



在生成对抗网络(GANs)所能实现的众多奇迹中,例如从头开始生成全新的实体,它们还有另一个奇妙的用例,即图像到图像的翻译。在以前的博客中,我们了解了条件型GANs的实现。这些条件型GANs的特点是能够执行一项任务,以获得提供给训练网络的特定输入的所需输出。在我们继续讨论本文中这些条件型GAN的变体之一之前,我建议从这个链接中查看CGAN的实现。
在这篇文章中,我们将探讨GAN的变体之一,由于它能够将图像从源域高精度地翻译到目标域,因此近年来得到了极大的欢迎:pix2pix GANs。我们将先简单介绍一下关注本博客所需的基础知识,然后再通过架构分解来了解pix2pix GAN研究论文。最后,我们将利用pix2pix GANs从头开始开发一个卫星图像到地图的翻译项目。
可以利用Paperspace Gradient平台来运行以下项目,方法是使用以下链接的repo作为 "工作区URL "来创建Paperspace Gradient笔记本。 这个字段可以通过切换笔记本创建页面上的高级选项按钮找到。
介绍一下。
条件型GANs的主要应用之一是这些网络能够进行高度精确的图像到图像的翻译。图像到图像的翻译是一项任务,在这项任务中,我们从一个特定的领域获取图像,并通过对其进行特定任务所需的转换,将其转换成另一个领域的图像。人们可以从事各种各样的图像翻译项目,包括将黑白图像转换为彩色图像,将动画草图转换为逼真的人体图片,以及其他很多类似的想法。
之前已经利用了许多方法来进行高精度的图像到图像的翻译。然而,一个天真的CNN方法来最小化预测和地面真实像素之间的欧几里得距离往往会产生模糊的结果。产生模糊效果的主要原因是,欧氏距离是通过对所有可信的输出进行平均来实现的。pix2pix条件性GAN修复了这些基本问题中的大部分。模糊的图像将被判别器网络确定为假样本,解决了以前CNN方法的一个主要问题。在接下来的章节中,我们将对这些pix2pix条件GANs有更多的概念性理解。
了解pix2pix GANs。

以前有许多方法被用来执行各种图像翻译任务。然而,从历史上看,大多数原始的方法都失败了,包括一些来自流行的深度学习框架。当大多数方法在生成任务中挣扎时,生成对抗网络在大多数情况下都能成功。用于图像翻译的最佳网络之一是pix2pix GANs。在本节中,我们将分解这些pix2pix GANs的程序性工作,并尝试理解pix2pix GAN架构的生成器和鉴别器网络的复杂细节。
生成器架构利用了U-Net的架构设计。我们已经在我以前的一篇博客中详细介绍了这个话题,你可以从这个链接中查看。U-Net架构使用一个编码器-解码器类型的结构,我们在架构的前半部分对卷积层进行了下采样,而后半部分则是利用卷积转置等层的上采样来调整到更高的图像比例。传统的U-Net架构略显老旧,因为它最初是在2015年开发的,而神经网络从那时起就有了巨大的进步。
因此,pix2pix GAN的这个生成器网络中使用的U-Net架构是原始U-Net架构的一个略微修改版本。虽然编码器-解码器结构,以及跳过连接,是两个网络的关键方面;但也有一些值得注意的关键区别。原始U-Net架构中的图像尺寸从原来的尺寸变成了一个新的较小的高度和宽度。在pix2pix GAN网络中,生成器网络保留了图像的大小和尺寸。我们还在pix2pix生成器网络中只使用了一个卷积层块,而不是原来使用的两个块。最后,U-Net网络按比例缩小到32×32左右的最大值,而生成器网络则一直缩小到1×1。
至于提议的判别器架构,pix2pix GAN利用了一种补丁式的方法,只在补丁的尺度上惩罚结构。虽然GAN架构中的大多数复杂判别器利用整个图像来建立一个假的或真的(0或1)值,但补丁GAN试图对图像中的每个N×N补丁进行分类,以确定是真还是假。对于每个具体的任务,N×N补丁的大小可以不同,但最终的最终输出是所考虑的补丁的所有反应的平均值。补丁GAN判别器的主要优势发生于这样的事实:它们的训练参数较少,运行速度较快,并且可以应用于任意大的图像。
在pix2pix GANs的帮助下,我们可以进行许多实验。其中一些实验包括将语义标签翻译成城市景观的照片,将建筑标签翻译成外墙数据集上的照片,将黑白图像翻译成彩色图像,将动画草图翻译成真实的人类图片,等等。在这个项目中,我们将专注于卫星地图到航拍照片的转换,在从谷歌地图刮来的数据上进行训练。
使用pix2pix GANs进行卫星图像到地图的转换。
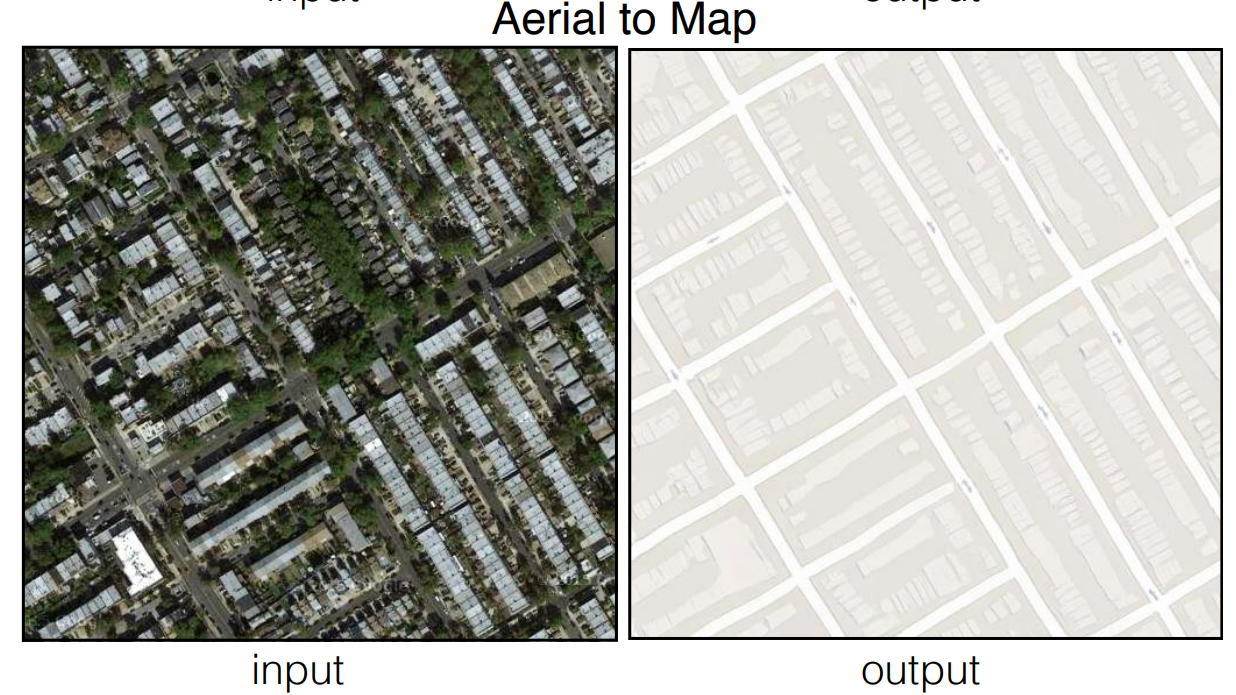
在文章的这一部分,我们将专注于从头开始开发一个pix2pix GAN架构,用于卫星图像到其各自地图的转换。在开始学习本教程之前,我强烈建议大家查看我之前的博客中的TensorFlow文章以及Keras文章。这两个库将是我们构建以下项目时要利用的主要深度学习框架。该项目被分为许多小的子部分,以便更容易理解完成所需任务的所有步骤。让我们从导入所有基本库开始。
导入基本库
如前所述,我们将利用的两个主要深度学习框架是TensorFlow和Keras。最有用的层包括卷积层、Leaky ReLU激活函数、批量归一化、辍学层和其他一些基本层。我们还将导入NumPy库来处理数组,并相应地生成真实和虚假图像。Matplotlib库被用来绘制所需的图形和必要的图。请看下面的代码块,了解我们在构建这个项目时将使用的所有必要的库和导入。
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.initializers import RandomNormal
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, Conv2DTranspose, LeakyReLU, Activation
