

在2021年的一半多时间里,我一直在对kentcdodds.com进行全面重写。你是在这个网站的重写中读到这篇文章的!你在使用黑暗模式还是光明模式? 你已经登录并选择你的团队了吗?你试着打进呼叫肯特播客了吗?这篇博文不是关于这些和新网站的其他功能,而是关于我如何建立它。在一篇博文中,有太多东西需要深入研究。我只想给你介绍一下我用来为你创造这种体验的技术和库。
如果你还没有读过,请先阅读《介绍新的kentcdodds.com》,以了解这个网站对你作为一个软件工程师的学习和进步所能起到的更高层次的影响。
背景介绍
在我们深入探讨之前,我想先说清楚我的一件事。如果这是一个简单的开发人员的博客组合网站,我的技术选择可能会被贴上过度工程的标签,我也会同意。然而,我想建立一个超越的体验,所以我必须做出深思熟虑的架构决定。我在这个网站上所做的事情,绝对不是用wordpress和CDN就能完成的😆。
如果你是一个正在寻找如何建立个人网站的初学者,这篇博文绝对不是学习这个的地方。如果我想建立一个简单的个人网站,我仍然会使用Remix.run,但我可能会让它运行在netlify的无服务器功能上,并将内容写成markdown,这在Remix中具有内置支持。这样就会大大简化了。
但是,这并不是kentcdodds.com的目的。如果你对如何使用现代工具有效地建立一个可维护的网站感兴趣,而且尽管每个用户得到的内容对他们来说完全是独一无二的,但在全世界范围内都很快速,那么请继续。
哦,还有一件事要告诉大家这个网站能做什么。
统计资料概述
首先,为了让你了解我们在这里谈论的规模。所以这里有一些统计数字。
在写这篇文章的时候(2021年10月),以下是cloc统计数字。
$ npx cloc ./app ./types ./tests ./styles ./mocks ./cypress ./prisma ./.github
266 text files.
257 unique files.
15 files ignored.
github.com/AlDanial/cloc v 1.90 T=0.16 s (1601.9 files/s, 194240.7 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
TypeScript 219 2020 583 21582
CSS 10 198 301 4705
JSON 7 0 0 609
YAML 2 43 13 232
SQL 7 20 25 52
JavaScript 4 2 3 42
Markdown 1 0 0 2
TOML 1 0 2 1
-------------------------------------------------------------------------------
SUM: 251 2283 927 27225
-------------------------------------------------------------------------------
为了了解我在这个网站上的内容的数量,这里有一个字数:
$ find ./content -type f | xargs wc -w | tail -1
280801 total
这比前三本《哈利-波特》的总和还要多。
