

本文讨论了如何在Azure机器中使用文本挖掘中流行的词向量技术进行文本分类。本文是Azure机器学习系列的一部分,在此期间我们讨论了许多方面,如数据清理和机器学习的特征选择技术。我们进一步讨论了如何在Azure机器学习中进行分类,我们将在这里利用其中的一些经验。此外,我们还讨论了Azure机器学习中的几个机器学习任务,如聚类、回归、推荐系统和时间序列异常检测。关于文本挖掘,我们已经讨论了诸如语言检测、命名实体识别、LDA、文本推荐等技术。
在这篇文章中,我们将研究如何利用词向量在Azure机器中进行文本分类,我们也将利用流行的WEKA工具。
什么是词向量
我们知道,文档有单词和句子,对它们进行建模分析通常是一项复杂的任务。 因此,需要将这些文档转换为单词向量,以便对它们进行建模。
怀卡托知识分析环境(WEKA)有丰富的功能来建立文本数据的词向量。本文将使用从WEKA中创建的词向量,并在Azure机器学习中使用它们,以便建立分类模型。
我们选择了流行的IMDB 2,000条评论数据集,其评分如WEKA的屏幕上所示。

有2,000条评论,其中1,000条被标记为正面,而其余的1,000条评论被标记为负面,如下面的截图所示。
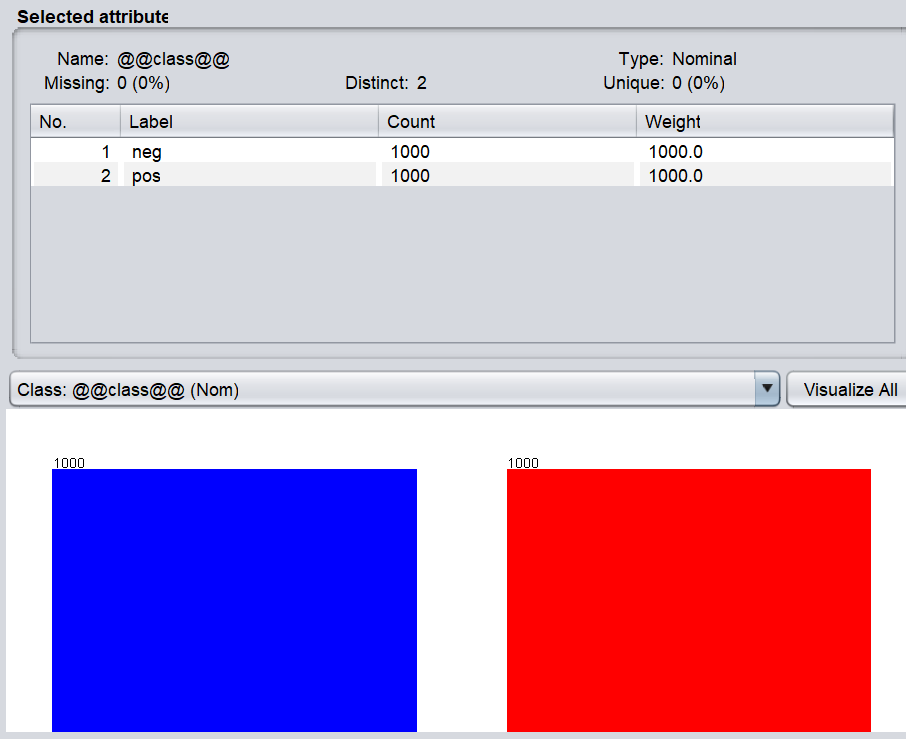
我们的任务是找出使正面或负面评论的关键词。通过这种建模,我们将能够把未知的评论归入正面或负面的类别。
文件加载到WEKA后,你需要使用一个过滤器,Weka->过滤器->无监督->属性->StringToWordVector,如下图所示。
一旦选择了所需的过滤器,你需要对所选的过滤器进行配置。

下面是对所选的StringToWordVector过滤器的配置,这样就可以得出不同类型的词向量。
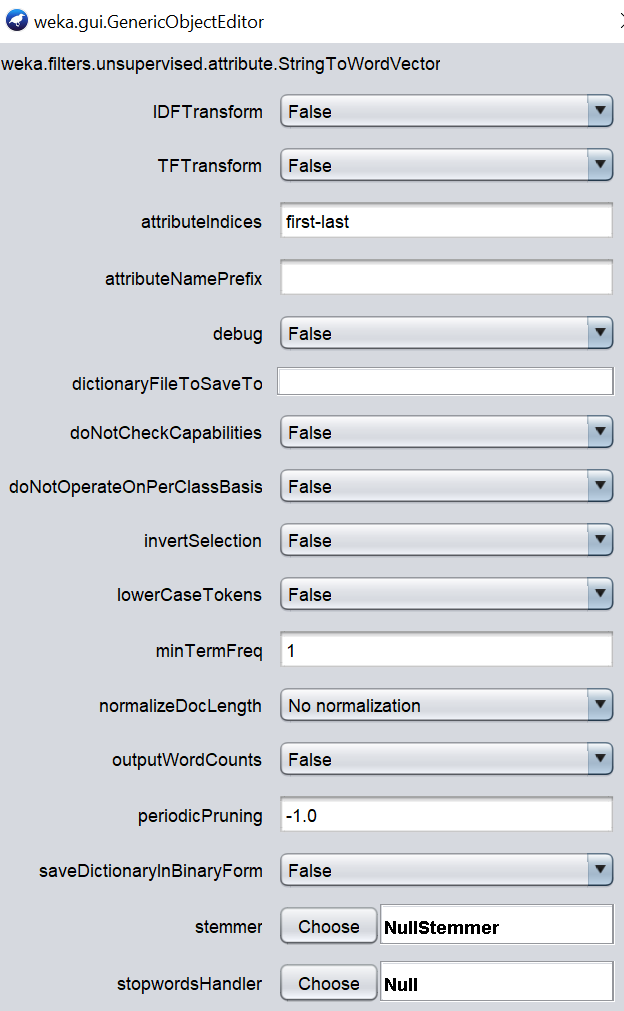
虽然WordVector过滤有很多配置,但我们将只使用其中的几个配置。首先,我们将研究干系人、停止词处理程序、标记化器和保留词的数量,如下图所示。
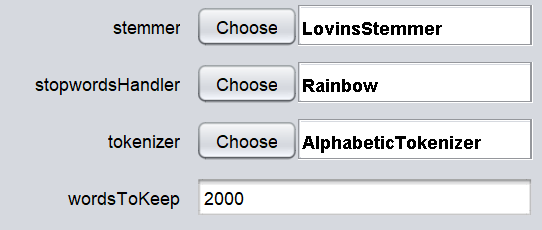
