

让我们从一个故事开始:当我的专业领域之外的人问我在做什么时,我说*"我建网站"*。如果他们感到好奇,我会补充说这些网站相当复杂。如果他们继续问,我就试着用一些例子来阐述。Facebook、Spotify、Twitter。这并不是说我为这些公司工作,但我希望这能让他们对 "我建造什么样的网站 "有一个好印象。然而,大多数情况下,对话不会超出 "我建造网站 "的范围,我对此无所谓。
如今,一个网站并不等同于另一个网站。网站的范围从一个产品的营销网站到一个全面的社会媒体平台。作为一个刚接触网络开发的人,你要掌握整个格局并不容易:一开始是一个传统的简单网站,有HTML和CSS,从网络服务器返回,后来变成一个复杂得多的全栈应用程序,有复杂的客户-服务器通信和状态管理。
如果你已经在学习HTML、CSS和JavaScript,而你对网站和网络应用的基础知识并不了解,那么这本综合指南就是为你准备的。
在这个演练中,我想向你展示网络开发的演变,从一个简单的网站到一个复杂的网络应用,在这里我们澄清了一些术语,如:
- 客户端/服务器
- 前端/后端
- 网站/网络应用程序
- 客户端应用/服务器应用
- REST/GraphQL
- 网络服务器/应用服务器
- 服务器端渲染 vs 客户端渲染
- 服务器端路由 vs 客户端路由
- 单页应用与多页应用
- 代码拆分、懒惰加载、树状晃动......
- 全堆栈应用
- 静态网站生成
- BaaS, PaaS, IaaS, ...
根据你目前作为网络开发者的水平,我鼓励你在阅读本指南时随时休息一下,因为它的内容相当广泛,对初学者来说可能有点不知所措,特别是在接近尾声时。让我们开始吧...
一个传统的网站
如果你正在学习网络开发,你很可能会从一个用HTML和CSS构建的传统网站开始。一个没有样式(CSS)和没有任何逻辑(JavaScript)的网站只是HTML。

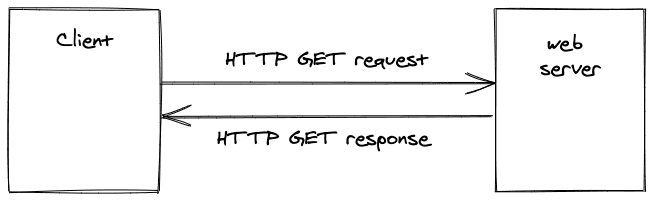
如果你在笔记本电脑或智能手机上的浏览器(如火狐)中导航到一个特定的URL,就会向负责该URL的网络服务器发出请求。如果网络服务器能够将该请求与一个网站相匹配,那么它就将该网站的HTML文件提供给你的浏览器。
为了向浏览器传输网站,HTTP被用作客户端和网络服务器之间的请求和响应的通信协议。这就是为什么在每个URL前面都有 "http "的原因。
客户端和服务器之间的通信是同步的,这意味着客户端向服务器发送一个请求,并等待服务器的响应。你的网站不会立即显示出来,因为从客户端向网络服务器发送请求和从网络服务器接收响应都需要时间。
一个HTTP请求有四个基本的HTTP方法。GET、POST、PUT和DELETE。HTTP的GET方法是用来读取资源的,而其余的方法是用来写资源的--资源可以是任何东西,从HTML到JSON。所有这四种方法都可以被抽象为臭名昭著的CRUD操作。创建、读取、更新和删除。
Create -> HTTP POSTRead -> HTTP GETUpdate -> HTTP PUTDelete -> HTTP DELETE
在我们的例子中,一个网站是通过在浏览器中访问一个URL而从网络服务器提供给客户端的,浏览器执行HTTP GET方法,从网络服务器上读取一个HTML文件。
客户端和服务器之间有什么区别?
客户端是一个消费服务器的实体。它要么从服务器上读取资源,要么将资源写到服务器上。对于一个传统的网站,客户端是你的浏览器。如果你在浏览器中导航到一个特定的URL,你的浏览器就会与服务器通信,请求资源(如HTML)以显示一个网站。然而,客户端不需要是浏览器(如cURL)。
服务器是一个为客户提供服务的实体。在传统意义上的网站中,服务器对客户端的请求做出反应,或者从HTTP GET请求中回复资源(如HTML、CSS、JavaScript),或者从HTTP POST、PUT、DELETE请求中确认操作。流行的网络服务器,是一种特殊的服务器,有NGINX或Apache。

可以说,没有服务器就没有客户,没有客户就没有服务器。它们一起工作,尽管它们不需要在同一个地方。例如,你机器上的浏览器在你的本地位置(如德国的柏林),而向你提供网站的网络服务器在远程位置(如德国的法兰克福)运行。服务器--也就是另一台计算机--通常位于你本地机器以外的地方。为了开发一个网络应用程序或网站,你可能也有一个服务器在你的本地机器上运行(见localhost)。

由于客户端不一定需要是你本地机器上的浏览器,它也可以是远程的某个地方。但关于这一点,以后会有更多的介绍。
网络服务器和应用服务器之间有什么区别?
网络服务器提供资源(如HTML、CSS和JavaScript),它们是可以通过HTTP传输的格式。当客户从网络服务器请求资源时,网络服务器通过将资源送回给客户来满足请求。通常情况下,这些资源只是服务器上的文件。如果HTML被发送到客户端,那么客户端(在这种情况下,浏览器)就会解释HTML来渲染它。
相反,应用服务器提供HTML、CSS和JavaScript以外的资源。例如,如果客户端要求以数据友好的格式提供数据,就可以发送JSON。此外,一个应用服务器不受协议的约束。网络服务器主要使用HTTP协议,而应用服务器可以使用其他协议(例如,用于实时通信的WebSockets)。最重要的事实是,一个应用服务器可以在其服务器端有特定编程语言的实现细节(例如,JavaScript与Node.js,PHP,Java,Ruby,C#,Go,Rust和Python)。
网络服务器和应用服务器都可以归类为服务器。因此,你会经常听到人们在谈论服务器时,指的是这两种中的一种。然而,人们常说的服务器是指一台物理计算机,它运行在某个远程的地方,上面运行着一个网络服务器或应用服务器。
还有两个术语你可能会遇到:部署和托管。我将简单介绍一下这些术语:部署描述了在服务器上运行网站的行为,托管描述了从这个服务器上提供网站的持续行为。因此,当在你自己的电脑上开发一个网站时,你必须用localhost URL打开它,这只是意味着你是这个网站的本地主机。
当我改变一个URL的路径时会发生什么?
