

神经机器翻译是使用深度学习来生成从一种语言到另一种语言的准确翻译的做法。这意味着训练一个深度神经网络来预测一连串单词作为正确翻译的可能性。
这种技术的用途几乎是无限的。今天,我们有了翻译器,能够对用其他语言编写的整个网页进行几乎即时和相对准确的翻译。我们可以将相机对准一段文字,并使用增强现实技术将文字替换成翻译。我们甚至可以动态地将现场讲话翻译成其他语言的文字。这种能力在很大程度上实现了技术全球化,如果没有序列到序列的神经机器翻译的概念,就不可能实现。
第一个Seq2Seq(序列到序列)翻译器是由谷歌的研究人员在2014年推出的。他们的发明从根本上改变了翻译领域,像谷歌翻译这样的流行服务发展到巨大的准确性和可及性水平,以满足互联网的需求。
在这篇博文中,我们将分解Seq2Seq翻译的理论和设计。然后,我们将通过PyTorch官方指南的增强版,从头开始进行Seq2Seq翻译,我们将首先改进原始框架,然后演示如何将其适应于一个新的数据集。
Seq2Seq翻译器:它们是如何工作的?
对于深度学习来说,Seq2Seq翻译器是以一种相对简单的方式运作的。这类模型的目标是将一个固定长度的字符串输入映射到一个固定长度的成对字符串输出,其中 ,这两个长度可以不同。如果输入语言的一个字符串有8个单词,而目标语言的同一句子有4个单词,那么高质量的翻译应该推断出这一点,并缩短输出的句子长度。
设计理论
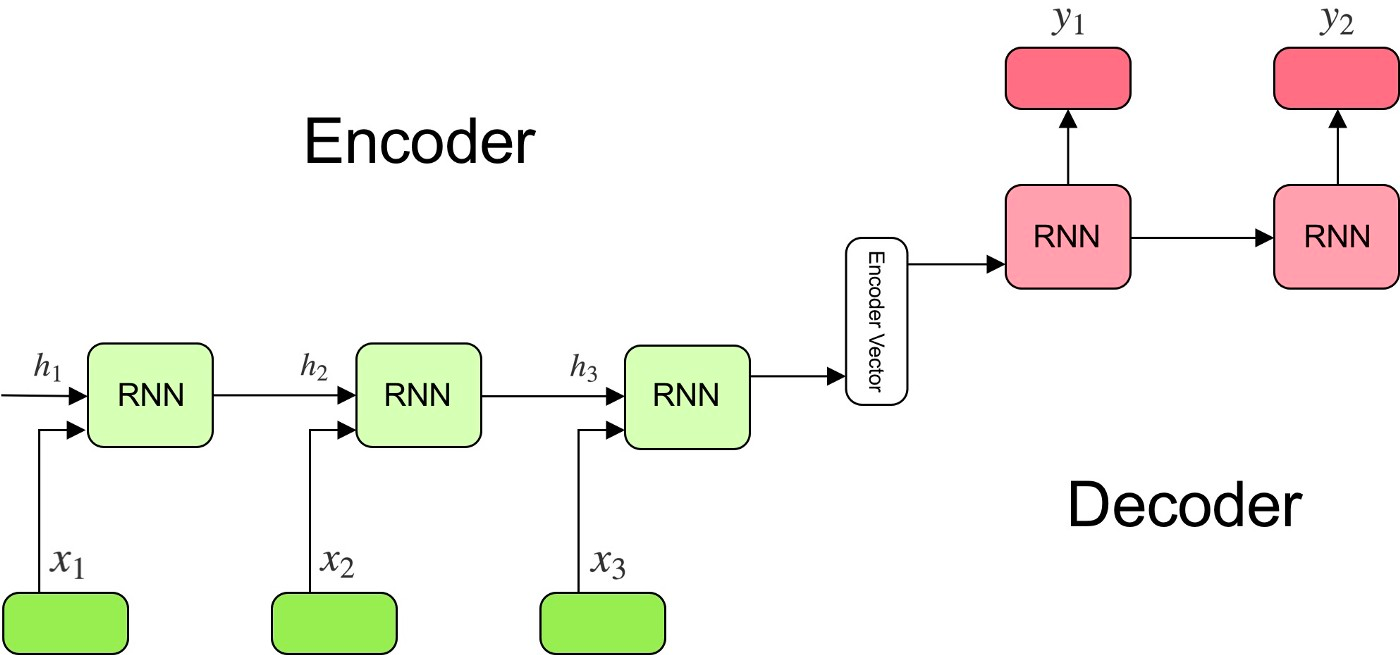
Seq2Seq翻译器通常有一个共同的框架。任何Seq2Seq翻译器的三个主要组成部分是编码器和解码器网络以及它们之间的中介矢量编码。这些网络通常是递归神经网络(RNN),但经常是由更专业的门控递归单元(GRU)和长短时记忆(LSTM)组成的。这是为了限制潜在的梯度消失对翻译的影响。
编码器网络是一系列的这些RNN单元。它使用这些单元依次将输入的元素编码为编码器向量,最终的隐藏状态被写入中间向量。
许多NMT模型利用注意力的概念来改进这种上下文编码。注意力是通过一组权重迫使解码器关注编码器输出的某些部分的做法。这些注意力的权重与编码器的输出向量相乘。这将产生一个组合矢量编码,增强解码器理解其产生的输出的背景的能力,从而改善其预测。计算这些注意力权重是通过一个前馈注意力层完成的,它使用解码器的输入和隐藏状态作为输入。
编码器向量包含来自编码器的输入的数字表示。如果事情进展顺利,它可以捕捉到初始输入句子的所有信息。这个编码向量然后作为解码器网络的初始隐藏状态。
解码器网络本质上是编码器的逆向。它把编码向量的中介作为隐藏状态,并依次产生翻译。 输出中的每个元素都会通知解码器对下一个元素的预测。
在实践中
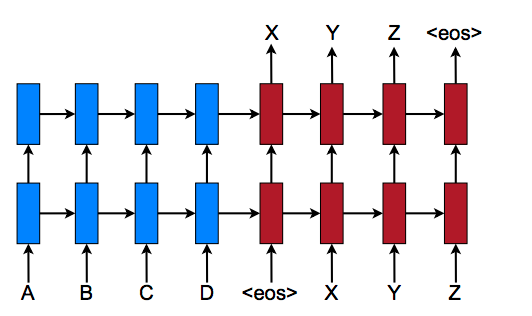
在实践中,NMT将采取一种语言的输入字符串,并创建一个代表句子中每个元素,单词的嵌入序列。编码器中的RNN单元将之前的隐藏状态和原始输入嵌入的单个元素作为输入,每一步都可以通过访问前一步的隐藏状态来告知预测的元素,从而依次改进前一步。还需要提到的是,除了对句子进行编码外,句末标签表示也作为一个元素包含在序列中。这个句末标签有助于译者知道翻译语言中哪些词会触发解码器放弃解码并输出翻译的句子。
最终的隐藏状态嵌入被编码在中间的编码器向量中。编码尽可能多地捕捉关于输入句子的信息,以便于解码器将它们解码到译文中。它能做到这一点是凭借被用作解码器网络的初始隐藏状态。
利用来自编码器矢量的信息,解码器中的每个递归单元接受来自前一个单元的隐藏状态,并产生一个输出和它自己的隐藏状态。解码器通过隐藏状态获知对一个序列进行预测,在每一个序列预测中,它利用前一个隐藏状态的信息预测该序列的下一个实例。因此,最终输出是对翻译的句子中每个元素进行逐步预测的最终结果。这个句子的长度与输入句子的长度无关,这要归功于句末标签,它告诉解码器何时停止向句子添加术语。
在下一节中,我们将展示如何使用定制的函数和PyTorch实现每个步骤。
实现Seq2Seq翻译器
PyTorch网站上有一篇关于从头开始创建Seq2Seq翻译器的精彩教程。 下一节是对其中大部分代码的改编,所以在继续实现这些更新之前,可能值得通读一下他们的教程笔记本。