而把《与肯特的谈话》四季的内容加起来,大约有35个小时的内容,加上全新的《呼叫肯特》播客中不断增加的3个小时的内容,顺便说一下,这也比听吉姆-戴尔读前三本《哈利-波特》要多(除非你像我一样以3倍的速度听#subtlebrag 🙃)。
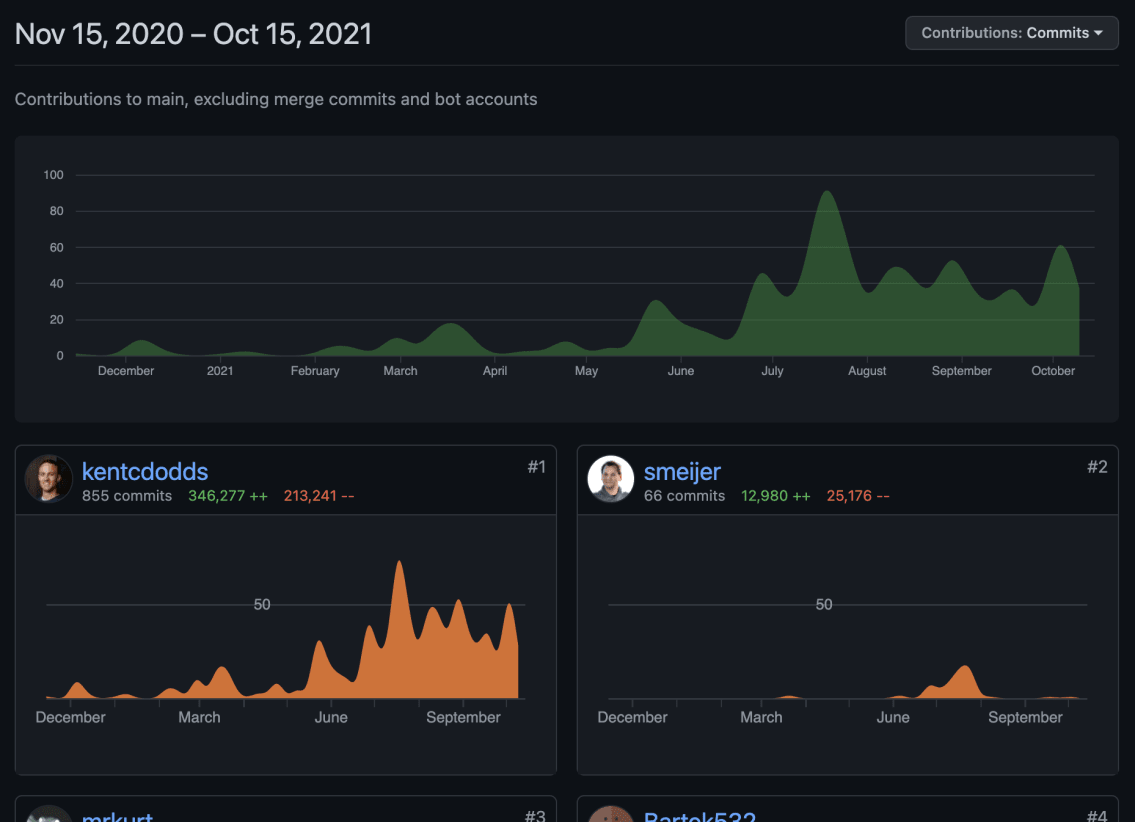
27000行代码并不像你的工作项目,有半打团队在过去8年中一直在贡献代码或什么,但它也不像你的博客组合网站。这是一个合法的全栈网络应用,有数据库、缓存、用户账户等。我相当有信心,这是目前最大的Remix应用。
这不是我一个人的功劳。你可以查看学分页,了解贡献者的详情。我是主要的代码贡献者,我为网站做了所有的架构决定(和错误? 只有时间能证明😅)。
第一次提交是在2020年11月,大部分的开发是在过去的4-5个月里进行的。到目前为止有~945个提交🤯。
架构概述
部署管线
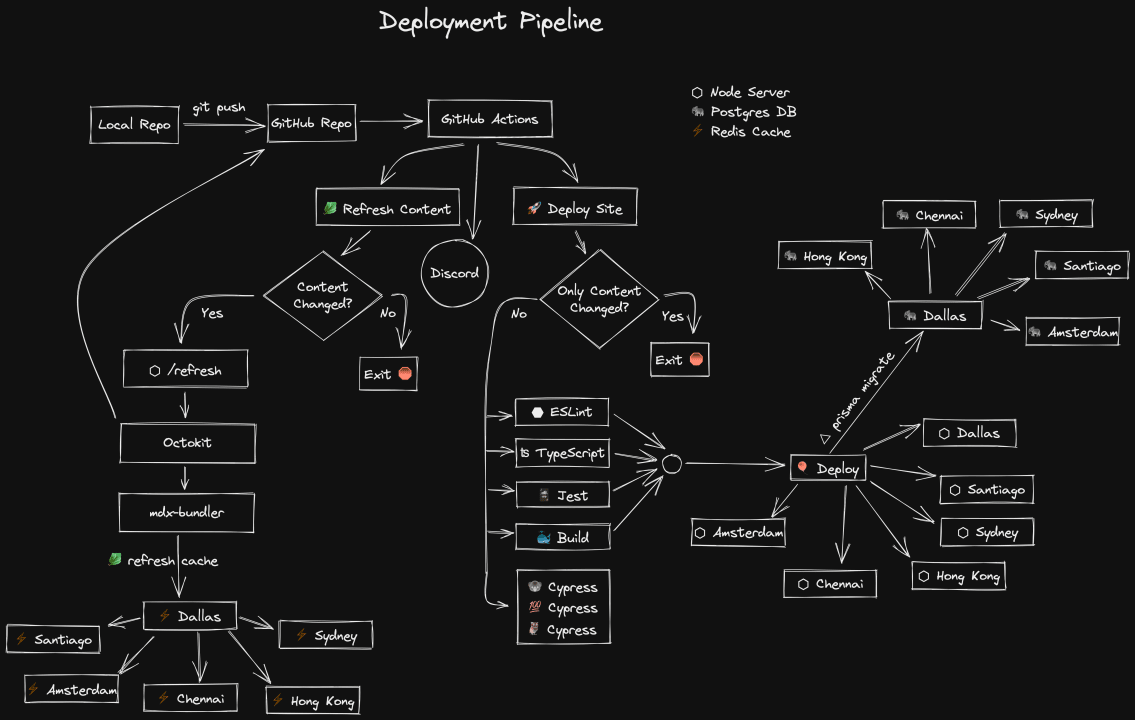
我认为,描述一个应用程序的部署方式对整体架构有很大的指导意义。上面的Excalidraw图直观地描述了它。请允许我也以书面形式描述一下。
首先,我提交一个变化到本地的 repo。然后我把我的改动推送到(开源)GitHub仓库。在这里,我有两个GitHub动作,每次推送到main 分支时都会自动运行。
Discord "圆圈表示我已经为 Discord 安装了一个 GitHub webhook,所以每次成功/失败都会在 Discord 频道中发出消息,这样我就可以随时了解事情的进展情况。
GitHub行动。🥬 刷新内容
第一个GitHub动作叫做"🥬刷新内容",目的是刷新任何可能已经改变的内容。在描述它的作用之前,让我解释一下它解决的问题。kentcdodds.com的前一个版本是用Gatsby编写的,由于Gatsby的SSG性质,每次我想做一个内容的改变,我都必须重建我的整个网站(这可能需要10-25分钟)。
但是现在我有一个服务器,而且我使用的是SSR,我不需要等待完全重建来刷新我的内容。我的服务器可以通过GitHub的API直接访问GitHub上的所有内容。问题是,这给我的博客文章的每次请求都增加了很多开销。再加上编译MDX代码的时间,你就得到了一个非常慢的博客。所以我给自己准备了一个Redis缓存来处理这一切。现在的问题是缓存的问题:失效。我需要确保当我对某些内容进行更新时,Redis的缓存会被刷新。
这就是第一个GitHub动作所做的。首先,它确定在正在建立的提交和上次刷新的提交之间发生的所有内容变化(该值存储在 Redis 中,我的服务器为我的动作暴露了一个端点来检索它)。如果有任何改变的文件在./content 目录中,那么这个动作就会向我服务器上的另一个端点发出一个经过验证的POST请求,其中包含所有被改变的内容文件。然后我的服务器从GitHub API检索所有内容,重新编译MDX页面,并将更新推送到Redis缓存,Fly.io会自动传播到其他区域。
这将过去需要10-25分钟的时间减少到8秒。这也为我节省了计算资源,因为修复内容中的一个错别字不需要重建/重新部署/破坏整个网站的缓存。
我意识到使用GitHub作为我的内容管理系统有点奇怪,但像你这样优秀的人一直在为我的开源内容做出改进,我对此表示感谢。所以把东西放在GitHub上,这就可以继续下去。(注意每个帖子底部的编辑链接)。
GitHub的行动。🚀 部署
