计算副本的日志记录,将它们持久地保存在持久的缓存中,并将它们传送到二级副本中。它还将这些日志发送到相关的页面服务器。因此,所有二级计算副本和各自的页面服务器都会收到数据变化。它还将日志记录推送到Azure标准存储,以便长期保留。因此,它消除了频繁截断日志的要求
-
Azure存储。Azure存储存储了超大规模数据库的所有数据文件。页面服务器会更新这些数据文件,使其保持最新状态。此外,Azure使用数据文件的存储快照进行备份和恢复
-
注意
-
Azure SQL数据库和Azure SQL管理实例都支持vCore购买模式
-
超大规模服务层可用于基于v-Code的Azure单一数据库
-
将Azure SQL数据库从DTU迁移到vCore购买模式
你可以轻松地从DTU迁移到基于vCore的购买模式,类似于扩展资源。它还需要最少的停机时间来进行迁移。
作为一般的经验法则,您可以使用以下公式将DTU映射到vCores。
-
每100个DTU标准层=1个通用的vCore
-
每125个DTU高级版=1个关键业务核心
-
注意:本规则给出了DTU和vCore之间的近似映射。它不考虑硬件世代或弹性池。
DTU 到 vCore 的映射
我们可以对配置了DTU模型的Azure SQL数据库使用以下T-SQL查询,以返回可能与Gen4和Gen5硬件中的vCore数量相匹配的数据。
- 注意:在Azure SQL数据库中执行此查询,而不是在主数据库中执行。

例如,在我的实验室环境中,有一个基本服务层,它返回以下输出。

- 当前DTU数据库的逻辑CPU为0.50,在Gen5硬件上每个vCore有1.30GB内存
- 近似匹配。
- 通用服务层
- Gen4硬件,0.350个vCore,每个vCore有7GB内存
- Gen5硬件,0.500个vCore,每个vCore 5.05 GB内存
同样地,下表中提到了迁移高级P15数据库的情况。
dtu_logical_cpus | dtu_hardware_gen | dtu_memory_per_core_gb | Gen4_vcores | Gen4_memory_per_core_gb | 第五代vcores | 第5代内存_每核_GB |
42 | 第5代 | 4.86 | 29.4 | 7 | 42 | 5.05 |
- 目前DTU数据库在Gen5硬件上有42个逻辑CPU(vCores),每个vCore有4/86GB内存
- 近似匹配
- 通用服务层
- Gen4硬件,29.4个vCores和每个vCore 7GB内存
- Gen5硬件,42个vCores和每个vCore 5.05 GB内存
总结
本文探讨了Azure SQL数据库和Azure SQL管理实例的基于DTU和vCore的购买模式。Azure管理实例只支持vCores模式。你应该使用vCore模型,因为它提供了单独选择资源的灵活性,而且你可以根据需要扩展它们。
如果你有一个现有的基于DTU的Azure数据库,你可以根据使用T-SQL返回的大致建议,计划迁移到vCore。但是,在生产中进行更改之前,一定要在较低的环境(非d)上进行工作负载测试。
