

什么是缓存?
缓存是指在Go的微服务中存储并使用预先计算的值来进行昂贵的计算。使用memcached缓存》中,我介绍了在开始使用缓存之前需要考虑的另外两种方法,在这篇文章中,我假设你在投入时间实现缓存之前已经熟悉了这些方法。
缓存模式Write-Through是如何工作的?
Write-Through模式的工作原理是坐在Write-Only API旁边,当写请求发生时,将通过Read-Only API访问的预期数据被缓存起来。这意味着以下情况。
- 客户请求只写的API。
- 数据在持久性数据存储中被更新,以及
- 数据在缓存数据存储中被更新。
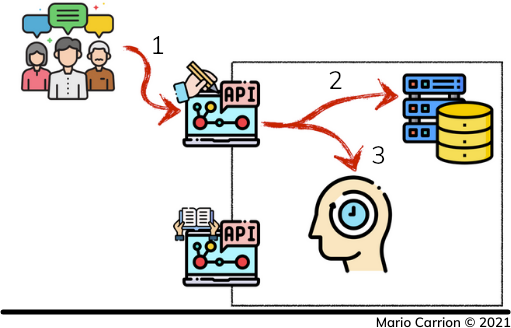
当客户使用只读API检索数据时,会发生以下情况。
- 客户请求只读API。
- API从缓存中请求数据。
- 缓存值被返回到我们的只读API,最后
- 信息被提供给我们的客户。
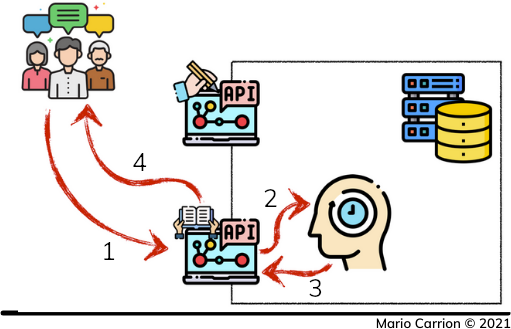
当使用Write-ThroughCaching Pattern时,需要考虑的一个重要问题是缓存值的生存时间,也叫驱逐时间,通常这种模式与Cache-Aside Caching Pattern一起使用,允许给缓存值增加失效时间,以避免在数据不经常使用的情况下,缓存数据存储不堪重负。
如何在Go中实现Write-Through Caching Pattern?
这篇文章所使用的代码可以在Github上找到。
与Cache-AsideCaching Pattern的实现类似,我将使用Decorator模式,在数据存储类型中保持相同的API,但在写入过程中进行必要的调用来缓存数值。
作为一个具体的例子,在To-Do微服务中,一个新的类型Task,在 internal/memcached被添加,这个memcached.Task 类型将和memcache.Client 一起接收持久化数据存储。
1type TaskStore interface {
2 Create(ctx context.Context, description string, priority internal.Priority, dates internal.Dates) (internal.Task, error)
3 Delete(ctx context.Context, id string) error
4 Find(ctx context.Context, id string) (internal.Task, error)
5 Update(ctx context.Context, id string, description string, priority internal.Priority, dates internal.Dates, isDone bool) error
6}
7
8func NewTask(client *memcache.Client, orig TaskStore) *Task {
9 return &Task{
10 client: client,
11 orig: orig,
12 expiration: 10 * time.Minute,
13 }
14}
你会注意到memcached.TaskStore 和memcached.Task 实现了相同的方法,这是为了允许包装持久化数据存储,并允许将其作为参数在我们的 service.Task.
我们具体的Write-API实现是通过三个方法调用的,首先是Create 方法。
1func (t *Task) Create(ctx context.Context, description string, priority internal.Priority, dates internal.Dates) (internal.Task, error) {
2 task, _ := t.orig.Create(ctx, description, priority, dates) // XXX: error omitted for brevity
3
4 setTask(t.client, task.ID, &task, t.expiration) // Write-Through Caching
5
6 return task, nil
7}
第二个是Delete 方法。
1func (t *Task) Delete(ctx context.Context, id string) error {
2 _ = t.orig.Delete(ctx, id) // XXX: error omitted for brevity
3
4 deleteTask(t.client, id)
5
6 return nil
7}
而第三个是Update 方法。
1func (t *Task) Update(ctx context.Context, id string, description string, priority internal.Priority, dates internal.Dates, isDone bool) error {
2 // XXX: errors omitted for brevity
3
4 _ = t.orig.Update(ctx, id, description, priority, dates, isDone)
5
6 deleteTask(t.client, id) // Write-Through Caching
7
8 task, _ := t.orig.Find(ctx, id)
9
10 setTask(t.client, task.ID, &task, t.expiration)
11
12 return nil
13}
最后是唯一的只读方法。 Find可以通过将调用委托给持久化数据存储来实现,但在我们的案例中,我们使用了Cache-Aside缓存模式,允许在最初的只写调用中加入驱逐时间。
1func (t *Task) Find(ctx context.Context, id string) (internal.Task, error) {
2 // XXX: errors omitted for brevity
3
4 var res internal.Task
5
6 _ = getTask(t.client, id, &res)
7
8 res, _ := t.orig.Find(ctx, id) // Cache-Aside Caching
9
10 setTask(t.client, res.ID, &res, t.expiration)
11
12 return res, nil
13}
通过编写这个装饰器类型,我们可以灵活地保持我们之前实现的相同的内部Go API,唯一需要添加的变化将是在main 包中实例化服务时。
1 repo := postgresql.NewTask(conf.DB)
2 mrepo := memcached.NewTask(conf.Memcached, repo)
3
4 // ...
5
6 svc := service.NewTask(conf.Logger, mrepo, msearch, msgBroker)
结论
Write-Through 模式,类似于Cache-Aside模式,旨在通过减少返回值给客户的时间来提高我们服务的可扩展性,关键的区别在于缓存发生的时间,在只写的时候,以及这样做的原因,这将是在我们知道写可能导致立即请求只读API的情况下;例如,新闻源可以在发布后缓存一篇全新的文章,这样,那些实时消费该源的客户端将能够立即访问它,几乎没有延迟。