第二个GitHub动作是部署网站。首先,它要确定所做的改动是否可以先部署。如果唯一改变的是内容,那么由于有了刷新内容的动作,就没有必要费力地重新部署了。我在老网站上的绝大多数提交都是仅有内容的改动,所以这有助于拯救树木🌲🌴🌳。
一旦确定我们有可部署的修改,那么我们就会平行地启动多个步骤。
- ⬣ ESLint。对项目的简单错误进行提示
- ʦ TypeScript。类型检查项目的类型错误
- 🃏 Jest。运行组件和单元测试
- ⚫️ Cypress。运行端到端的测试
- 🐳 Build。构建docker镜像
Cypress步骤通过将我的E2E测试分割成三个独立的容器而进一步并行化,这些容器之间分割测试以尽可能快地运行它们。
你可能会注意到,在Cypress步骤中没有箭头出来。这是故意的,也是暂时的。目前,如果E2E测试失败,我不会使构建失败。到目前为止,我并不担心部署的东西是坏的,我不想因为我不小心弄坏了0个用户的东西而耽误了部署,因为他们希望事情能正常进行。E2E测试也是部署管道中最慢的部分,我想让事情快速部署。最终我可能会更关心我是否破坏了网站,但现在我宁愿让事情部署的更快。我确实知道这些测试什么时候失败。
一旦ESLint、TypeScript、Jest和Build都成功完成,那么我们就可以进入部署步骤了。在我这边,这一步很简单。我只需使用Fly CLI来部署在构建步骤中创建的docker容器。在那里,Fly会处理剩下的事情。它在我为Node服务器配置的每个地区启动docker容器。达拉斯、圣地亚哥、悉尼、香港、钦奈和阿姆斯特丹。当它们准备好接收流量时,Fly将流量切换到新的实例,然后关闭旧的实例。如果在任何地区出现启动失败,它会自动回滚。
此外,这一步的部署使用了prisma的migrate功能来应用我在上次迁移后创建的任何迁移(它在我的Postgres数据库中存储了上次迁移的信息)。Prisma在我的Postgres集群的Dallas实例上执行迁移,Fly自动将这些变化即时传播到所有其他区域。
这就是当我说:git push 或点击 "合并 "按钮时所发生的事情😄
数据库连接
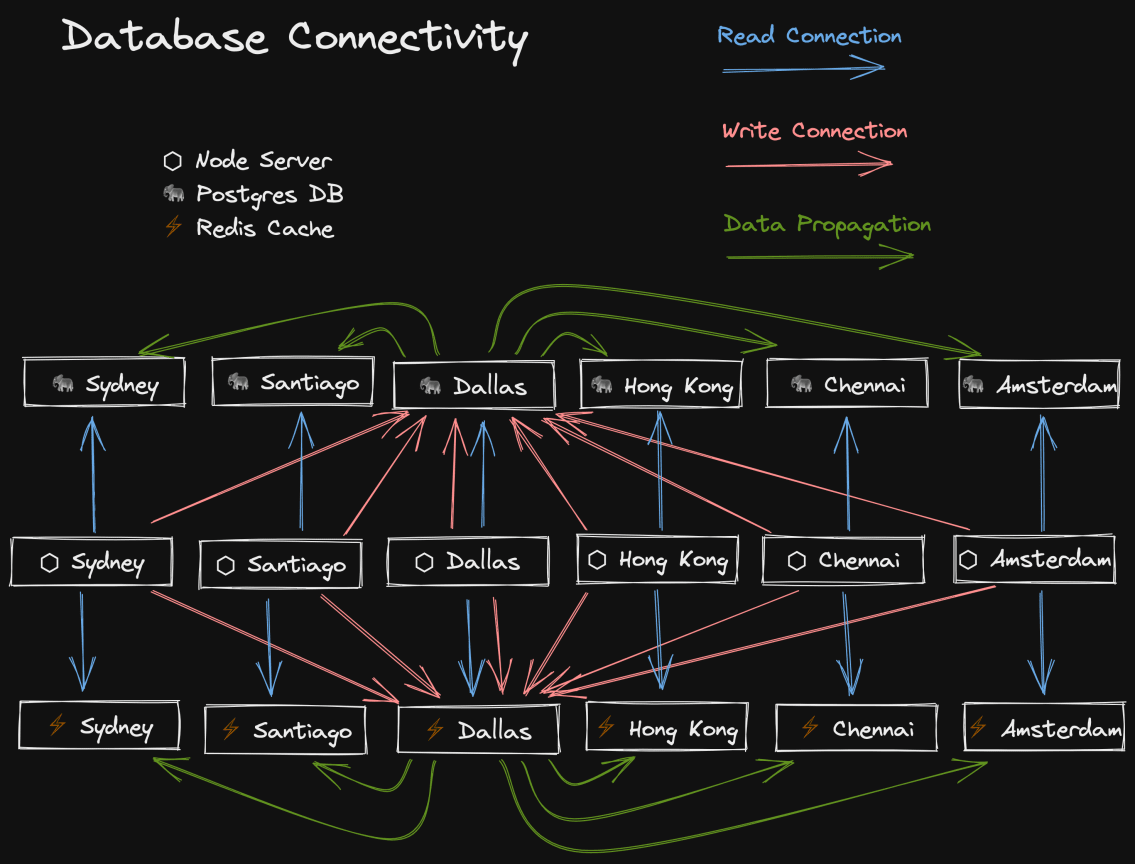
Fly.io最酷的部分之一(也是我选择Fly而不是其他Node服务器主机的原因)是能够将你的应用程序部署到世界各地的多个地区。我根据之前网站的分析结果选择了6个地区,但他们还有很多地区。
将Node服务器部署到多个地区只是故事的一部分,要真正获得主机托管的网络性能优势,你还需要将数据放在附近。因此,Fly也支持在每个地区托管Postgres和Redis集群。这意味着当柏林的授权用户访问The Call Kent Podcast时,他们会访问离他们最近的服务器(阿姆斯特丹),这将查询位于同一地区的Postgres数据库和Redis缓存,使整个体验非常快,无论你在世界何处。
更重要的是,我不需要做厂商锁定的权衡。在任何时候,我都可以把我的玩具带回家,在其他支持部署Docker的地方托管我的网站。这就是为什么我没有采用Cloudflare Workers和FaunaDB这样的解决方案。此外,我不需要根据这些服务的限制来改造/限制我的应用程序。我对Fly非常满意,也不指望很快离开。