我们将以两种方式对该教程进行扩展:增加一个全新的数据集和进行调整以优化翻译能力。首先,我们将展示如何获取和准备WMT2014英法翻译数据集,以用于梯度笔记本中的Seq2Seq模型。由于大部分代码与PyTorch教程中的相同,我们将只关注编码器网络、注意力解码器网络和训练代码。
把这个项目带入生活
准备数据
获取和准备WMT2014 Europarl v7英语-法语数据集
WMT2014 Europarl v7英语-法语数据集是欧洲议会内部的演讲集合,并被翻译成多种不同语言。你可以在www.statmt.org/europarl/ 免费访问它。
要在Gradient上获取数据集,只需进入终端并运行
wget https://www.statmt.org/europarl/v7/fr-en.tgz
tar -xf fre-en.tgz
你还需要下载由Torch提供的教程数据集:
wget https://download.pytorch.org/tutorial/data.zip
unzip data.zip
一旦你有了数据集,我们就可以使用Jason Brownlee从Machine Learning Mastery上创建的一些代码来快速准备和组合它们,以便我们的NMT。这段代码在笔记本data_processing.ipynb 。
# load doc into memory
def load_doc(filename):
# open the file as read only
file = open(filename, mode='rt', encoding='utf-8')
# read all text
text = file.read()
# close the file
file.close()
return text
# split a loaded document into sentences
def to_sentences(doc):
return doc.strip().split('\n')
# clean a list of lines
def clean_lines(lines):
cleaned = list()
# prepare regex for char filtering
re_print = re.compile('[^%s]' % re.escape(string.printable))
# prepare translation table for removing punctuation
table = str.maketrans('', '', string.punctuation)
for line in lines:
# normalize unicode characters
line = normalize('NFD', line).encode('ascii', 'ignore')
line = line.decode('UTF-8')
# tokenize on white space
line = line.split()
# convert to lower case
line = [word.lower() for word in line]
# remove punctuation from each token
line = [word.translate(table) for word in line]
# remove non-printable chars form each token
line = [re_print.sub('', w) for w in line]
# remove tokens with numbers in them
line = [word for word in line if word.isalpha()]
# store as string
cleaned.append(' '.join(line))
return cleaned
# save a list of clean sentences to file
def save_clean_sentences(sentences, filename):
dump(sentences, open(filename, 'wb'))
