1、什么是DOM:Document Object Model(文档对象模型)
将每一个标签、元素、属性、文本、注释,都看作一个DOM节点/元素/对象(提供了一些操作元素的属性和方法)
面试题:HTML/XHTML/DHTML/XML分别是什么?
1、HTML - 网页
2、XHTML - 更严格的网页
3、DHTML - 动态的网页:D:Dynamic:其实并不是新技术、新概念,是将现有技术的整合的统称,使我们的网页在离线状态依然具有动态效果
DHTML=HTML+CSS+JS(dom)
4、XML - 数据格式
DOM:原本是可以操作一切结构化文档的 HTML 和 XML,后来为了方便各类开发者细分为了3部分:
1、核心DOM:【无敌的】,既可以操作HTML,又可以操作XML
缺点:API比较繁琐
2、HTML DOM:只能操作HTML,优点:API非常简单
缺点:比如属性部分,只能访问/设置标准属性,不能操作自定义属性
3、XML DOM:只能操作XML,XML已经淘汰了,现在最流行的数据格式是JSON
开发建议:优先使用HTML DOM,HTML DOM满足不了的操作我们再用核心DOM进行补充
2、DOM树:树根:document - 不需要我们创建,一个页面只有一个document对象,由JS解释器自动创建
可以通过树根找到每一个DOM元素/节点/对象,提供了很多很多的API等待我们学习
3、每个DOM元素都有三大属性
1、xx.nodeType - 描述节点的类型
document节点:9
element节点:1
attribute节点:2
text节点:3
以前有用:判断xx是不是一个页面元素,因为我们以前没有children找儿子,只有childNodes
2、xx.nodeValue - 获取元素的属性值的
以前有用:获取一个属性节点的值,因为以前没有getAttribute,只有getAttributeNode
3、*xx.nodeName:节点的名称 - 判断xx是什么标签
注意:返回的是一个全大写的标签名!

4、*通过关系获取元素:
父:xx.parentNode
子:xx.children
第一个儿子:xx.firstElementChild
最后一个儿子:xx.lastElementChild
前一个兄弟:xx.previousElementSibling
后一个兄弟:xx.nextElementSibling
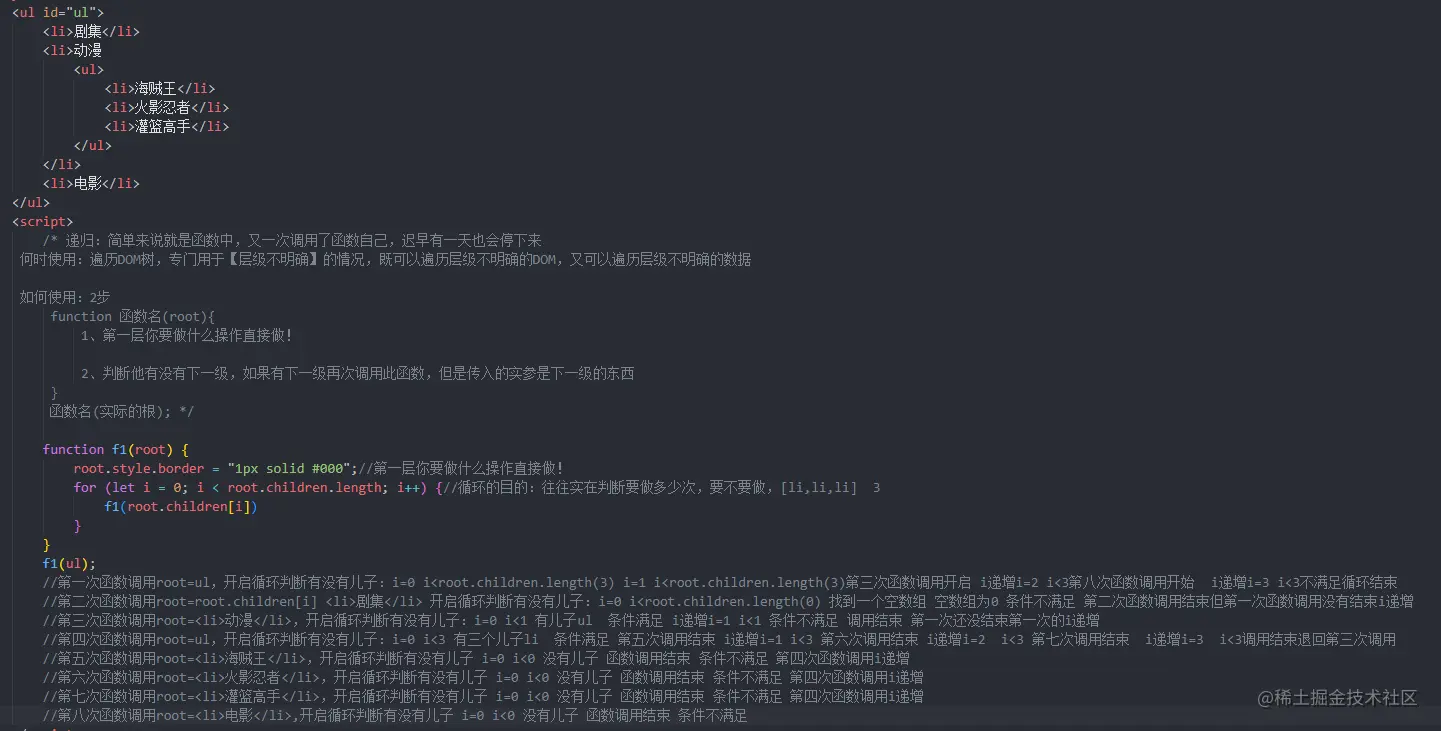
5、递归:简单来说就是函数中,又一次调用了函数自己,迟早有一天也会停下来
何时使用:遍历DOM树,专门用于【层级不明确】的情况,既可以遍历层级不明确的DOM,又可以遍历层级不明确的数据
如何使用:2步
function 函数名(root){
1、第一层你要做什么操作直接做!