但这并不意味着这一切都是免费的(没有什么是免费的)。所有这些多地区的部署都伴随着一致性的问题。我有多个数据库,但我不想按地区划分我的应用程序。所有这些数据库中的数据应该是一样的。那么,我如何确保一致性呢?好吧,我们选择一个区域作为我们的主区域,然后使所有其他区域成为只读。是的,所以柏林的用户将不能写到阿姆斯特丹的数据库。但是不用担心,我的Node服务器的所有实例都会与最近的区域建立一个读连接,所以读(到目前为止最常见的操作)是快速的,然后它们也会与主要区域建立一个写连接,所以写也可以工作。一旦主区域发生更新,Fly就会自动并立即将这些变化传播到所有其他区域。 这非常非常快,而且效果相当好
Fly使这样做很容易,我对它超级满意。这就是说,这还产生了一个我们需要处理的问题。
Fly请求回放
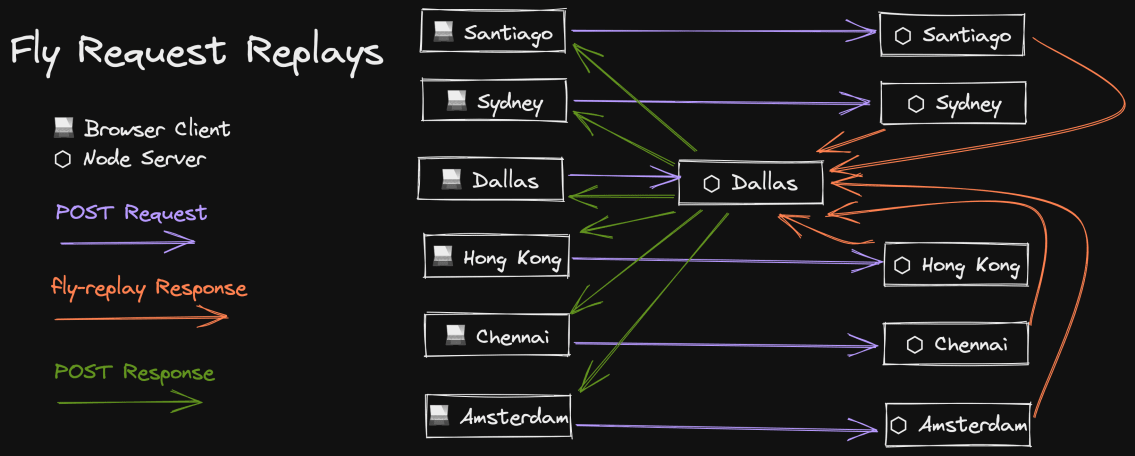
我用来使多区域部署超快的读/写连接的一个问题是,如果我们在柏林的朋友向数据库写数据,然后读取他们刚刚写的数据,那么他们有可能在Fly完成传播更新之前读取旧数据。数据传播通常以毫秒为单位,但在数据量较大的情况下(比如你向The Call Kent Podcast提交录音),很可能你的下一次读取会超过Fly。
避免这个问题的一个方法是确保一旦你完成了写,剩下的请求就会对主数据库进行读取。 不幸的是这使得代码有点复杂。
Fly支持的另一种方法是向主区域 "重放 "一个请求,其中读和写的连接都在主区域。你可以通过发送一个带头文件fly-replay: REGION=dfw的响应,Fly 会拦截这个响应,防止它返回给用户,并将完全相同的请求重放到指定的区域(dfw 是达拉斯,是我的主区域)。
因此,我在我的express应用中设置了一个中间件,简单地自动重放所有非GET请求。这确实意味着这些请求对我们在柏林的朋友来说需要更长的时间,但同样,这些请求并不经常发生,而且说实话,我也不知道有什么更好的选择🙃。
我对这个解决方案真的很满意!
用MSW进行本地开发
当我在本地开发时,我通过一个简单的docker-compose.yml ,让我的postgres和redis数据库在docker容器中运行。但我也与一堆第三方的API进行交互。截至本文撰写之时(2021年9月),我的应用程序与以下第三方API一起工作。
api.github.comoembed.comapi.twitter.comapi.tito.ioapi.transistor.fms3.amazonaws.comdiscord.com/apiapi.convertkit.comapi.simplecast.comapi.mailgun.netres.cloudinary.comwww.gravatar.com/avatarverifier.meetchopra.com
唷!😅 我非常相信能够完全脱机工作。在没有网络连接的情况下,到山上去仍能在你的网站上工作,这很有趣(当我打字时,我正在没有网络的飞机上)。但是有这么多的第三方API,这怎么可能呢?
很简单。我用MSW来模拟它!
MSW是一个在浏览器和节点中模拟网络请求的神奇工具。对我来说,100%的第三方网络请求都发生在服务器上的Remix加载器中,所以我只在节点服务器中设置了MSW。我喜欢MSW的原因是,它对我的代码库完全没有干扰性。我让它运行的方法很简单。下面是我如何启动我的服务器。
node .
这是我如何在启用了mocks的情况下启动它。
node --require ./mocks .