from tensorflow.keras.layers import BatchNormalization, Concatenate, Dropout
from keras.preprocessing.image import img_to_array
from keras.preprocessing.image import load_img
from tensorflow.keras.utils import plot_model
from tensorflow.keras.models import load_model
from os import listdir
from numpy import asarray, load
from numpy import vstack
from numpy import savez_compressed
from matplotlib import pyplot
import numpy as np
from matplotlib import pyplot as plt
from numpy.random import randint
from numpy import zeros
from numpy import ones
准备数据。
通过观察和分析我们的数据,我们可以注意到,我们有一个包含地图和各自卫星图像的整体图像。在接下来的代码块中,我们将定义我们的数据集的路径。我建议想在教程旁边做实验的读者从Kaggle下载这个数据集。下面的数据集旨在作为图像到图像翻译问题的一个通用解决方案。他们有四个数据集,我们可以利用它们来开发Pix2Pix GANs。这些数据集包括外墙、城市景观、地图和边缘到鞋子。
你也可以下载任何其他你想测试模型工作程序的附加下载。对于这篇文章,我们将利用地图数据集。在下面的代码块中,我已经定义了我的目录的特定路径,该目录包含地图数据与训练和验证目录。请自由地设置你自己的相应的路径位置。我们还将定义一些基本参数,通过这些参数可以更容易地完成一些编码程序。由于图像同时包含了卫星图像和各自的地图,我们可以将它们平均分割,因为它们的尺寸都是256 x 256,如下面的代码块所示。
# load all images in a directory into memory
def load_images(path, size=(256,512)):
src_list, tar_list = list(), list()
for filename in listdir(path):
# load and resize the image
pixels = load_img(path + filename, target_size=size)
# convert to numpy array
pixels = img_to_array(pixels)
# split into satellite and map
sat_img, map_img = pixels[:, :256], pixels[:, 256:]
src_list.append(sat_img)
tar_list.append(map_img)
return [asarray(src_list), asarray(tar_list)]
# dataset path
path = 'maps/train/'
# load dataset
[src_images, tar_images] = load_images(path)
print('Loaded: ', src_images.shape, tar_images.shape)
n_samples = 3
for i in range(n_samples):
pyplot.subplot(2, n_samples, 1 + i)
pyplot.axis('off')
pyplot.imshow(src_images[i].astype('uint8'))
# plot target image
for i in range(n_samples):
pyplot.subplot(2, n_samples, 1 + n_samples + i)
pyplot.axis('off')
pyplot.imshow(tar_images[i].astype('uint8'))
pyplot.show()
Loaded: (1096, 256, 256, 3) (1096, 256, 256, 3)

U-Net生成器网络。
为了构建pix2pix GAN架构的生成器网络,我们将把该结构分为几个部分。我们将从编码器块开始,在这里我们将定义卷积层,其步长为2,然后是Leaky ReLU激活函数。大多数卷积层之后还将是批量归一化层,如下面的代码块所示。一旦我们返回生成器网络的编码器块,我们就可以构建网络的前半部分,如下所示 - C64-C128-C256-C512-C512-C512-C512。
# Encoder Block
def define_encoder_block(layer_in, n_filters, batchnorm=True):
init = RandomNormal(stddev=0.02)
g = Conv2D(n_filters, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(layer_in)
if batchnorm:
g = BatchNormalization()(g, training=True)
g = LeakyReLU(alpha=0.2)(g)