当我访问一个网址的网站,并在这个域名(如mywebsite.com)周围从一个路径(如/about)导航到另一个路径(/home)时会发生什么?对于一个传统的网站来说,每一个不同的URL都要由客户向网络服务器发出新的请求。
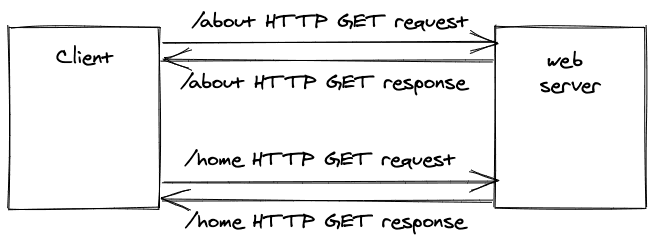
对于每一个URL,都有一个不同的HTTP GET方法被发送到专门的网络服务器来完成请求。当用户在浏览器中访问一个网站的/about 路径(也称为页面或路线)时,例如http://www.mywebsite.com/about ,网络服务器将有关这个URL的所有信息送回给浏览器。这个过程被称为服务器端路由,因为服务器决定在每个URL上向客户端发送哪个资源。你将在后面学习客户端路由的内容。
当我的网站不止是HTML时,会发生什么?
一个现代网站由HTML(结构)、CSS(样式)和JavaScript(逻辑)组成。没有CSS,网站就不会有光泽;没有JavaScript,网站就不会有动态互动。通常情况下,当使用CSS和JavaScript文件时,它们被链接在一个HTML文件中。
<link href="/media/examples/link-element-example.css" rel="stylesheet">
<h1>Home at /home route</p>
<p class="danger">Red text as defined in the external CSS file.</p>
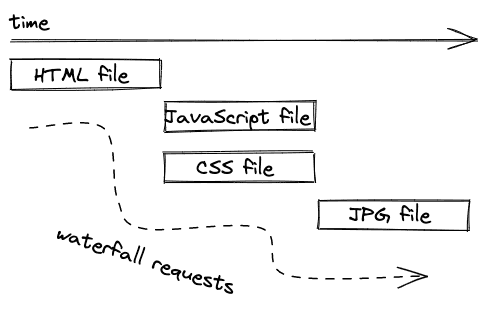
如果浏览器向网络服务器询问一个URL的HTML,网络服务器就会发回HTML文件,其中可能包括链接到其他资源如CSS或JavaScript文件的HTML标签。对于每一个链接,都要向网络服务器发出另一个请求以检索文件。

这些也被称为瀑布式请求,因为一个请求必须等待另一个请求的完成。在我们的例子中,浏览器不知道它需要在HTML文件到达之前请求CSS文件,而HTML文件的标签是link 。而在下一个例子中,HTML文件链接到一个JavaScript和CSS文件,而CSS文件则链接到一个JPG文件(例如可用作CSSbackground )。
然而,至少如果一个文件中有多个引用,例如最初的HTML文件链接到一个CSS和一个JavaScript文件,这些资源将被并行请求和解决,正如在上一个例子中所看到的,但在下一个例子中也有说明。
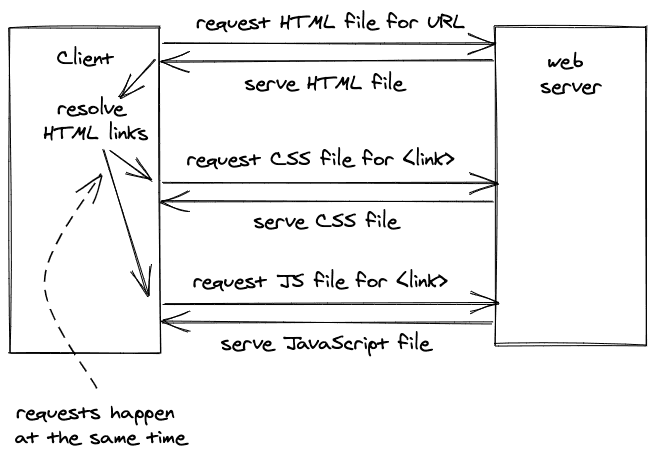
最终,浏览器将拥有一个特定URL的所有资源(如HTML、CSS、JavaScript、PNG、JPG、SVG),并将HTML与其包含的所有资产进行解释,为你显示出所需的结果。它已经准备好让你作为一个用户与之互动。
Web 2.0。从网站到网络应用
最终,仅仅从一个网络服务器上提供静态内容是不够的。在Web 2.0中(2004年左右),用户不仅可以阅读内容,还可以创建内容;这导致了动态内容。还记得之前的HTTP方法吗?到目前为止,我们只看到了读取资源的HTTP GET方法在发挥作用,那么其他的HTTP方法呢?
