

分页在Elasticsearch中是如何工作的?
Elasticsearch中索引的记录代表了与我们的搜索标准相匹配的大量可用值,这个集合由n条记录组成,它代表了我们可以返回给客户的最大total 。

考虑到这一点,Elasticsearch API的工作方式是使用两个值from 和size ,这使我们能够确定要检索的特定值。
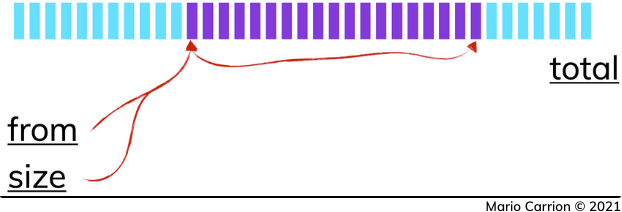

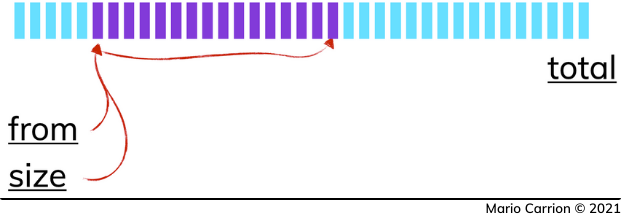
在实践中,这个API就像一个滑动窗口,我们必须明确指出该窗口的起点(from )和终点(from +size ),同时牢记我们可以检索的最大值(total )。
除了在搜索过程中指出这两个参数外,我们还应该根据我们试图搜索值的方式和我们计划用来对这些记录进行排序的方式来正确索引我们的记录,这是为了我们能够始终有一个确定的方式来获取结果。
另一个需要考虑的问题是,这种搜索记录的方式有一个局限性,如果我们想搜索超过10,000条记录,那么我们应该考虑使用像 搜索之后这样可以用更高级的方式来处理搜索结果。
为我们的Go服务添加分页支持
这篇文章使用的代码可以在Github上找到。
在之前的实现中,我们没有明确地为我们的记录创建映射,我们让Elasticsearch为我们做这个,这对我们的分页功能来说是不正确的,这次我们需要在索引新记录之前提前定义这个。
要做到这一点,我们必须指出在我们的映射中要使用的属性,以及每个字段应该使用的具体类型,在我们的案例中,做类似以下的事情就足够了。
curl -X PUT -H 'Content-Type: application/json' "http://localhost:9200/tasks" -d '
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"description": {
"type": "text"
}
}
}
}'
这样一来。
id被定义为keyword,这样我们就可以把它作为一个实际的ID来使用,同时也可以用于排序(如果你继续阅读,你会看到这是如何使用的),而description被定义为text,这是为了让我们可以通过描述的内容进行搜索。
接下来,我们必须更新我们的API,以支持这两个新字段和返回我们发现的结果的方法。我选择的方式是通过定义两个新的Args类型。
type SearchArgs struct {
Description *string
Priority *Priority
IsDone *bool
From int64
Size int64
}
type SearchResults struct {
Tasks []Task
Total int64
}
这两种类型都被添加到域包(internal )中,这样我们就可以在需要时为args类型添加具体的验证。在谈论领域驱动设计时,这种方法可能并不理想,但这是我在这里做出的权衡。
之后,我们要做的就是更新当前用于搜索的API,以支持这些新的类型,具体来说,我指的是ElasticsearchRepository,将它从:
func (t *Task) Search(ctx context.Context, description *string, priority *internal.Priority, isDone *bool) ([]internal.Task, error) {
func (t *Task) Search(ctx context.Context, args internal.SearchArgs) (internal.SearchResults, error) {
最后,我们应该更新搜索请求中的有效载荷,以使用这些新字段。
query["sort"] = []interface{}{
"_score",
map[string]interface{}{"id": "asc"},
}
query["from"] = args.From
query["size"] = args.Size
有了所有这些变化,我们就可以支持分页了!
总结
在Elasticsearch中实现分页是比较容易的,难的部分是定义正确的映射和搜索记录时使用的规则。真正的分页功能(在某种程度上)执行了这些映射的定义,并没有增加难度,当我们事先不知道客户打算如何搜索记录时,使用Elasticsearch一般来说是很困难的,一旦正式确定并实施,其他事情就会变得更好。
Elasticsearch有时会让人不知所措,但我向你保证,在阅读了官方文档之后,你的很多问题都会有具体的答案。