return g
我们将定义发生器网络的下一个部分是解码器块。在这个功能中,我们将对所有先前被降频的图像进行上采样,以及添加(连接)必要的跳过连接,这些连接必须从编码器到解码器网络,类似于U-Net架构。对于模型的上采样,我们可以利用卷积转置层与批量归一化层和可选的滤波层。生成器网络的解码器块包含如下架构--CD512-CD512-CD512-C512-C256-C128-C64。下面是以下结构的代码块。
# Decoder Block
def decoder_block(layer_in, skip_in, n_filters, dropout=True):
init = RandomNormal(stddev=0.02)
g = Conv2DTranspose(n_filters, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(layer_in)
g = BatchNormalization()(g, training=True)
if dropout:
g = Dropout(0.5)(g, training=True)
# merge with skip connection
g = Concatenate()([g, skip_in])
g = Activation('relu')(g)
return g
现在,我们已经构建了之前的两个主要功能,即编码器和解码器块,我们可以继续多次调用它们,以根据必要的要求来调整网络。我们将按照之前在本节中讨论的编码器和解码器网络结构,相应地构建这些块。大部分的结构是按照下面的研究论文来构建的。最终的输出激活函数tanh生成的图像范围为-1到1。请自由尝试任何其他较小的修改,通过修改一些参数,有可能产生更好的结果。下面提供了生成器网络的代码块。
# Define the overall generator architecture
def define_generator(image_shape=(256,256,3)):
# weight initialization
init = RandomNormal(stddev=0.02)
# image input
in_image = Input(shape=image_shape)
# encoder model: C64-C128-C256-C512-C512-C512-C512-C512
e1 = define_encoder_block(in_image, 64, batchnorm=False)
e2 = define_encoder_block(e1, 128)
e3 = define_encoder_block(e2, 256)
e4 = define_encoder_block(e3, 512)
e5 = define_encoder_block(e4, 512)
e6 = define_encoder_block(e5, 512)
e7 = define_encoder_block(e6, 512)
# bottleneck, no batch norm and relu
b = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(e7)
b = Activation('relu')(b)
# decoder model: CD512-CD512-CD512-C512-C256-C128-C64
d1 = decoder_block(b, e7, 512)
d2 = decoder_block(d1, e6, 512)
d3 = decoder_block(d2, e5, 512)
d4 = decoder_block(d3, e4, 512, dropout=False)
d5 = decoder_block(d4, e3, 256, dropout=False)
d6 = decoder_block(d5, e2, 128, dropout=False)
d7 = decoder_block(d6, e1, 64, dropout=False)
# output
g = Conv2DTranspose(image_shape[2], (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d7) #Modified
out_image = Activation('tanh')(g) #Generates images in the range -1 to 1. So change inputs also to -1 to 1
# define model
model = Model(in_image, out_image)
return model
把这个项目带入生活
补丁GAN判别器网络。
一旦生成器网络构建完毕,我们就可以着手进行判别器架构的工作。我们将初始化我们的权重并合并输入的源图像和目标图像,然后再继续构建判别器结构。鉴别器结构将遵循C64-C128-C256-C512的模式构建。在最后一层之后,应用卷积法来映射到一维输出,然后是sigmoid函数。下面代码块中使用的判别器网络允许尺寸低至16 x 16。最后,我们可以把用一个图像的批处理规模和亚当优化器训练的模型编译成一个小的学习率和0.5的β值。每次模型更新时,判别器的损失被加权为50%。查看下面的代码片段,了解完整的补丁GAN判别器网络。
def define_discriminator(image_shape):
# weight initialization
init = RandomNormal(stddev=0.02)