随着Wordpress等内容管理系统的兴起,网络服务器必须使用户不仅能够看到资源,而且能够操纵它们。例如,使用内容管理系统的用户必须能够登录、创建博文、更新博文、删除博文和注销。此时,编程语言PHP(可由服务器端的网络服务器解释)是最适合这类动态网站的。
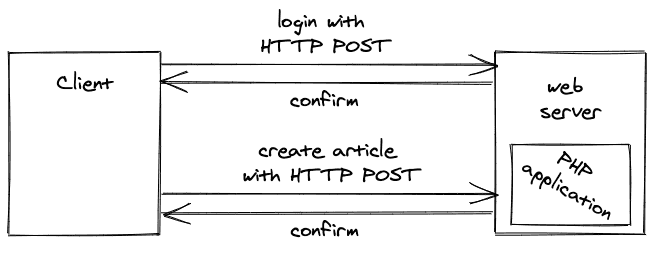
有了服务器端的逻辑,开发人员就能够处理来自用户的读写请求。如果用户想创建一篇博文(写操作),用户必须在浏览器中写博文,然后点击 "保存 "按钮,将内容发送到运行在网络服务器上的服务器端逻辑。这个逻辑验证了用户的授权,验证了博客内容,并将内容写入数据库。所有这些权限都不允许在客户端进行,否则每个人都可以未经授权地操纵数据库。
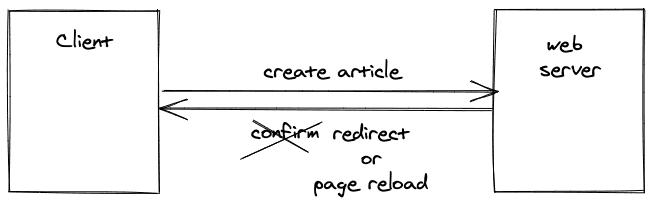
由于我们仍然有服务器端的路由,网络服务器能够在博客文章成功创建后将用户重定向到一个新页面。例如,重定向可以是到新发表的博文。如果没有重定向,无论如何,一个HTTP POST/PUT/DELETE请求通常会导致页面刷新/重新加载。
由于用户现在能够创建动态内容,我们需要有一个数据库来存储这些数据。数据库可以像Web服务器一样在同一台物理服务器(计算机)上(很可能是在Web2.0的早期),也可以在另一台远程计算机上(很可能是在现代的Web开发时代)。
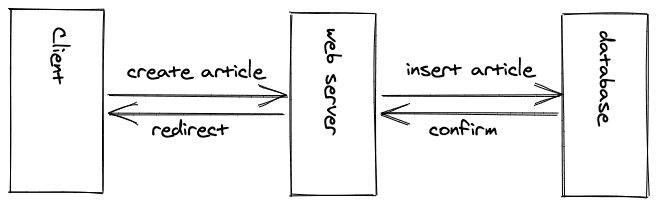
一旦博文被插入数据库,就可能为这篇博文生成一个独特的标识符,可以用来将用户重定向到新发表的博文的URL。所有这些仍然以异步方式发生。
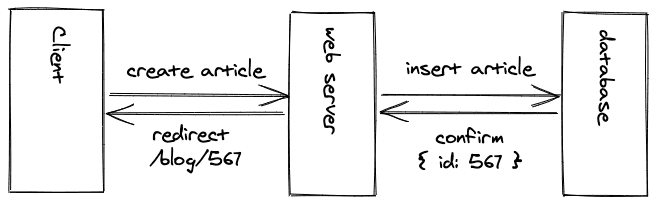
现在,在博文被创建之后,如果博文的数据不是静态的,而是存储在数据库中,那么服务器如何为博文发送一个HTML文件?这就是服务器端渲染的原理(不要与服务器端路由相混淆)发挥作用的地方。
面向消费者的Web1.0网站(静态内容)和面向生产者的Web2.0网站(动态内容)都从服务器返回HTML。用户在浏览器中导航到一个URL,然后请求它的HTML。然而,对于Web 2.0中的动态内容,发送到客户端的HTML不再是一个具有静态内容的静态HTML文件。相反,它被插入了来自服务器上数据库的动态内容。
<?php if ($expression == true): ?> This will show if the expression is true.<?php else: ?> Otherwise this will show.<?php endif; ?>
不同编程语言的模板引擎(例如Node.js上的JavaScript的Pug,PHP的Twig,Java的JSP,Python的Django)能够在发送给客户端之前对HTML和动态数据进行插值。在服务器端渲染的帮助下,用户生成的内容可以在客户端请求时,通过即时创建HTML,从服务器上提供给客户端。
我们在这里处理的还是网站吗?技术上来说是的,但通过从带有数据库的网络服务器(或应用服务器)提供动态内容而超越静态内容的网站也可以被称为网络应用。但这两种类型之间的界限是模糊的。
随着Web2.0的特征变得无处不在,并失去了其新颖性,Web2.0这个术语及其受欢迎程度在2010年左右逐渐减弱。
单页应用
2010年后,单页应用程序(SPA)的兴起使JavaScript大受欢迎。但我的想法很超前。在这个时代之前,网站主要是用HTML和CSS制作的,只撒了一点JavaScript。少量的JavaScript被用于动画或DOM操作(如删除、添加、修改HTML元素),但除此之外就没有什么了。而jQuery是执行此类任务的最流行的库之一。
但谁会想到整个应用程序可以用JavaScript来构建呢?早期用JavaScript编写单页应用程序的几个库/框架是Knockout.js、Ember.js和Angular.js;而React.js和Vue.js是后来发布的。它们中的大多数直到今天仍在现代网络应用中非常活跃。
在单页应用之前,浏览器会从网络服务器上请求一个网站的HTML文件和所有链接文件。如果用户碰巧在同一个域(如mywebsite.com)内从页面(如/home)导航到页面(如/about),那么每次导航都会向网络服务器发出新的请求。
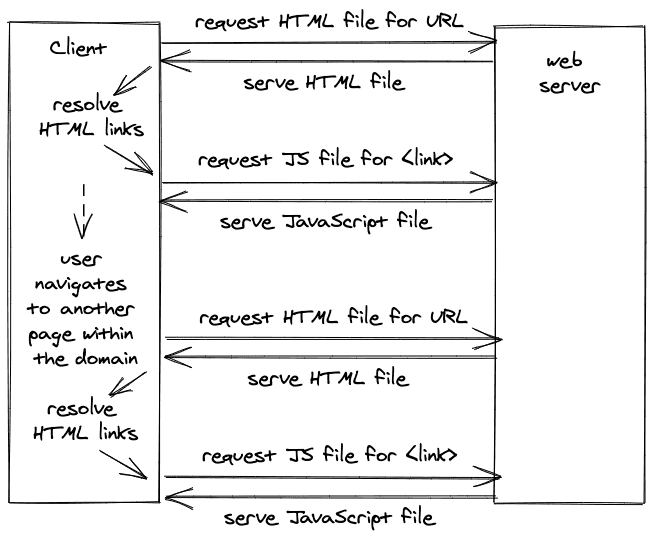
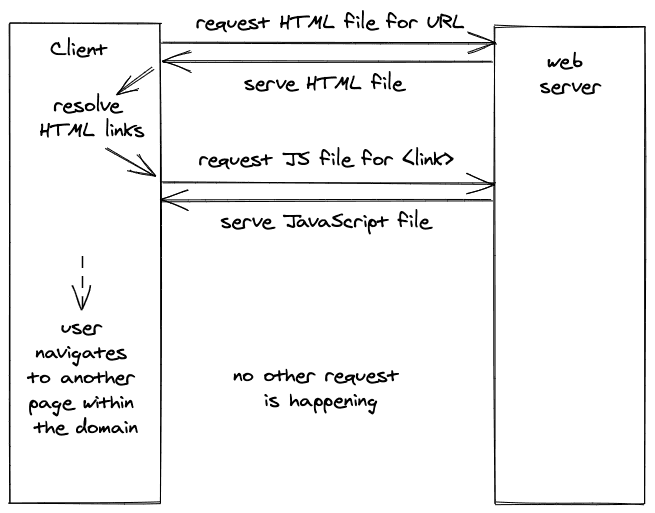
相比之下,单页应用程序将整个应用程序封装在大部分的JavaScript中,它拥有关于如何以及如何用HTML(和CSS)渲染的所有知识。对于单页应用程序的最基本使用,浏览器只需要为一个域请求一个HTML文件和一个链接的JavaScript文件。
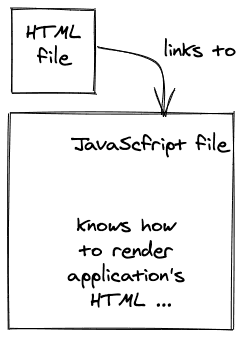
单页应用程序(这里是React应用程序)所请求的HTML只是一个中间人,用来请求JavaScript应用程序(这里是bundle.js),在客户端被请求并解决后,将在HTML中渲染(这里是id="app" )。
<!DOCTYPE html><html> <head> <title>Hello HTML File which executes a React Application</title> </head> <body> <div id="app"></div> <script src="./bundle.js"></script> </body></html>
从那里,React接管了这个来自*./bundle.js*的小JavaScript。
import * as React from 'react';import ReactDOM from 'react-dom';
const title = 'Hello React';
ReactDOM.render( <div>{title}</div>, document.getElementById('app'));