就这样了。./mocks 目录保存了我所有的MSW处理程序,并初始化了MSW来拦截服务器发出的HTTP请求。现在我不想说为所有这些服务写模拟很容易,它有相当多的代码,花了我一些时间。但它真的帮助我保持了生产力。我的模拟比API快得多,而且一点也不依赖我的互联网连接。 这是一个巨大的胜利,我强烈推荐它。
对于我所模拟的几个API,我只是用faker.js ,创建符合我为这些API编写的类型的随机假数据。但是对于GitHub的API,即使我没有连接到互联网,我也知道响应应该是什么,因为我确实是在我要请求内容的仓库里工作!所以我的GitHub API模拟实际上是在为GitHub的API做准备。所以我的GitHub API模拟程序实际上是在读取文件系统,并以实际内容进行响应。这就是我在本地处理内容的方式。我不需要在我的源代码中做任何花哨的事情。就我的应用程序而言,我只是对内容进行网络请求,但MSW拦截它,让我用文件系统上的内容进行响应。
为了更进一步,当文件发生变化时,Remix会自动重新加载页面,而且我已经设置好了,每当内容发生变化时,Redis缓存会自动更新(是的,我也在本地使用Redis缓存),然后我触发Remix重新加载页面。如果你看不出来,我认为这整个事情是超级酷的。
因为我用MSW设置了本地工作,所以我可以让我的E2E测试使用同样的东西并保持弹性。如果我想针对真正的API运行我的E2E测试,那么我所要做的就是不要 --require ./mocks ,所有的东西都会打到真正的API。
MSW对我来说是一个巨大的生产力和信心的提升。
使用Redis/LRU进行缓存
正如前面的架构图所描述的,我把我的Redis缓存托管在Fly.io。它是惊人的。但我已经建立了自己的小抽象来与redis互动,有一些有趣的特质,我认为值得讨论。
首先,问题。我希望我的网站速度超快,但我也想在每个请求中做一些需要时间的事情。我想做的一些事情甚至可以说是缓慢或不可靠的。所以我使用Redis来缓存东西。这可以把需要350毫秒的事情减少到5毫秒。然而,随着缓存的出现,缓存的失效也变得复杂起来。我已经描述了我是如何处理我的内容的,但我的缓存远不止这些。我的大部分第三方API都被缓存了,甚至我的一些Postgres查询结果也被缓存了(Postgres是相当快的,但在我的博客上,我在每个页面都执行了~30次查询)。
也不是所有的东西都被缓存在Redis中,有些东西是通过lru-cache 模块缓存的(lru代表 "最少最近使用",帮助你的缓存避免内存不足的错误)。我将内存中的LRU缓存用于非常短暂的缓存值,如postgres查询。
由于有这么多东西需要被缓存,所以需要一个抽象来使失效过程更加简单和一致。我没有耐心去寻找一个适合我的库,所以我就建立了自己的库。
这里是API。
type CacheMetadata = {
createdTime: number
maxAge: number | null
}
// it's the value/null/undefined or a promise that resolves to that
type VNUP<Value> = Value | null | undefined | Promise<Value | null | undefined>
async function cachified<
Value,
Cache extends {
name: string
get: (key: string) => VNUP<{
metadata: CacheMetadata
value: Value
}>
set: (
key: string,
value: {
metadata: CacheMetadata
value: Value
},
) => unknown | Promise<unknown>
del: (key: string) => unknown | Promise<unknown>
},
>(options: {
key: string
cache: Cache
getFreshValue: () => Promise<Value>
checkValue?: (value: Value) => boolean
forceFresh?: boolean | string
request?: Request
fallbackToCache?: boolean
timings?: Timings
timingType?: string
maxAge?: number
}): Promise<Value> {
// do the stuff...
}
// here's an example of the cachified credits.yml that powers the /credits page:
async function getPeople({
request,
forceFresh,
}: {
request?: Request
forceFresh?: boolean | string
}) {
const allPeople = await cachified({
cache: redisCache,
key: 'content:data:credits.yml',
request,
forceFresh,
maxAge: 1000 * 60 * 60 * 24 * 30,
getFreshValue: async () => {
const creditsString = await downloadFile('content/data/credits.yml')
const rawCredits = YAML.parse(creditsString)
if (!Array.isArray(rawCredits)) {
console.error('Credits is not an array', rawCredits)
throw new Error('Credits is not an array.')
}
return rawCredits.map(mapPerson).filter(typedBoolean)
},
checkValue: (value: unknown) => Array.isArray(value),
})
return allPeople
}
这有很多选项😶,但别担心,我会带你完成这些选项。让我们从通用类型开始。
Value指的是应该从缓存中存储/检索的值Cache是一个具有 (用于记录),以及 , , 和 方法的对象。namegetsetdelCacheMetadata是指与值一起被保存的信息,用于确定值何时被刷新。
现在说说选项。
key是该值的标识符。cache是要使用的缓冲区。getFreshValue是实际检索该值的函数。如果我们没有缓存,这就是我们每次都要运行的东西。一旦我们得到新的值,这个值就会被设置在 。cachekeycheckValue是一个验证从 / 检索的值是否正确的函数。有可能我对 ,改变了 ,如果缓存中的值不正确,那么我们要强制调用 ,以避免运行时类型错误。我们也用它来检查我们从 得到的东西是否正确,如果不正确,我们就抛出一个有用的错误信息(绝对比类型错误好)。cache``getFreshValuegetFreshValueValuegetFreshValue``getFreshValueforceFresh允许你跳过查看缓存,即使值还没有过期,也会调用 。如果你提供了一个字符串,那么它将通过 来分割该字符串,并检查 是否包含在该字符串中。如果是的话,我们将调用 。这在你调用一个调用其他缓存函数的缓存函数时很有用(比如检索所有博客mdx文件的函数)。你可以调用那个函数,只刷新getFreshValue,keygetFreshValue一些缓存值,而不是所有的缓存。request用于确定 的默认值。如果请求的查询参数是 ,而用户的角色是 (所以......只有我),那么 将默认为 。这使得我可以手动刷新任何页面上所有资源的缓存。不过我不需要经常这样做。你也可以提供一个 分离的缓存键值来强制只刷新forceFresh?fresh``ADMINforceFreshtrue,这些缓存值。fallbackToCache如果我们试图 (所以我们跳过了缓存),并且获取新的值失败了,那么我们可能想回退到缓存的值,而不是抛出一个错误。这可以控制这一点,并默认为 。forceFresh``truetimings和 用于我的另一个工具,用于跟踪事情所需的时间,然后在 头部发送回来(对于识别性能瓶颈很有用)。timingsTypeServer-TimingmaxAge控制在尝试自动刷新之前,将缓存值保留多长时间。
当从缓存中读取值时,我们立即返回该值以保持快速。在发送请求后,我们确定该缓存值是否过期,如果过期,那么我们再次调用cachified ,并将forceRefresh 设置为true 。