# source image input
in_src_image = Input(shape=image_shape)
# target image input
in_target_image = Input(shape=image_shape)
# concatenate images, channel-wise
merged = Concatenate()([in_src_image, in_target_image])
# C64: 4x4 kernel Stride 2x2
d = Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(merged)
d = LeakyReLU(alpha=0.2)(d)
# C128: 4x4 kernel Stride 2x2
d = Conv2D(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# C256: 4x4 kernel Stride 2x2
d = Conv2D(256, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# C512: 4x4 kernel Stride 2x2
d = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# second last output layer : 4x4 kernel but Stride 1x1 (Optional)
d = Conv2D(512, (4,4), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# patch output
d = Conv2D(1, (4,4), padding='same', kernel_initializer=init)(d)
patch_out = Activation('sigmoid')(d)
# define model
model = Model([in_src_image, in_target_image], patch_out)
opt = Adam(lr=0.0002, beta_1=0.5)
# compile model
model.compile(loss='binary_crossentropy', optimizer=opt, loss_weights=[0.5])
return model
定义完整的GAN架构。
现在我们已经定义了生成器和鉴别器网络,我们可以根据需要继续训练整个GAN架构。鉴别器中的权重是不可训练的,但独立的鉴别器是可训练的。因此,我们将相应地设置这些参数。然后,我们将把源图像作为模型的输入,而模型的输出将包含生成的结果和判别器的输出。总损失被计算为对抗性损失(BCE)和L1损失(MAE)的加权和,权重为1:100。我们可以用这些参数和亚当优化器编译模型,以返回最终的模型。
# define the combined GAN architecture
def define_gan(g_model, d_model, image_shape):
for layer in d_model.layers:
if not isinstance(layer, BatchNormalization):
layer.trainable = False
in_src = Input(shape=image_shape)
gen_out = g_model(in_src)
dis_out = d_model([in_src, gen_out])
model = Model(in_src, [dis_out, gen_out])
# compile model
opt = Adam(lr=0.0002, beta_1=0.5)
model.compile(loss=['binary_crossentropy', 'mae'],
optimizer=opt, loss_weights=[1,100])
return model
定义所有的基本参数。
在下一步,我们将定义训练pix2pix GAN模型所需的所有基本功能和参数。首先,让我们定义生成真实和虚假样本的函数。下面提供了执行以下操作的代码片段。
def generate_real_samples(dataset, n_samples, patch_shape):
trainA, trainB = dataset
ix = randint(0, trainA.shape[0], n_samples)
X1, X2 = trainA[ix], trainB[ix]
y = ones((n_samples, patch_shape, patch_shape, 1))
return [X1, X2], y
def generate_fake_samples(g_model, samples, patch_shape):
X = g_model.predict(samples)
y = zeros((len(X), patch_shape, patch_shape, 1))
return X, y
在下一个代码块中,我们将创建一个函数来总结我们模型的性能。生成的图像将与它们的原始对应物进行比较,以获得期望的反应。我们可以为源图像、生成的图像和目标输出图像绘制三个图形。我们可以保存该图和生成器模型,以便以后根据需要用于进一步计算。
#save the generator model and check how good the generated image looks.