在这个小小的React应用程序中,只有一个叫做title 的变量被显示在HTMLdiv 元素中。然而,HTMLdiv 元素之间的一切都可以用React组件及其模板语法JSX构建的整个HTML结构来代替。
import * as React from 'react';import ReactDOM from 'react-dom';
const App = () => { const [counter, setCounter] = React.useState(42);
return ( <div> <button onClick={() => setCounter(counter + 1)}> Increase </button> <button onClick={() => setCounter(counter - 1)}> Decrease </button>
{counter} </div> );};
ReactDOM.render( <App />, document.getElementById('app'));
增加减少42
这本质上是先前的模板引擎,只是在客户端而不是服务器上执行,因此这不再是服务器端的渲染了。
const App = () => { const [books, setBooks] = React.useState([ 'The Road to JavaScript', 'The Road to React', ]);
const [text, setText] = React.useState('');
const handleAdd = () => { setBooks(books.concat(text)); setText(''); };
return ( <div> <input type="text" value={text} onChange={(event) => setText(event.target.value)} /> <button type="button" onClick={handleAdd} > Add </button>
<List list={books} /> </div> );};
const List = ({ list }) => ( <ul> {list.map((item, index) => ( <li key={index}>{item}</li> ))} </ul>);
添加
- JavaScript之路
- 通往React之路
由于这种从服务器到客户端执行渲染的变化,我们现在称之为客户端渲染。换句话说。我们不再直接从Web服务器上提供预渲染的HTML,而是主要从Web服务器上提供JavaScript,在客户端执行,然后才渲染HTML。通常情况下,SPA这个词可以与客户端渲染应用程序这个词同义。
如果SPA只从Web服务器上请求一次,那么当用户从一个页面导航到同一域内的另一个页面(例如从mywebsite.com/about到mywebsite.com/home)而不请求另一个HTML时,它如何工作?
随着传统SPA的使用,我们也从服务器端路由转移到客户端路由。最初请求的基本SPA的JavaScript文件已经封装了网站的所有页面。从一个页面(如/about)导航到另一个页面(如/home)不会对Web服务器执行任何请求。相反,一个客户端路由器(例如React Router for React)会接管,从最初请求的JavaScript文件中渲染适当的页面。
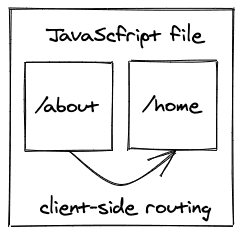
简而言之。一个基本的单页应用程序使用客户端渲染/路由而不是服务器端渲染/路由,同时从Web服务器上只检索一次整个应用程序。之所以说是单页面,是因为整个应用程序只有一个请求,即一个链接到一个JavaScript文件的HTML页面;该文件将所有实际的UI页面封装起来并在客户端执行。
可以说,在我们拥有单页应用程序之前,我们一直在使用多页应用程序,因为对于每一个页面(例如/关于),都要向网络服务器发出新的请求,以检索它的所有必要文件。然而,多页应用这个词并不是真正的东西,因为在单页应用开始流行之前,它是默认的。
练习。
- 学习如何使用React进行单页应用开发。
- 学习如何从头开始设置一个带有Webpack的React应用程序。
代码拆分
我们已经了解到,SPA默认会以一个小的HTML文件和一个JS文件的形式被运出。JavaScript文件开始时很小,但当你的应用程序变大时,它的大小会增加,因为更多的JavaScript被打包在一个bundle.js文件中。这影响了SPA的用户体验,因为将JavaScript文件从Web服务器传输到浏览器的初始加载时间最终会增加。当所有文件都加载完毕后,用户可以不受干扰地从一个页面浏览到另一个页面(好)。然而,相比之下,当在浏览器中请求页面时,初始加载时间会降低用户体验(坏)。
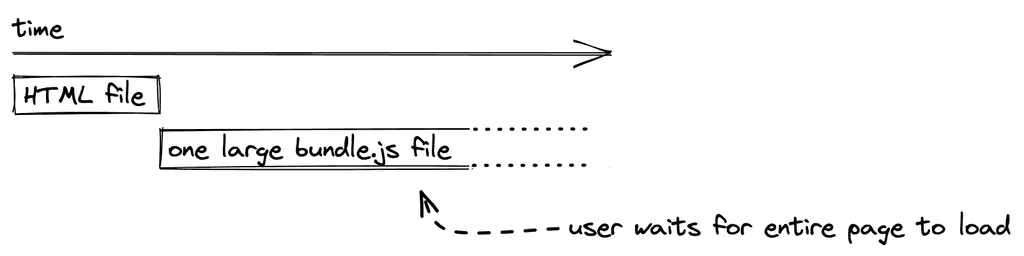
一旦应用程序的规模扩大,以JavaScript文件的形式请求整个应用程序就成为一个缺点。对于更复杂的单页应用程序,像代码分割(在React + React Router中也称为懒惰加载)这样的技术被用来只提供当前页面所需的一部分应用程序(例如mywebsite.com/home)。当导航到下一个页面(如mywebsite.com/about)时,会向网络服务器发出另一个请求,要求提供这个页面的部分内容。
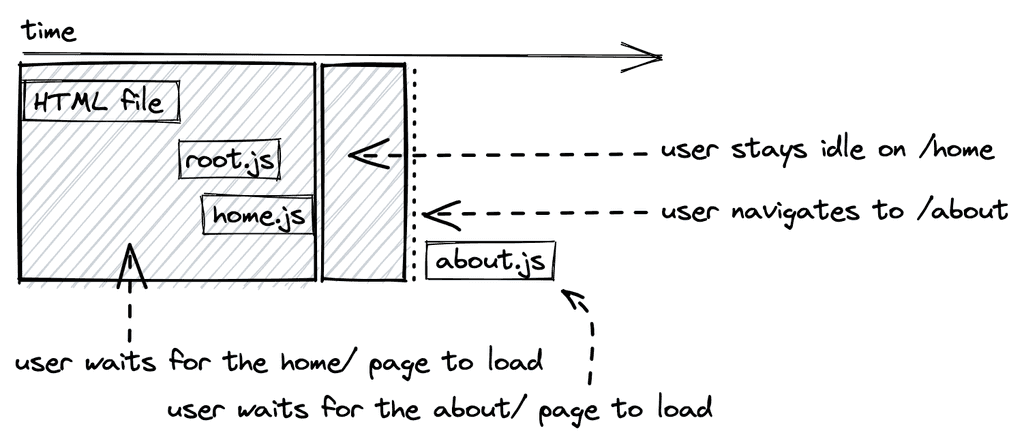
如果你回顾一下传统网站的工作方式,你会发现它与启用了代码分割的SPA很相似。对于一个传统的网站,每当用户浏览到一个新的路线时,就会加载一个新的HTML文件(有可选的CSS、JavaScript和其他资产文件)。对于在路由层面上进行代码分割的SPA来说,每次导航都会导致一个新请求的JavaScript文件。
我们还能把这称为单页应用吗,还是说我们又回到了多页应用?你看,术语最终会变得很模糊......