这样做的效果是,没有用户真正需要等待getFreshValue 。这样做的好处是,在过期后最后一个请求数据的用户会得到旧值。我认为这是一个合理的权衡。
我对这个抽象很满意,有可能我最终会把博文的这一部分复制/粘贴到README.md ,作为未来的一个开源项目😅。
用Cloudinary进行图像优化
好了,伙计们...Cloudinary是不可思议的。这个网站上的所有图片都托管在Cloudinary上,然后以适合你的设备的完美尺寸和格式传送到你的浏览器。它花了一点功夫(也花了很多钱......Cloudinary并不便宜)来实现这个魔法,但它为你节省了大量的互联网带宽,并使图像的加载速度大大加快。
我的Gatsby网站花了这么长时间建立的原因之一是,每次我运行建立,Gatsby不得不为我所有的图片生成所有的尺寸。Gatsby团队帮我建立了一个持久的缓存,但如果我需要破坏这个缓存,那么我就必须运行Netlify几次(它会超时)来再次填充缓存,这样我就可以再次部署我的网站😬。
有了Cloudinary,我就没有这个问题了。我只是上传照片,在我的mdx中引用cloudinary ID,然后我的网站为sizes 和srcset ,为<img /> 标签产生正确的道具。因为Cloudinary允许在URL中进行转换,我能够生成一个完全符合我对这些道具所需尺寸的图像。
此外,我正在使用Cloudinary来生成网站上的所有社交图片,所以它们可以是动态的(有文本/自定义字体和一切)。我也在为The Call Kent Podcast的图片做同样的工作。这很疯狂。
我正在做的另一件很酷的事情,你可能已经注意到了,在博客文章中,我在服务器上为横幅图片提出了一个请求,这个图片只有blur ,宽度为100px 。然后我将其转换为base64字符串。这与其他关于文章的元数据一起被缓存起来。然后,当我对文章进行服务器渲染时,我将base64模糊的图片按比例进行服务器渲染(我还使用CSS的backdrop-filter,使其在放大后变得更加平滑),然后在加载完成后淡入全尺寸图片。我对这种方法非常满意。
Cloudinary让我大开眼界,我很乐意为我从它那里得到的东西支付费用。
用mdx-bundler进行MDX编译
自从我离开Medium后,我就一直用MDX来写我的博客文章。我真的很喜欢,我可以很容易地在我的博文中间有互动的部分,而不需要在我的网站代码中以任何特殊的方式处理它们。
当我从Gatsby的MDX构建时编译转移到Remix的按需编译时,我需要找到一种方法来进行按需编译。 就在这个时候,xdm (一个更快和无运行时间的MDX编译器)被创建。不幸的是,它只是一个编译器,而不是一个捆绑器。 如果你在你的MDX中导入组件,你需要确保这些导入在你运行编译后的代码时能够解决。我决定我需要的不仅仅是一个编译器。我需要一个捆绑器。
没有这样的捆绑器存在,所以我做了一个。mdx-bundler.我从rollup开始,然后试了一下esbuild,结果被吓了一跳。它的速度快得出奇(尽管还不足以按需捆绑,所以我对编译后的版本进行了缓存)。
正如人们所期望的那样,我确实有几个统一的插件(re remark/rehype),在MDX的编译过程中为我自动处理一些事情。我有一个用于自动添加亚马逊和蛋头链接的联盟查询参数。我还有一个用于将推文链接转换为完全自定义的twitter嵌入(比使用twitter widget快),还有一个用于将蛋头视频链接转换为视频嵌入。我还有一个自定义的(从Ryan Florence的一个秘密包中借来的),用于基于Shiki的语法高亮,还有一个用于优化内联云图。
统一真的很强大,我喜欢用它来处理我基于markdown的内容。
与Prisma的数据库互动
好了,我的朋友们。让我们来谈谈Prisma。我不是一个数据库人员...完全不是。所有后台的东西都在我的工作范围之外。有趣的是,Remix让后台变得如此平易近人,以至于我在过去几个月里所做的大部分工作都是后台工作。不仅仅是查询Postgres,还包括数据迁移。Prisma让它变得如此平易近人,这确实令人惊讶。所以让我们来谈谈这些事情。
迁移
使用Prisma,你通过一个schema.prisma 文件来描述你的数据库模型。如果你需要改变你的模式,你可以运行prisma migrate dev --name <descriptive-name> ,prisma将生成必要的SQL查询,为你的模式变化进行表更新。
如果你小心谨慎,你可以实现零停机时间的迁移。 零停机时间的迁移并不是prisma独有的,但是prisma确实让我创建这些迁移变得更加简单,因为我已经很多年没有使用过SQL了,而且也不喜欢它 😬 在我的网站开发过程中,我有7次迁移,其中两次是对模式的修改。所有的人中,我能够做到这一点,就足以说明问题了😅。
TypeScript
schema.prisma 文件也可以用来为你的数据库生成类型,这就是事情变得非常棒的地方。下面是一个快速查询的例子。
const users = await prisma.user.findMany({
select: {
id: true,
email: true,
firstName: true,
},
})
// This is users type. To be clear, I don't have to write this myself,
// the call above returns this type automatically:
const users: Array<{
id: string
email: string
firstName: string
}>
如果我想得到team ,那么。
const users = await prisma.user.findMany({
select: {
id: true,
email: true,
firstName: true,
team: true, // <-- just add the field I want
},
})
现在突然间,users 阵列是。
const users: Array<{
id: string
email: string
firstName: string
team: Team
}>
哦,如果我还想得到这个用户读过的所有帖子呢?我需要一些graphql解析器的魔法吗?不,不需要。看看这个。
const users = await prismaRead.user.findMany({
select: {
id: true,
email: true,
firstName: true,
team: true,
postReads: {
select: {
postSlug: true,
},
},
},
})
现在我的users 阵列是。
const users: Array<{
firstName: string
email: string
id: string
team: Team
postReads: Array<{
postSlug: string
}>
}>
现在这就是我所说的了!有了Remix,我可以很容易地在我的loader 中直接查询,然后在我的组件中获得这些类型的数据。
type LoaderData = Await<ReturnType<typeof getLoaderData>>
async function getLoaderData() {
const users = await prismaRead.user.findMany({
select: {
id: true,
email: true,
firstName: true,
team: true,
postReads: {
select: {
postSlug: true,
},
},
},
})
return {users}
}
export const loader: LoaderFunction = async ({request}) => {
return json(await getLoaderData())
}
export default function UsersPage() {
const data = useLoaderData<LoaderData>()
return (
<div>
<h1>Users</h1>
<ul>
{/* all this auto-completes and type checks!! */}
{data.users.map(user => (
<li key={user.id}>
<div>{user.firstName}</div>
</li>
))}
</ul>
</div>
)
}
如果我决定在客户端不需要某些数据,我只需更新prisma查询,TypeScript会确保我没有错过任何东西。这实在是太棒了。
Prisma让我这个前端开发者感到有能力直接与数据库一起工作。
用神奇的链接进行认证
不久前,我在推特上发表了一些话,我正在吃...