标记化技术将决定如何选择关键词。由于选择了AlphabeticTokenizer,所有的数字和特殊字符将被删除。停止词配置将放弃没有任何语义的词,如I、We、You、a、an、the等。通过使用lovinsStemmer词干,单词将被转换为基本形式。请注意,这些是在文本挖掘分析中处理的经典技术。这些都是应该在文本文件上执行的强制性技术。
除了上述技术外,还有一些其他技术将取决于数据集的情况。这四个配置应该用WEKA的不同配置进行验证。
字数统计:输出字数而不是0或1(表示有或没有一个字)。
术语频率(TF):术语频率被转换为对数(频率+1 )
逆向文档频率(IDF):如果同一个词在许多文档中重复出现,IDF将降低词频计数的权重。
文档归一化:这个参数将考虑文档的大小。
通过四个参数,有十六种组合,如下表所示。
组合 | IDF | TF | 世界计数 | 文档规范化 |
1 | 假的 | 错 | 错 | 错 |
2 | 错 | 准确 | 错 | 错 |
3 | 错 | 真 | 真 | 真 |
4 | 错 | 真 | 真 | 真 |
5 | 假的 | 真 | 错 | 真 |
6 | 错 | 错 | 错 | 准确 |
7 | 错 | 错 | 准确 | 错 |
8 | 错 | 错 | 真 | 准确 |
9 | 真 | 错 | 错 | 错 |
10 | 真 | 准确 | 错 | 错 |
11 | 真 | 真 | 准确 | 错 |
12 | 真 | 真 | 真 | 真 |
13 | 真 实 | 真 | 假的 | 真 |
14 | 真 | 错 | 错 | 准确 |
15 | 真 | 假的 | 真 | 错 |
16 | 真 | 错 | 真 | 真 |
通过上述组合,创建了16个文件,这些文件被上传到不同配置IMDB | Kaggle的单词向量。
现在文件已经准备好在Azure机器学习中用于文本分类。所有这十六个文件都上传到Azure机器学习中供你使用。
16个数据集被上传后,接下来就是在Azure机器学习中进行文本分类。这将与之前涉及的文本分类相同,如下图所示。
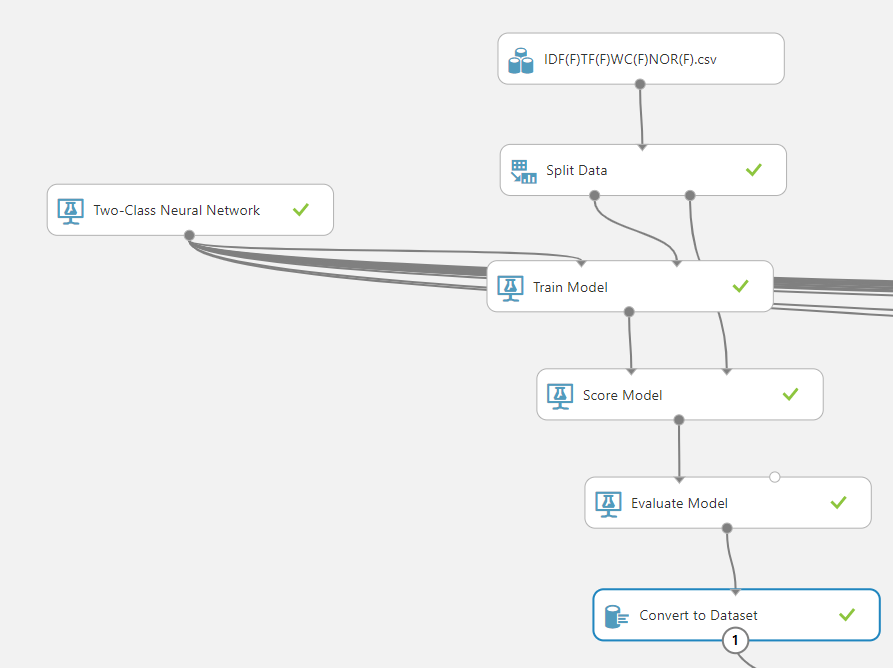
如上图所示,Azure机器学习中的文本分类使用的是二类神经网络。分割数据控件用于将数据按70/30的比例进行训练和测试,其中使用了训练 模型和评分模型。在评估模型控制之后。然后连接到转换 为 数据集控制。为每个数据集建立类似的16个单元,并连接相同的两类神经网络算法。