代码拆分不需要像前面的情况那样发生在路由级别。例如,我们也可以将较大的React组件提取到其独立的JavaScript捆绑中,这样它就只在实际使用的页面中被加载。
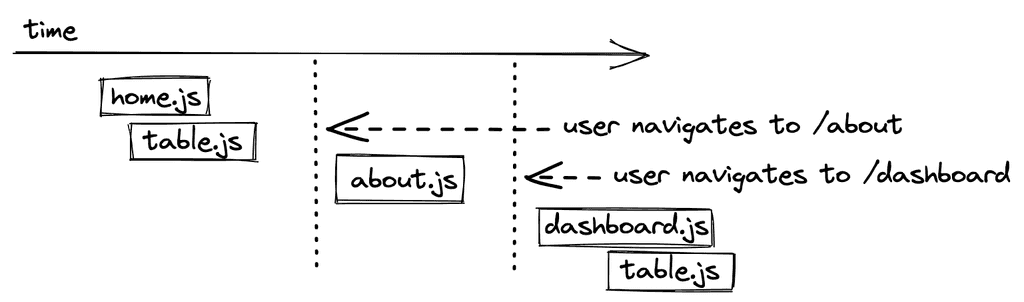
然而,正如你所看到的,这导致了从网络服务器上请求的多余的代码。当用户两次导航到一个代码分割路线时,也会发生同样的情况,因为它也会从网络服务器上加载两次。因此,我们希望浏览器对结果进行缓存(读作:存储在用户机器上的浏览器缓存中)。
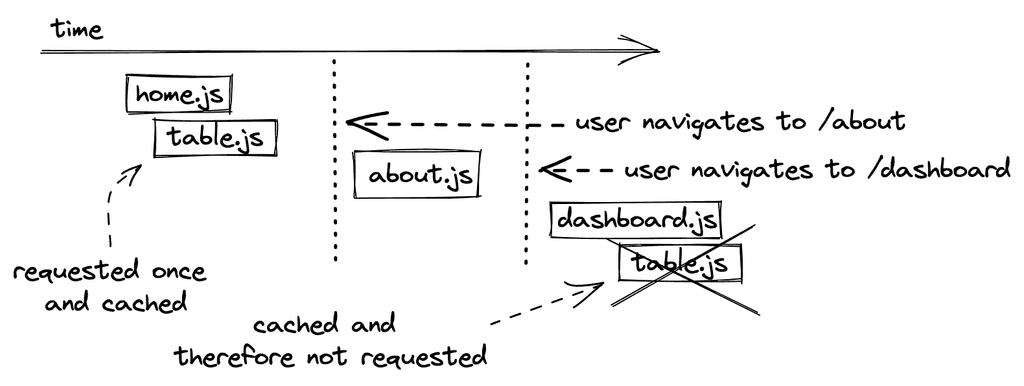
现在,如果捆绑的table.js文件改变了,因为我们为我们的表格引入了新的功能,如分页视图或树状视图,会发生什么?如果启用了缓存,我们仍然会在浏览器中看到旧版本的Table组件。
作为这个问题的解决方案,每一个新构建的应用程序都会检查捆绑的代码是否有变化。如果发生了变化,它就会收到一个基于时间戳的新文件名(例如,table.hash123.js变成table.hash765.js)。当浏览器请求一个带有缓存文件名的文件时,它使用缓存的版本。然而,如果该文件已经改变,因此有了一个新的散列名,浏览器就会请求新的文件,因为兑现的版本已经过时了。
另一个例子是第三方JavaScript库的代码分割。例如,在安装React的UI库时,其中有Button和Dropdown等组件,也可以应用代码拆分。那么每个组件都是一个独立的JavaScript文件。当从UI库中导入Button组件时,只有Button的JavaScript被导入,而没有Dropdown的JavaScript。
继续阅读。学习如何创建一个React Button
对于将React应用程序(或库)捆绑成一个或多个(有代码分割)的JavaScript文件,另一种称为树状摇动的技术开始发挥作用,它消除了死代码(阅读:未使用的代码),因此它不会被打包到最终的捆绑中。历史上,以下捆绑器被用于JavaScript(从过去到最近)。
练习。
- 学习如何在React中使用React Router进行客户端路由。
全栈式应用
我们正在进入全栈应用的范式,它与SPA同时流行。一个全栈应用包括客户端(如SPA)和服务器应用。如果公司正在寻找全栈开发人员,他们往往希望有人能够在两端创建客户端-服务器应用程序。有时,客户端和服务器共享相同的编程语言(例如,客户端使用React的JavaScript,服务器使用Node.js的JavaScript),但他们不一定要这样。
总之,我们为什么需要全栈应用?对全栈应用的需求是由于客户端的单页应用的兴起而产生的。
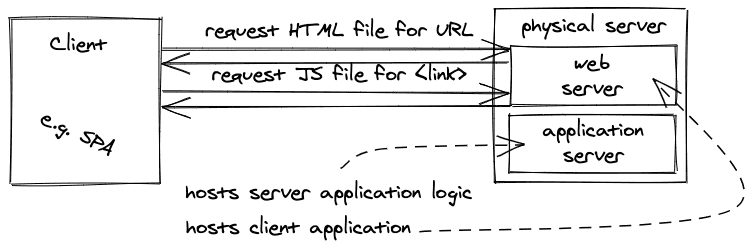
到目前为止,我们从带有HTML/CSS/JavaScript的传统网站到现代网络应用(如React应用)。渲染静态内容没问题,但如果在处理客户端渲染的SPA时,只有JavaScript(和少量HTML)从Web服务器提供给客户端,我们如何渲染动态内容,例如用户的特定内容,如博客文章(见Web 2.0,但这次是客户端渲染)?