print('Saved: %s' % filename)
# load English data
filename = 'europarl-v7.fr-en.en'
doc = load_doc(filename)
sentences = to_sentences(doc)
sentences = clean_lines(sentences)
save_clean_sentences(sentences, 'english.pkl')
# spot check
for i in range(10):
print(sentences[i])
# load French data
filename = 'europarl-v7.fr-en.fr'
doc = load_doc(filename)
sentences = to_sentences(doc)
sentences = clean_lines(sentences)
save_clean_sentences(sentences, 'french.pkl')
# spot check
for i in range(1):
print(sentences[i])
这将采取我们的WMT2014数据集,并清除它们中的任何标点符号、大写字母、不可打印的字符和带有数字的标记。然后,它将文件腌制起来供以后使用。
with open('french.pkl', 'rb') as f:
fr_voc = pickle.load(f)
with open('english.pkl', 'rb') as f:
eng_voc = pickle.load(f)
data = pd.DataFrame(zip(eng_voc, fr_voc), columns = ['English', 'French'])
data
我们可以使用pickle.load() 来加载现在保存的文件,然后我们可以使用方便的Pandas DataFrame来合并这两个文件。
合并我们的两个数据集
为了给翻译器创造一个更完整的数据集,让我们把我们现在拥有的两个数据集结合起来。
data2 = pd.read_csv('eng-fra.txt', '\t', names = ['English', 'French'])
我们需要从经典的PyTorch教程中加载原始数据集。有了这两个数据帧,我们现在可以把它们串联起来,并以PyTorch的样本数据集所使用的原始格式保存回来。
data = pd.concat([data,data2], ignore_index= True, axis = 0)
data.to_csv('eng-fra.txt')
现在,我们的数据集可以被应用到我们的代码中,就像经典的PyTorch教程一样!但首先,让我们看看准备数据集的步骤,看看我们可以做哪些改进。打开笔记本seq2seq_translation_combo.ipynb ,并运行第一个单元,以确保matplotlib内联工作和导入完成。
from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata
import string
import re
import random
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import torchtext
from torchtext.data import get_tokenizer
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
数据集准备辅助函数
SOS_token = 0
EOS_token = 1
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
为了给翻译器处理我们的数据集,我们可以使用这个Lang类来为我们的语言类提供有用的功能,比如word2index ,index2word ,和word2count 。下一个单元格也将包含清理原始数据集的有用功能。
def readLangs(lang1, lang2, reverse=False):
print("Reading lines...")