以下是应用程序中认证的唯一合理选择:1.使用云提供商进行认证 2.有一个团队专门负责公司应用程序的认证 3.使用HTTP基本认证,因为安全问题对你来说显然并不重要 🤷♂️
是的,没错...。我在这个网站上手工制作了自己的认证。但我有一个很好的理由!还记得上面所有关于通过将节点服务器和数据库放在离用户很近的地方使事情变得超快的讨论吗?好吧,如果我使用一个认证服务,我就会使所有的工作付诸东流。每一个请求都必须到提供商支持的地区去验证用户的登录状态。 那将是多么令人失望的事情啊?
就在我研究认证问题的时候,Ryan Florence做了一些直播,他为自己的Remix应用实现了认证。这看起来并不复杂。他很好心地给了我一个所需的概要,我在一天之内就完成了大部分的工作。
对我帮助很大的是使用魔法链接进行认证。 这样做意味着我不需要担心存储密码或处理密码重设/更改的问题。但这并不只是一个自私/愚蠢的决定。我强烈地感觉到,对于像我这样的应用程序,魔法链接是最好的认证系统。请记住,几乎每一个其他应用程序都有一个类似于 "魔法链接 "的认证系统,即使它是隐含的,因为 "重置密码 "流程会通过电子邮件给你一个链接来重置你的密码。因此,它的安全性肯定不会降低。事实上,实际上更安全,因为没有密码可以丢失。
哦,在你说之前。
但是,如果没有密码,我就不能使用我的密码管理器,我就会忘记我的30个电子邮件地址中的哪一个是用来在你的网站上注册的!"。
你的密码管理器肯定可以存储只有电子邮件地址而没有密码的登录信息。做到这一点。
好的,让我们看一下认证流程图。
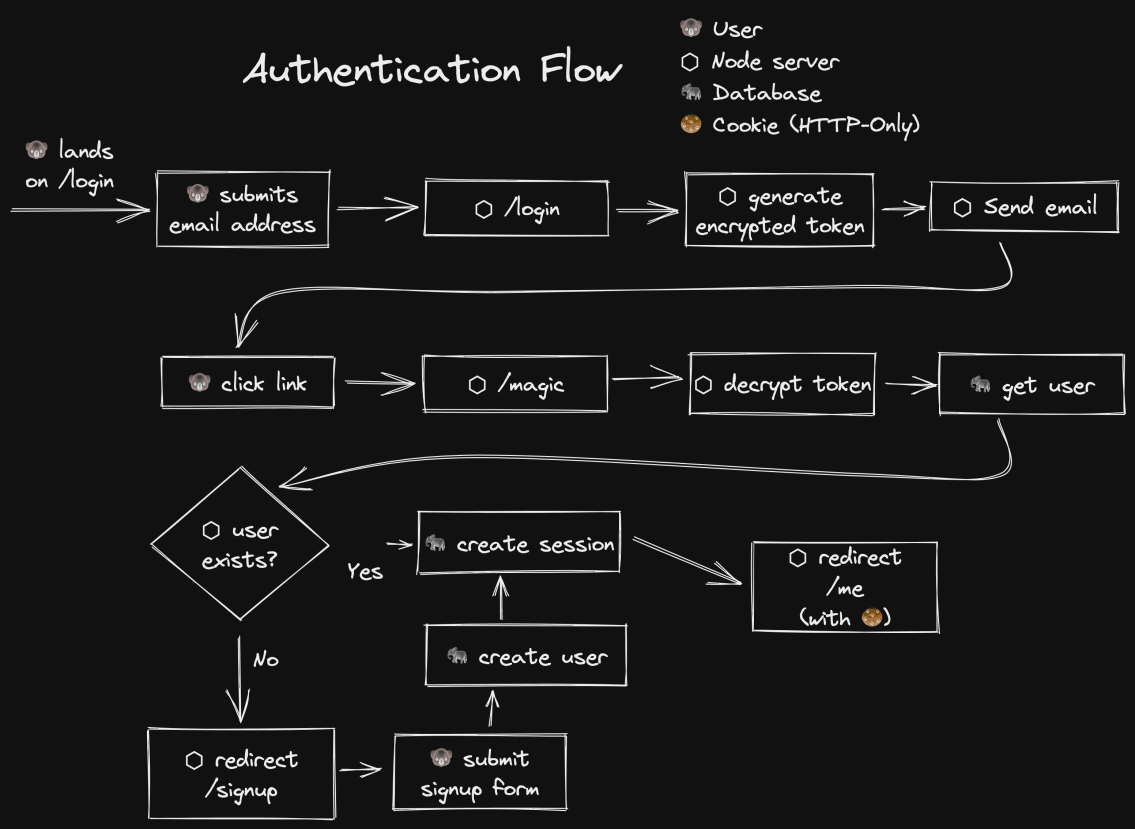
在这个流程中,我想指出的是,在用户真正注册之前,没有与数据库的互动。另外,注册和登录的流程是一样的。这对我来说简化了很多事情。
现在,让我们来看看当用户导航到一个认证页面时会发生什么。
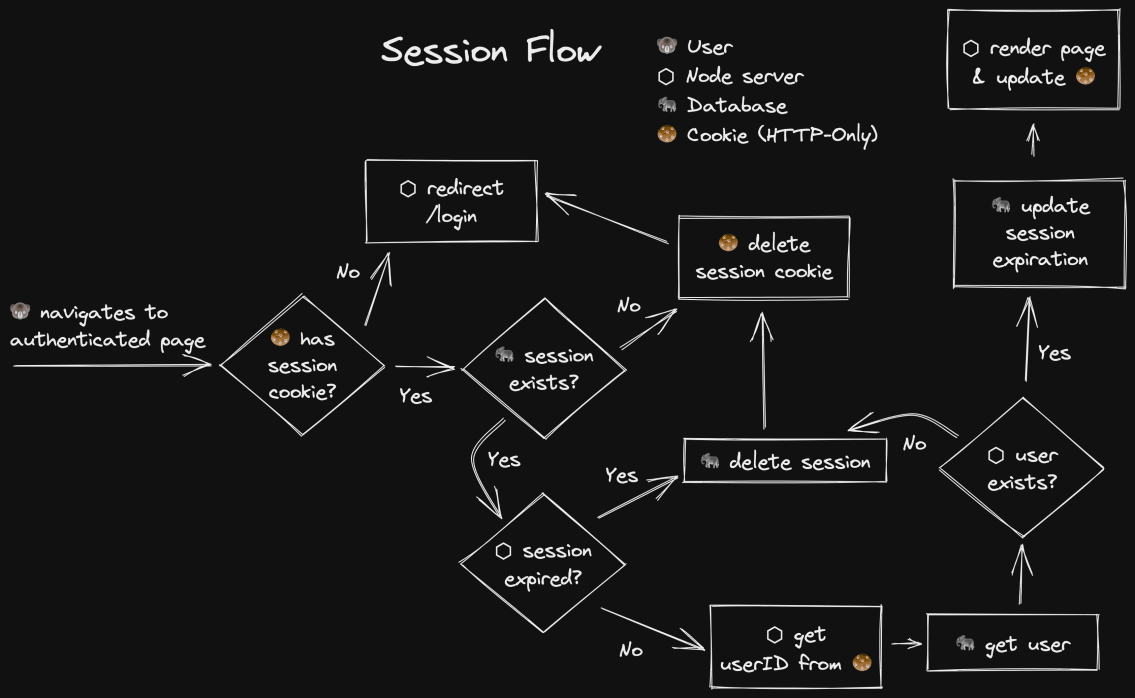
这方面的基本原理非常简单。
- 从会话cookie中获取会话ID
- 从会话中获取用户ID
- 获取用户
- 更新过期时间,以便活跃的用户很少需要重新认证