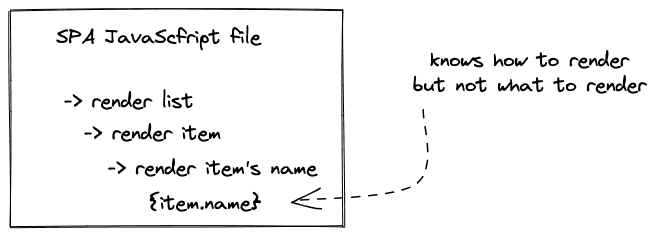
SPA应用程序--它被封装在一个JavaScript文件中--没有任何用户特定的数据。它只是页面的逻辑;它们看起来像什么,以及它们在用户交互中的表现如何。实际的数据并没有被嵌入其中,因为它仍然在数据库中的某个地方,而不会再在服务器上被插值。这就是当你从服务器端渲染转移到客户端渲染时必须要做的权衡。
因此,从客户端到服务器(用JavaScript/Node.js或其他编程语言编写的应用服务器)的另一个请求必须在客户端上请求缺失的数据来填补空白。客户端模板引擎(例如React中的JSX)负责将内容(数据)与结构(HTML)进行插值。
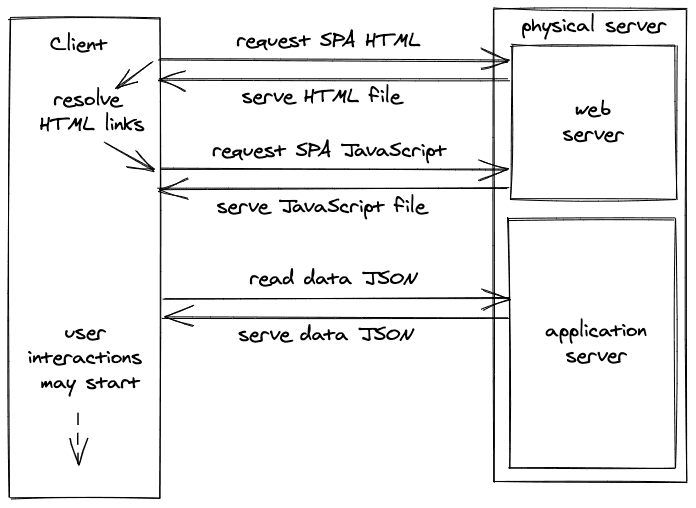
本质上,在处理客户端渲染的应用程序时,有两个往返的请求:一个是JavaScript应用程序,一个是填补空白的数据。一旦所有的东西都在浏览器中呈现出来,用户就开始与应用程序进行互动--例如,创建一个新的博客文章。JSON是一种从客户端到服务器发送数据的首选格式,反之亦然。服务器通过读取或写入数据库来处理来自客户端的所有请求;数据库可以在同一台物理服务器上,但不需要(例如,只是坐在另一台物理服务器上)。
客户端渲染的应用程序(SPA)有一个缺点,即从一开始就没有所有的数据可供他们支配。他们必须请求所有的东西来填补空白。作为一个在网上冲浪的终端用户,你会从两个方面注意到客户端渲染的应用程序。
- 首先,有加载旋钮(几乎无处不在),有时从有一个加载旋钮为整个页面,在之后的一瞬间有多个加载旋钮(瀑布式请求)为较小的部件,因为请求数据发生在渲染初始页面之后。
- 其次,从路由到路由的导航是瞬时的(不包括代码分割,因为那样的话,由于对服务器的额外捆绑请求,感觉有点慢)。这就是我们从SPA中获得的好处。
继续阅读。学习如何在React中获取数据
除了额外的数据获取往返,客户端渲染的应用程序必须处理状态管理的挑战,因为用户的互动和数据需要在客户端的某个地方存储和管理。
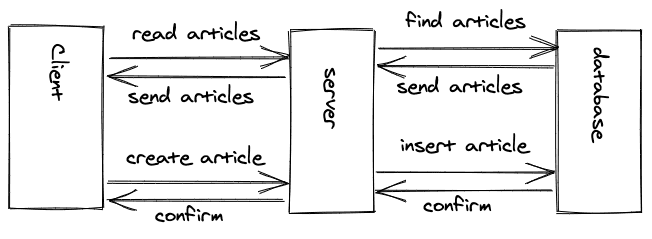
在使用SPA时考虑以下挑战:一个用户以作者身份访问一个可以发布博客文章的网站。在当前页面,用户看到了他们所有的博客文章,因此在加载这个页面时需要获取所有这些博客文章。这些取来的博文在客户端的代码中被保存为内存中的状态。现在,当用户开始与页面及其数据互动时,每篇博文的一个按钮允许用户单独删除每个条目。当用户点击删除按钮时会发生什么?让我们走过这个场景。
一个用户点击了删除按钮,向应用服务器发送了一个请求,其有效载荷是博文的标识符和删除指令(通常是HTTP DELETE即可)。在服务器上的所有权限检查(例如:用户是否被授权,博文是否在那里,博文是否属于用户)完成后,服务器将操作委托给数据库,博文在那里被删除。数据库向服务器确认操作的成功,然后服务器向客户发送一个响应。现在,客户端要么从内存中的本地状态中删除博文,要么再次从服务器上获取所有的博文,并将内存中的博文替换为更新的博文列表。
继续阅读。了解React中的状态
在执行客户端路由时,对数据(如博客文章)的请求可以通过状态管理最小化。这意味着,理想情况下,用户从一个页面导航到另一个页面,然后回到最初的页面,不应该触发对最初页面所需数据的第二次请求。相反,它应该已经通过使用状态管理在客户端缓存了。
最后,但不是最不重要的,客户端和服务器之间的接口被称为API。在这种情况下,它是两个远程实体之间的一种特殊的API,这里是一个客户端和一个服务器,然而在编程中很多东西都被称为API。