# Read the file and split into lines
lines = open('%s-%s2.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
# Reverse pairs, make Lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
接下来,readLangs函数接收我们的csv来创建input_lang,output_lang, 和对变量,我们将用这些变量来准备我们的数据集。这个函数使用辅助函数来清理文本并使字符串正常化。
MAX_LENGTH = 12
eng_prefixes = [ "i am ", "i m ", "he is", "he s ", "she is", "she s ", "you are", "you re ", "we are", "we re ", "they are", "they re ", "I don t", "Do you", "I want", "Are you", "I have", "I think", "I can t", "I was", "He is", "I m not", "This is", "I just", "I didn t", "I am", "I thought", "I know", "Tom is", "I had", "Did you", "Have you", "Can you", "He was", "You don t", "I d like", "It was", "You should", "Would you", "I like", "It is", "She is", "You can t", "He has", "What do", "If you", "I need", "No one", "You are", "You have", "I feel", "I really", "Why don t", "I hope", "I will", "We have", "You re not", "You re very", "She was", "I love", "You must", "I can"]
eng_prefixes = (map(lambda x: x.lower(), eng_prefixes))
eng_prefixes = set(eng_prefixes)
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and \
len(p[1].split(' ')) < MAX_LENGTH and \
p[1].startswith(eng_prefixes)
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
eng_prefixes
在Torch教程的另一个变化中,我扩展了英语前缀列表,以包括现在合并数据集的最常见的起始前缀。我还将max_length ,以努力创造一个更强大的数据点集,但这可能会引入许多混淆因素,而不是有益因素。试着把max_length 降低到10,看看性能如何变化。
def prepareData(lang1, lang2,reverse = False):
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse)
print("Read %s sentence pairs" % len(pairs))
pairs = filterPairs(pairs)
print("Trimmed to %s sentence pairs" % len(pairs))
print("Counting words...")