2、判断他有没有下一级,如果有下一级再次调用此函数,但是传入的实参是下一级的东西
}
函数名(实际的根);
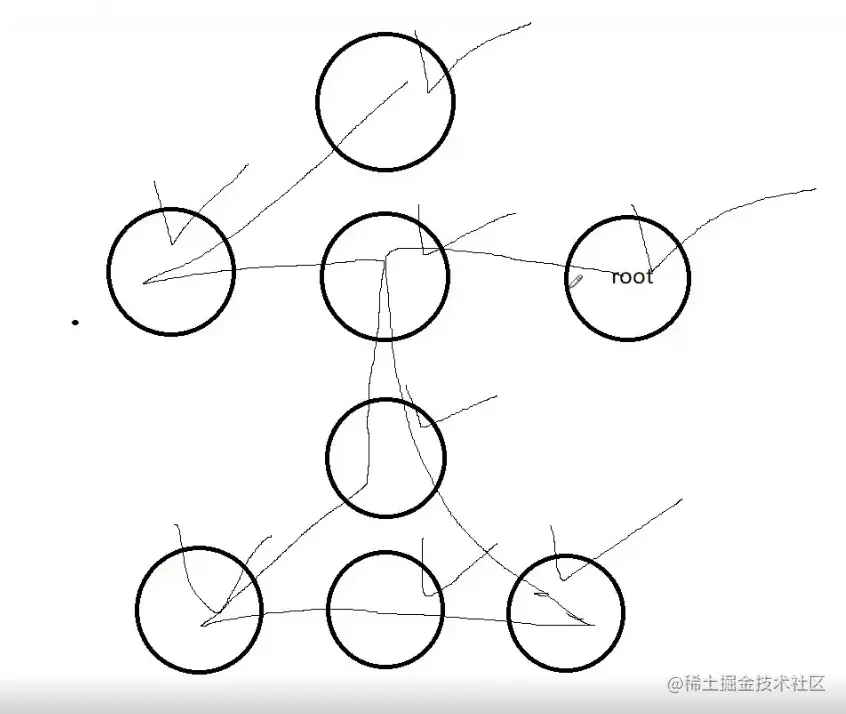
算法:深度优先!优先遍历当前节点的子节点,子节点遍历完毕后才会跳到兄弟节点
缺点:同时开启大量的函数调用,消耗大量的内存,只有一个情况才会使用:【遍历层级不明确】
递归 vs 纯循环
递归:优点:直观易用
缺点:性能低下
纯循环:优点:性能高,几乎不占用内存
缺点:难得批爆
6、遍历层级不明确的API
语法:1、创建tw对象
var tw=document.createTreeWalker(根元素,NodeFilter.SHOW_ELEMENT)
2、反复调用tw的nextNode()函数找到每一个元素
while((node=tw.nextNode())!=null){
node要干什么操作
}
缺点:1、必然跳过根元素,不会对根元素做操作
2、不可以遍历层级不明确的数据,仅能遍历层级不明确的DOM元素
7、*API直接找到元素
1、通过HTML的一些特点去找元素
(1)、id:var elem=document.getElementById("id值")
(2)、标签名和class名和Name名:var elems=document/parent.getElementsByTagName/ClassName/Name("标签名/class名")
name这个属性,input必写,那我们以后input就可以不class了
2、*通过css选择器获取元素:
(1)、单个元素:var elem=document.querySelector("任意css选择器");
强调:
1、万一选择器匹配到多个,只会返回第一个
2、没找到null
(2)、*多个元素:var elems=document.querySelectorAll("任意css选择器");
强调:找到了 返回集合,没找到返回空集合
更适合用于做复杂查找
面试题:getXXX 和 queryXXX的区别?
返回结果不同?
1、getXXX:返回的是一个动态集合HTMLCollection
2、queryXXX:返回的是一个静态集合NodeList
动态集合:根据DOM树的改变,悄悄的一起跟着变化,每一次修改DOM,都会悄悄的再次查找页面元素,缺点:性能低,而且不能使用forEach
静态集合:根据DOM树的改变,不会一起变化,只会认准当时找的时候的数据,优点:复杂查找时简单、性能高、使用forEach