练习。
- 阅读更多关于不同种类的API的信息。
客户端-服务器通信
传统的全栈应用程序使用REST作为他们的API范式;它采用HTTP方法进行CRUD操作。此前,我们已经使用HTTP方法进行CRUD操作--不遵循明确的约束--在文件和用户交互中,如用PHP等服务器端语言创建博客文章。
然而,当使用REST API时,我们在RESTful资源上使用这些HTTP方法。例如,一个RESTful资源可以是一篇博文。用户可以用HTTP GET方式从应用服务器上阅读博文,或者用HTTP POST方式在应用服务器上创建一个新的博文。
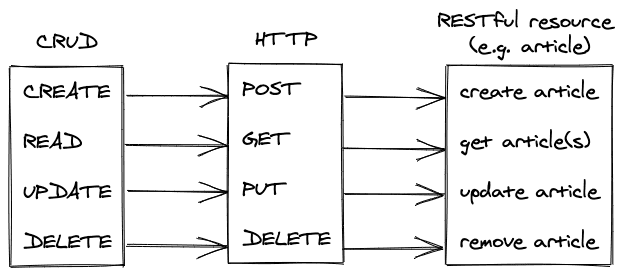
REST API连接客户端和服务器应用程序,而不需要用相同的编程语言来实现。他们只需要提供一个用于发送和接收HTTP请求和响应的库。REST是一种通信范式,它没有数据格式(过去是XML,但现在是JSON)和编程语言。
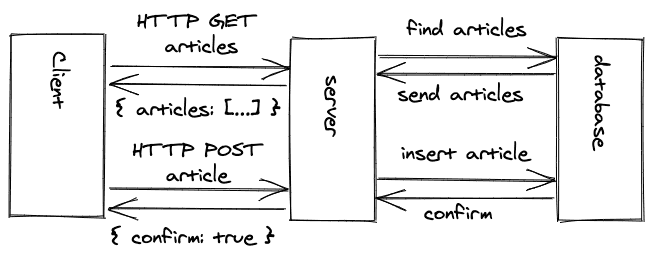
REST的一个现代替代品是用于客户端和服务器之间的API的GraphQL。GraphQL也不拘泥于数据格式,与REST相比,它不拘泥于HTTP,但你经常会看到HTTP和JSON也用在这里。
通过到此为止所讨论的技术,全栈应用将客户端和服务器应用解耦。两者通过精心选择的API(如REST或GraphQL)进行通信。客户端应用在浏览器中渲染网络应用所需的一切,而服务器应用则处理来自客户端的读写数据的请求。
练习。
- 学习如何用Node.js创建一个REST API。
- 阅读更多关于为什么要使用GraphQL而不是REST。
- 学习如何将GraphQL用于全栈的JavaScript应用。
前端和后端
我们还没有讨论过前端和后端这两个术语,因为我不想在前期添加太多的信息。前端应用程序可能是用户在浏览器中看到的一切(如网站、Web应用程序、SPA)。因此,你会看到前端开发人员最常使用HTML/CSS或像React.js这样的库来工作。相比之下,后端通常是幕后的逻辑。它是从数据库中读取和写入的逻辑,与其他应用程序对话的逻辑,以及经常提供API的逻辑。
这两个实体导致了客户端-服务器架构(前端和后端关系),而后端需要用于(A)不应该作为源代码暴露给前端应用程序的业务逻辑(如授权)--否则它将在浏览器中被访问--或者用于(B)建立与第三方数据源(如数据库)的敏感连接。
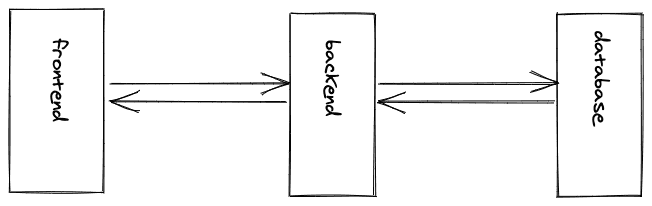
然而,在这里不要把客户应用总是误认为是前端,而把服务器应用总是误认为是后端。这些术语不能那么容易交换。前台应用通常是在浏览器中看到的东西,而后台通常执行不应该暴露在浏览器中的业务逻辑,并且通常也连接到数据库。
但是,相比之下,客户端和服务器这两个术语是一个角度问题。一个后端应用程序(后端1)消耗另一个后端应用程序(后端2),成为服务器应用程序(后端2)的客户端应用程序(后端1)。然而,同一个后端应用程序(后端1)仍然是另一个客户端应用程序的服务器,而这个客户端应用程序就是前端应用程序(前端)。
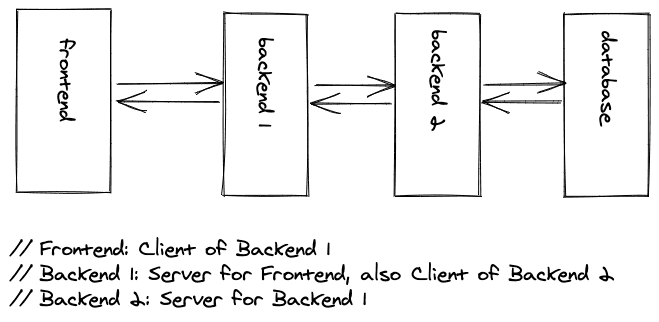
如果你想回答客户-服务器问题,如果有人问你一个实体在客户-服务器架构中扮演什么角色,那么你一定要问自己谁(服务器)在为谁(客户)服务,谁(客户)在消费谁的(后端)功能?