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("Counted words:")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('eng', 'fra', True)
print(random.choice(pairs))
最后,prepareData函数将所有的辅助函数放在一起,过滤并最终确定用于NMT训练的语言对。现在我们的数据集已经准备好了,让我们跳到翻译器本身的代码。
翻译器
编码器
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
我们使用的编码器与教程中的基本相同,而且可能是我们在本文中要剖析的最简单的一点代码。我们可以从正向函数中看到,对于每个输入元素,编码器都会输出一个输出向量和一个隐藏状态。然后,该隐藏状态被返回,所以它可以和输出一起被用于下面的步骤。
注意力-解码器
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
既然我们在这个例子中使用了注意力,我们就来看看如何在解码器中实现它。显而易见,编码器和解码器网络之间有一些关键的区别,远远超出了它们行为的简单反转。
首先,init()函数有一个额外的2个参数:max_length 和dropout_p 。max_length 是一个句子可以容纳的最大元素数,以便考虑。由于两个配对数据集中的句子长度变化很大,我们设置了这个参数。dropout_p ,以帮助正则化和防止神经元的共同适应。
第二,我们有注意力层本身。在每个步骤中,注意力层接收注意力输入、解码器状态和所有编码器状态。它利用这一点来计算注意力的分数。对于每个编码器状态,注意力计算它与这个解码器状态的 "相关性"。它应用一个注意力函数,接收一个解码器状态和一个编码器状态并返回一个标量值。注意力的分数被用来计算注意力的权重。这些权重是一个概率分布,通过对注意力分数应用softmax 。最后,它将注意力输出计算为具有注意力权重的编码器状态的加权和。(1)
这些额外的参数和注意力机制使解码器需要更少的训练和整体信息来发展对序列中所有词的关系的理解。
训练
teacher_forcing_ratio = 0.5
def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):
encoder_hidden = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(
input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
# Teacher forcing: Feed the target as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach() # detach from history as input
loss += criterion(decoder_output, target_tensor[di])
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
我们所使用的训练函数需要几个参数。input_tensor 和target_tensor 分别是句子对的第0和第1个索引。编码器是上述的编码器。解码器是上文所述的注意力解码器。我们将编码器和解码器的优化器从随机梯度下降转换为Adagrad,因为我们发现使用Adagrad时,翻译的损失较低。最后,我们正在使用交叉熵损失作为我们的标准,而不是使用nn.NLLLoss()的教程。
我们还应该看一下教师的强迫率。这个值被设置为0.5,用于帮助提高模型的功效。在0.5时,它随机决定是否将目标作为下一个输入给解码器,或者使用解码器自己的预测。这可以帮助翻译更快地收敛,但也可能导致不稳定。例如,过度使用教师强制,可能会产生一个具有准确语法输出的模型,但与输入没有翻译关系。