- 如果其中任何一项失败了,就进行清理和重定向
老实说,这并不像我多年前在其他应用程序中手工操作认证时记得的那样复杂。Remix的cookie会话抽象使它变得更加简单。
混沌

好了,伙计们。在我使用的所有工具中,Remix对我的生产力和网站的性能影响最大。Remix使我能够做所有这些很酷的事情,而不会使我的代码库过于复杂。
未来我肯定会写很多关于Remix的博文,所以请订阅,以了解更多信息。但是,以下是Remix对我来说如此神奇的原因的快速列表。
- 服务器和客户端之间沟通的便利性。数据过度获取不再是一个问题,因为我很容易在服务器代码中过滤出我想要的东西,并在客户端代码中得到我需要的东西。正因为如此,不需要一个巨大而复杂的graphql后端和客户端库来处理这个问题(如果你想的话,你肯定还是可以使用graphql与remix)。这个问题很重要,我将在未来几个月内写很多关于这个问题的博文。
- 我从Remix的网络平台使用中得到的自动性能。这也是一个很大的问题,需要多篇博文来解释。
- 能够为一个特定的路线设置CSS,并且知道我不会与其他路线的CSS发生冲突。👋 告别CSS-in-JS。
- 我甚至不需要考虑服务器缓存,因为Remix为我处理了所有这些(包括突变后)。我所有的组件都可以认为数据已经准备好了。Remix没有实现自己的缓存,而是利用浏览器的缓存,即使在重新加载(或在新标签页中打开一个链接)后,也能使事情变得超快。
- 不用像其他框架那样担心
Layout,从数据加载的角度来看,这给我带来了好处。同样,这将需要一篇博文。
我提到,其中有几项需要写一篇博文。不是因为你有什么需要学习的东西来利用这些东西,而是要向你解释,你不需要。这就是Remix的工作方式。我花更少的时间考虑如何使事情运转,而更多的时间意识到我的应用程序的能力不受限于我的框架,而是受限于我的✨想象力✨。
结论
我无法告诉你我从建立这个网站中学到了多少东西。这是一个巨大的乐趣,我很高兴能把我的学习成果写进博客文章和研讨会,教你我是如何做这些事情的具体细节,这样你也可以做。事实上,我已经为你安排了一些研讨会!现在就去买票吧。我期待着在那里见到你。保重,保持良好的工作。