def summarize_performance(step, g_model, dataset, n_samples=3):
[X_realA, X_realB], _ = generate_real_samples(dataset, n_samples, 1)
X_fakeB, _ = generate_fake_samples(g_model, X_realA, 1)
# scale all pixels from [-1,1] to [0,1]
X_realA = (X_realA + 1) / 2.0
X_realB = (X_realB + 1) / 2.0
X_fakeB = (X_fakeB + 1) / 2.0
# plot real source images
for i in range(n_samples):
plt.subplot(3, n_samples, 1 + i)
plt.axis('off')
plt.imshow(X_realA[i])
# plot generated target image
for i in range(n_samples):
plt.subplot(3, n_samples, 1 + n_samples + i)
plt.axis('off')
plt.imshow(X_fakeB[i])
# plot real target image
for i in range(n_samples):
plt.subplot(3, n_samples, 1 + n_samples*2 + i)
plt.axis('off')
plt.imshow(X_realB[i])
# save plot to file
filename1 = 'plot_%06d.png' % (step+1)
plt.savefig(filename1)
plt.close()
# save the generator model
filename2 = 'model_%06d.h5' % (step+1)
g_model.save(filename2)
print('>Saved: %s and %s' % (filename1, filename2))
最后,让我们定义训练函数,通过该函数我们可以训练模型,并根据需要调用所有适当的函数来生成样本,总结模型性能,以及对批量函数进行训练。一旦我们创建了pix2pix模型的训练函数,我们就可以继续训练模型并生成卫星图像到地图图像转换任务的结果。下面是训练函数的代码块。
# train function for the pix2pix model
def train(d_model, g_model, gan_model, dataset, n_epochs=100, n_batch=1):
n_patch = d_model.output_shape[1]
trainA, trainB = dataset
bat_per_epo = int(len(trainA) / n_batch)
n_steps = bat_per_epo * n_epochs
for i in range(n_steps):
[X_realA, X_realB], y_real = generate_real_samples(dataset, n_batch, n_patch)
X_fakeB, y_fake = generate_fake_samples(g_model, X_realA, n_patch)
d_loss1 = d_model.train_on_batch([X_realA, X_realB], y_real)
d_loss2 = d_model.train_on_batch([X_realA, X_fakeB], y_fake)
g_loss, _, _ = gan_model.train_on_batch(X_realA, [y_real, X_realB])
# summarize model performance
print('>%d, d1[%.3f] d2[%.3f] g[%.3f]' % (i+1, d_loss1, d_loss2, g_loss))
if (i+1) % (bat_per_epo * 10) == 0:
summarize_performance(i, g_model, dataset)
训练pix2pix模型。
一旦我们构建了整个生成器和鉴别器网络,并将它们结合到GAN架构中,以及完成了所有基本参数和数值的声明,我们就可以开始最终训练pix2pix模型并观察其性能。我们将通过源的图像形状,构建与生成器和鉴别器网络有关的GAN架构。
我们将定义输入的源图像和目标图像,然后对这些图像进行相应的归一化处理,使其在所需的-1到1的范围内进行缩放,因为输出的tanh激活函数将执行。最后我们可以开始模型的训练,并在十个 epochs之后评估性能。每一批(总共1096个)的参数都会在每个历时中报告。对于十个epochs,我们应该注意到总共有10960个。下面是训练模型的代码片断。
image_shape = src_images.shape[1:]
d_model = define_discriminator(image_shape)
g_model = define_generator(image_shape)
gan_model = define_gan(g_model, d_model, image_shape)
data = [src_images, tar_images]