def trainIters(encoder, decoder, n_iters, print_every=1000, plot_every=100):
start = time.time()
plot_losses = []
print_loss_total = 0 # Reset every print_every
plot_loss_total = 0 # Reset every plot_every
encoder_optimizer = optim.Adagrad(encoder.parameters())
decoder_optimizer = optim.Adagrad(decoder.parameters())
training_pairs = [tensorsFromPair(random.choice(pairs))
for i in range(n_iters)]
criterion = nn.CrossEntropyLoss()
for iter in range(1, n_iters + 1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = train(input_tensor, target_tensor, encoder,
decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total += loss
plot_loss_total += loss
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters),
iter, iter / n_iters * 100, print_loss_avg))
if iter % plot_every == 0:
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
showPlot(plot_losses)
TrainIters实际上实现了训练过程。对于预设的迭代次数,它将计算出损失。该函数继续保存损失值,以便在训练完成后可以有效地绘制它们。
要深入了解这个翻译器的代码,请确保查看包含所有这些信息的梯度笔记本演示以及Github页面。
翻译
hidden_size = 256
encoder = EncoderRNN(input_lang.n_words, hidden_size).to(device)
attn_decoder = AttnDecoderRNN(hidden_size, output_lang.n_words, dropout_p=0.1).to(device)
trainIters(encoder1, attn_decoder1, 75000, print_every=5000)
现在我们已经建立了我们的翻译器,我们需要做的就是实例化我们的编码器和注意力解码器模型进行训练并执行trainIters函数。确保你在训练单元之前运行笔记本中的所有单元,以启用辅助函数。
我们将使用256的隐藏大小,并确保你的设备设置为device(type='cuda') 。这将确保RNN使用GPU进行训练。
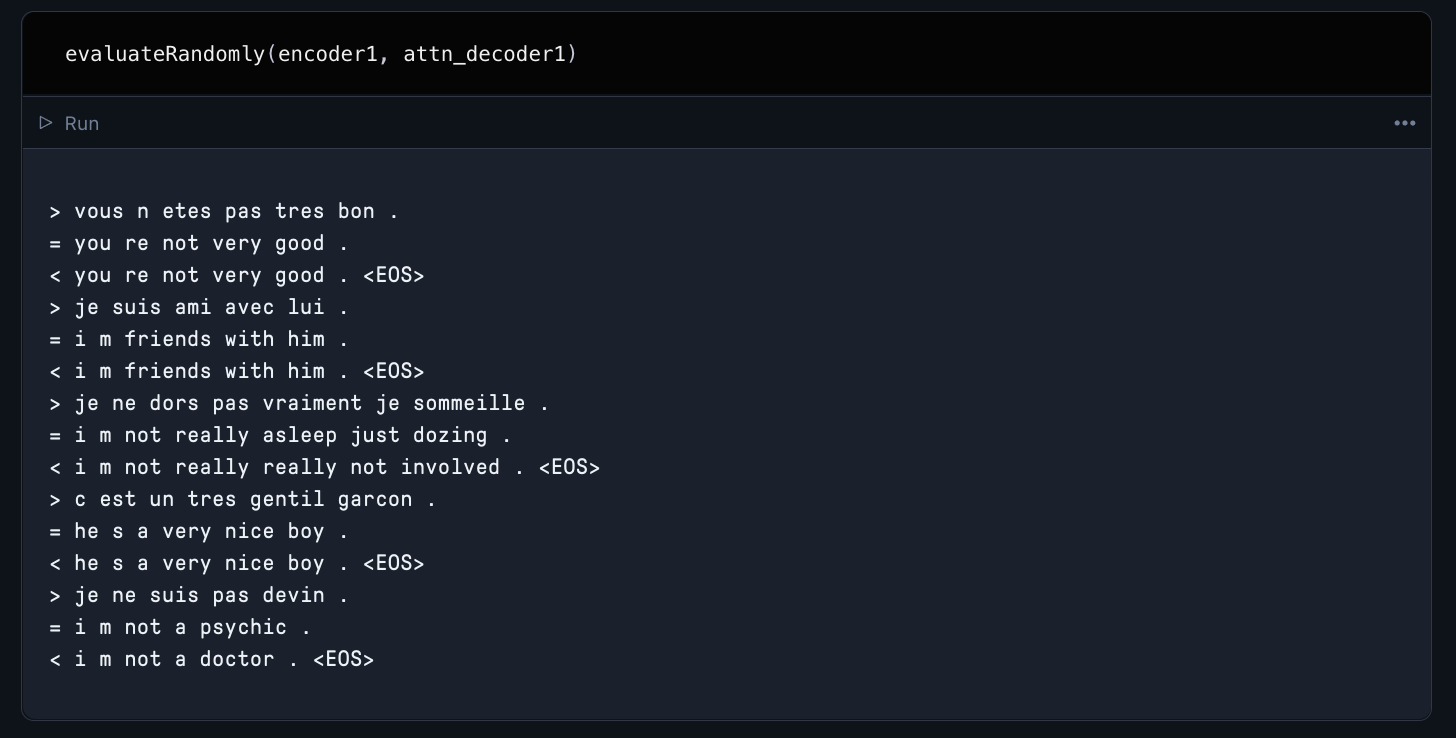
当你运行这个单元时,你的模型将训练75,000次迭代。一旦训练完成,使用所提供的评估函数来评估你的新翻译模型的定性性能。下面是一个例子,说明我们为演示训练的模型在随机抽样的翻译上的表现。
结束思考
你现在应该能够采取任何适当的翻译数据集,并将其插入这个翻译器代码中。我建议从其他WMT Europarl配对中的一个开始,但也有无限的选择。一定要在Gradient上运行这个程序,以获得强大的GPU!
如果你克隆了Github repo或者在Gradient中使用它作为工作区的URL,你可以访问包含本文代码的笔记本。一共有三个笔记本。数据处理是你应该首先进入并运行的笔记本。然后是本文中的代码,用于在Europarl法语-英语数据集上实现Seq2Seq翻译。