多个应用SQL转换控件被用来结合数据集,其脚本如下。
SELECT ‘IDF(F)TF(F)WC(F)NOR(F)’ AS Type,* from t1
UNION ALL
SELECT ‘IDF(F)TF(T)WC(F)NOR(F)’ AS Type,* from t2
UNION ALL
SELECT ‘IDF(F)TF(T)WC(T)NOR(F)’ AS Type,* from t3`
尽管我们可以使用Add Rows控件,但由于有100个控件的限制,我们使用了Apply SQL Transformation控件来减少控件的数量。Add Rows 控件只有两个输入,而 Apply SQL Transformation 有三个输入。通过UNION,我们可以减少控件的数量。
最后,这是所有数据集的输出,以及它们对Azure机器学习中文本分类的评估参数。

从这些组合中,你可以选择准确率或精确度或召回率或F1-Score最高的更好的组合。正如你所看到的,IDF-True,TF-True,Word Count-False和Document Normalization-False是更好的组合,因为它有最高的准确率以及最高的精确度。
你可以参考参考资料部分中列出的共享实验。由于这是一个笨重的实验,所以有几件事需要指出。由于这是Azure机器学习的免费版本,所以不能使用超过100个控件。此外,一个实验不能包含超过100MB的数据。由于我们有16个数据集,大小超过了100MB,所以从实验中删除了一些数据集,你可以从共享数据集中再次添加它们。此外,SQL转换对超过1024的列将不起作用,这是Azure机器学习中文本分类的另一个阻塞问题。
正如上一篇文章中所讨论的,我们可以使用集合分类来进行多种配置。由于准确率几乎相似,所以没有必要进行集合分类。
如果我们需要标记未标记的文档,首先,我们需要在WEKA中进行必要的参数转换,然后将这些值输入到Azure机器学习中,以找到
结论
本文讨论了如何在WEKA中利用字向量与不同的文本分析参数,如术语频率、逆向文档频率、文档规范化和字数。我们使用了从WEKA创建的词向量,并将其加载到Azure机器学习中。使用标准控件,可以在Azure机器学习中进行文本分类。在免费的Azure机器账户方面有一些限制,如控制的最大数量等。