微服务(可选)
例如,微服务是一种架构,它将一个大的后端(也叫单体)分割成小的后端**(微服务**)。每个小的后端可能有一个领域的特定功能,但它们毕竟都是为一个前端(或多个前端)服务的。然而,一个后端也可以消费另一个后端,而前一个后端成为客户端,后一个后端则是服务器。
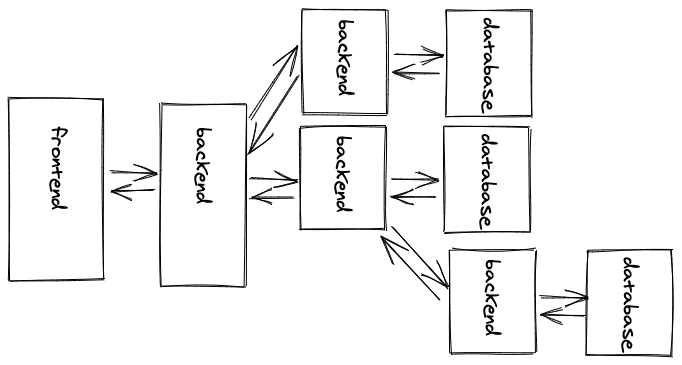
在微服务架构中,每个后端应用可以用不同的编程语言来创建,而所有的后端都能通过API来相互通信。他们选择哪种API范式并不重要,无论是REST API还是GraphQL API,只要与他们的服务器对话的客户端能理解API规范。也可能发生这样的情况:一个前端并不只与一个后端对话,而是与多个后端并排对话。
练习。
后台即服务(可选)
在传统意义上,一个单一的后端应用,只是为了服务于一个前端应用,通常连接到一个数据库。这就是一个典型的全栈应用。然而,大多数情况下,除了从数据库中读写,允许某些用户执行某些操作(授权),或首先对用户进行认证(如登录、注销、注册)外,后端应用程序并没有做什么。如果是这种情况,往往不需要自己去实现一个后台应用程序。
Firebase(由谷歌提供)是一个后台即服务的解决方案,它提供了一个数据库、认证和授权作为一个开箱即用的后台。开发者只需要实现前端应用程序(如React应用程序),它需要连接到这个后端即服务。
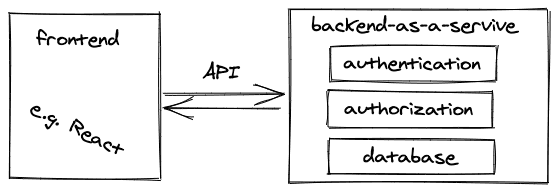
像Firebase这样的后端即服务(BaaS)可以让开发者很快地启动和运行他们的前端应用。从认证、授权到数据库的一切都为你完成。此外,大多数BaaS也提供托管服务,例如,你的React应用程序也可以由Firebase托管。因此,Firebase为你的客户端(浏览器)提供你的React应用程序,并使你的应用程序能够为所有其他功能(如认证、数据库)与它对话。一个流行的替代Firebase的开源软件是Supabase。
练习。
超越全栈应用
如果所有这些对你来说还不算太混乱,那么试着跟上我的步伐,了解全栈应用的最新发展。随着所有从传统网站到全栈应用的发展,你可能已经注意到从X到Y的转变往往使事情变得更加复杂 ...
- 服务器端路由(X)到客户端路由(Y)
- 庞大的捆绑规模,虽然可以通过代码拆分来解决
- 服务器端渲染(X)到客户端渲染(Y)
- 对数据的额外(瀑布)请求
- 对开发者来说,额外的数据获取和状态管理工作
- 对终端用户来说,有大量的加载旋钮
- 对数据的额外(瀑布)请求
在下文中,我想向你介绍两种方法,它们的理念(SSR、SSG)并不新鲜,但当与现代库(如React)和元框架(如Next.js、Gatsby.js)一起使用时,它们就会变得非常强大,这使得这些方法成为可能。我是一个React开发者,这就是为什么对这些技术的建议是有偏见的,然而,我相信你也可以找到类似的技术来满足你的偏好。
服务器端渲染2.0(SSR)
我们之前已经了解了Web 2.0的服务器端渲染技术。在后来,全栈应用将客户端和服务器解耦,并通过React等库引入客户端渲染。那么,再退一步,用React做服务器端渲染呢?
当使用流行的Next.js框架时,它位于React的顶部,你仍然在开发React应用程序。然而,你在Next.js中实现的一切将是服务器端渲染的React。在Next.js中,你用React实现每个页面(如/about,/home)。当用户从一个页面浏览到另一个页面时,只有一小部分服务器端渲染的React被发送到浏览器上。它的伟大之处在于。你已经可以在服务器上请求数据来填补空白,用React插值数据,并将其发送到客户端,没有任何空隙。
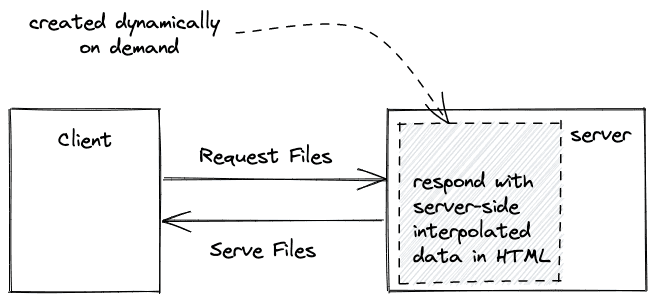
这与客户端渲染不同,因为React只在客户端接管,而且只有在客户端没有数据的情况下,才开始请求数据来填补空白。有了SSR React,你可以在React中插值已经在服务器上的数据,但也可以选择在应用被渲染时在客户端获取数据。这两个选项,客户端渲染和服务器端渲染都可以混合使用。
- 优势。客户端收到已经填充了数据的HTML(改善用户体验和SEO)。
- 劣势。客户端可能需要等待更长的时间,因为填充的HTML是在服务器上即时创建的(HTTP缓存将这个问题降到最低)。
练习。
静态网站生成(SSG)
传统的网站使用来自网络服务器的静态文件,在浏览器上进行渲染。正如我们所了解的,没有应用服务器的参与,也没有服务器端渲染的参与。传统网站的方法是非常简单的,因为网络服务器只是托管了你的文件,在用户访问的每个URL上,你的浏览器都会发出请求以获得必要的文件。那么如果我们可以用React来处理静态文件呢?
React本身并不是为静态文件而生的。相反,React只是在客户端即时创建应用程序的JavaScript文件。然而,Gatsby.js,一个位于React之上的框架,被用来为React应用程序生成静态网站。Gatsby将一个React应用程序编译成静态HTML和JavaScript文件。然后,所有这些文件都可以被托管在一个网络服务器上。如果用户访问一个URL,静态文件会被提供给浏览器。
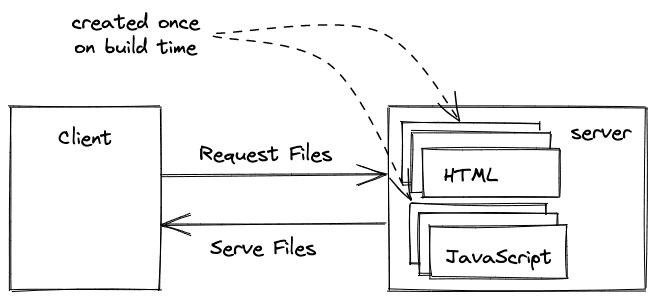
与服务器端渲染React相比,静态文件不是在用户请求时即时创建,而是在构建时才创建一次。对于数据经常变化的动态内容来说,这可能是一个缺点(如电子商务),然而,对于营销页面或内容不经常变化的博客来说,偶尔只建立一次网站是完美的解决方案。
如果在这场从网站到网络应用的马拉松中缺少什么,请让我知道。我希望你喜欢阅读它!如果你认为在这篇博文中加入更多的内容,并作为101网络开发发布,请告诉我,并注册我的Newsletter,以听到更多的信息 :-)
