

什么是Kafka?
Kafka是一个事件流平台,它允许我们发布、订阅、存储和处理事件。一个事件表示所发生的事情,如果我们以To Do微服务为例,我们可以定义事件来表示TaskCreated ,或TaskUpdated ,当一个任务被创建或一个任务被更新时,分别表示。
Kafka是如何工作的?
在Kafka中,有一个概念叫做Topic,Topic存储了由Publisher发布的事件;这些Topic可以被命名以区分它们,它们可以被分区,这意味着它们可以被分成多个Kafka Broker,或者负责存储Topic的实例,定义各种分区允许扩展Kafka以允许多个发布者和消费者写入和读取数据。
当一个事件被发布到一个主题时,它将按照收到的顺序被存储,这使得消费者可以按照发布的顺序读取这些事件。
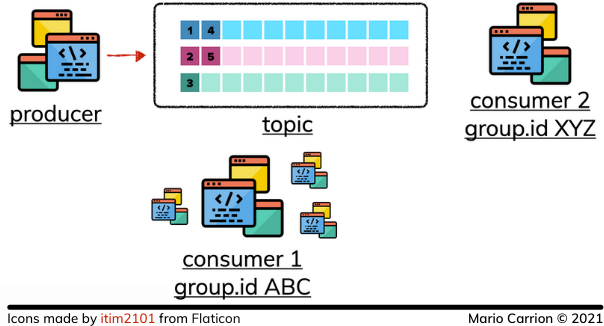
消费者在阅读事件时使用组ID来识别自己,这样多个进程可以以一种事件仍然按顺序消费的方式来消费同一个主题。
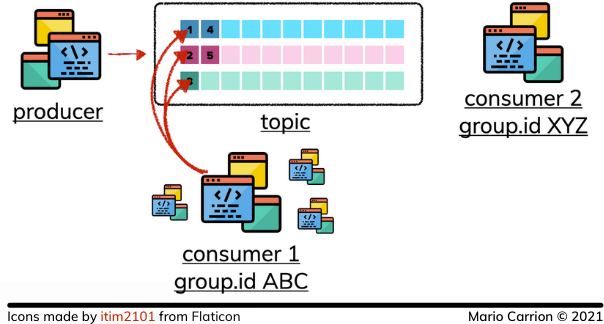
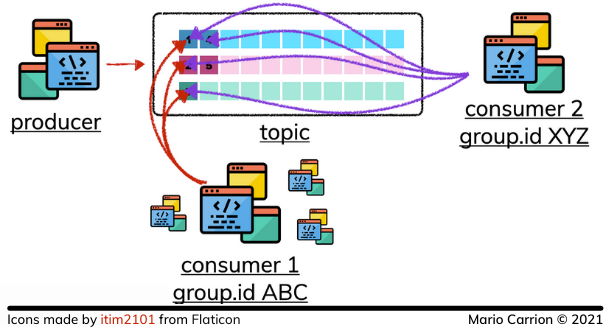
因为这些组ID,多个进程可以以不同的速度读取相同的数据而不影响其他消费者。
使用存储库的发布者实现
这篇文章使用的代码可以在Github上找到。
为了与Kafka进行通信,我们将使用官方软件包 confluentinc/confluent-kafka-go和我们之前实现的其他存储库类似,我们将定义一个新的包,名为kafka 。
这个包将实现相应的 Task负责发布事件,这些事件代表了任务变化时执行的行动,表示创建、删除和更新。
该代码看起来是这样的。
func (t *Task) Created(ctx context.Context, task internal.Task) error {
return t.publish(ctx, "Task.Created", "tasks.event.created", task)
}
func (t *Task) Deleted(ctx context.Context, id string) error {
return t.publish(ctx, "Task.Deleted", "tasks.event.deleted", internal.Task{ID: id})
}
func (t *Task) Updated(ctx context.Context, task internal.Task) error {
return t.publish(ctx, "Task.Updated", "tasks.event.updated", task)
}
这些导出的方法使用了一个未导出的方法,名为publish ,它直接与Kafka生产者进行交互,要发送的事件将使用encoding/json ,这个想法是为了定义一个JSON有效载荷,然后我们的消费者可以用来确定使用什么事件,更多内容在下面涉及消费者的部分。
func (t *Task) publish(ctx context.Context, spanName, routingKey string, e interface{}) error {
// XXX: Excluding OpenTelemetry and error checking for simplicity
var b bytes.Buffer
evt := event{
Type: msgType,
Value: task,
}
_ = json.NewEncoder(&b).Encode(evt)
_ = t.producer.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{
Topic: &t.topicName,
Partition: kafka.PartitionAny,
},
Value: b.Bytes(),
}, nil)
return nil
}
为了连接这个Kafka仓库和PostgreSQL仓库,我们将更新service.Task 中的每个方法来调用相应的发布相关的方法,例如。
func (t *Task) Create(ctx context.Context, description string, priority internal.Priority, dates internal.Dates) (internal.Task, error) {
// XXX: Excluding OpenTelemetry and error checking for simplicity
task, _ := t.repo.Create(ctx, description, priority, dates)
// XXX: Transactions will be revisited in future episodes.
_ = t.msgBroker.Created(ctx, task) // XXX: Ignoring errors on purpose
return task, nil
}
请参考原始代码,看看其他方法是如何被更新以做类似的事情。
对于消费事件,我们将定义一个新的程序,它将使用相同的主题来读取我们发布的数据,然后它将使用该仓库更新Elasticsearch的值。
消费者的实现
就像我上面提到的,新程序将消费Kafka事件,根据事件类型,它将调用相应的Elasticsearch方法来重新索引数值;这个程序也支持Graceful shutdown。
该程序使用 Consumer来轮询代表要读取的事件的值,简化后的代码看起来像。
for run {
msg, ok := s.kafka.Consumer.Poll(150).(*kafka.Message)
if !ok {
continue
}
var evt struct {
Type string
Value internaldomain.Task
}
_ = json.NewDecoder(bytes.NewReader(msg.Value)).Decode(&evt)
switch evt.Type {
case "tasks.event.updated", "tasks.event.created":
// call Elasticsearch to index record
case "tasks.event.deleted":
// call Elasticsearch to delete record
}
}
在构建你的最终程序时,考虑实现一个类似于服务器的类型,目的是将不同的接收到的事件分离成相应的类型,这样你的switch ,可以用一个指向被消费的每种类型的*"处理程序 "*的函数图来代替。
总结
Kafka是一个强大的处理事件的平台,它可以作为一个消息中介,在多个服务中分发信息,但它也支持存储和重放事件,以及分析他们收到的那些事件。