def preprocess_data(data):
X1, X2 = data[0], data[1]
# scale from [0,255] to [-1,1]
X1 = (X1 - 127.5) / 127.5
X2 = (X2 - 127.5) / 127.5
return [X1, X2]
dataset = preprocess_data(data)
from datetime import datetime
start1 = datetime.now()
train(d_model, g_model, gan_model, dataset, n_epochs=10, n_batch=1)
stop1 = datetime.now()
#Execution time of the model
execution_time = stop1-start1
print("Execution time is: ", execution_time)
>10955, d1[0.517] d2[0.210] g[8.743]
>10956, d1[0.252] d2[0.693] g[5.987]
>10957, d1[0.243] d2[0.131] g[12.658]
>10958, d1[0.339] d2[0.196] g[6.857]
>10959, d1[0.010] d2[0.125] g[4.013]
>10960, d1[0.085] d2[0.100] g[10.957]
>Saved: plot_010960.png and model_010960.h5
Execution time is: 0:39:10.933599
训练模型的程序在我的系统上执行了大约40分钟。训练的时间会因你的GPU和设备的特性而有所不同。Paperspace上的梯度平台是这种训练机制的一个很好的可行选择。训练完成后,我们有一个模型和一个绘图可供使用。该模型可以被加载,并且可以对其进行相应的必要预测。下面是加载模型的代码块,以及进行必要的预测和它们各自的图。
# Plotting the Final Results
model = load_model('model_010960.h5')
# plot source, generated and target images
def plot_images(src_img, gen_img, tar_img):
images = vstack((src_img, gen_img, tar_img))
# scale from [-1,1] to [0,1]
images = (images + 1) / 2.0
titles = ['Source', 'Generated', 'Expected']
# plot images row by row
for i in range(len(images)):
pyplot.subplot(1, 3, 1 + i)
pyplot.axis('off')
pyplot.imshow(images[i])
pyplot.title(titles[i])
pyplot.show()
[X1, X2] = dataset
# select random example
ix = randint(0, len(X1), 1)
src_image, tar_image = X1[ix], X2[ix]
# generate image from source
gen_image = model.predict(src_image)
# plot all three images
plot_images(src_image, gen_image, tar_image)

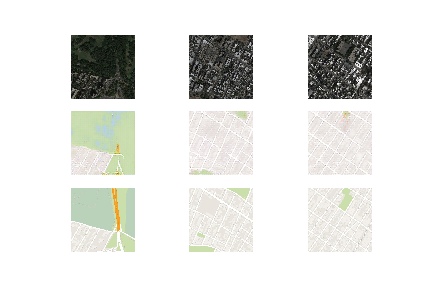
我强烈建议查看以下网站,该网站的大部分代码都被考虑在内。作为下一步,我们强烈建议观众尝试许多组合,这可能有助于产生更好的结果。浏览者也可以选择实施更多次数的训练,以尝试达到更理想的结果。除了这个项目之外,pix2pix GANs在各种项目中都有很高的实用性。我建议尝试许多项目以更好地了解这些生成网络的能力。
结语。

从一张图片到另一张图片的翻译是一项相当复杂的任务,因为简单的卷积网络由于缺乏特征提取能力而无法以最理想的方式完成这项任务。另一方面,GANs在生成一些具有高精确度和准确性的最佳图像方面做得非常出色。它们还有助于避免简单卷积网络的一些乏善可陈的效果,如输出清晰、逼真的图像等。因此,引入的pix2pix GAN架构是解决此类问题的最佳GAN版本之一。pix2pix GAN软件甚至被艺术家和多个用户通过互联网利用来实现高质量的结果。
在这篇文章中,我们重点讨论了pix2pix GANs中最重要的条件型GANs类型之一,用于图像翻译。我们学习了更多关于图像翻译的话题,并了解了与pix2pix GANs及其功能机制有关的大部分基本概念。一旦我们涵盖了pix2pix GAN的基本方面,包括生成器和判别器架构,我们就开始构建卫星图像翻译成地图的项目。我们强烈建议观众尝试其他类似的项目,以及尝试pix2pix GAN架构的生成器和判别器网络可能出现的不同类型的变化的一些可能性。
在未来的文章中,我们将专注于用pix2pix GANs建立更多的项目,因为这些条件网络有许多可能性。我们还将探索其他类型的GANs,如循环GANs,以及其他关于BERT变压器和从零开始构建神经网络(第二部分)的教程和项目。在那之前,请享受编码和构建新项目的乐趣!
今天就为你的机器学习工作流程增加速度和简单性吧
