

本文正在参加「金石计划 . 瓜分6万现金大奖」
关键词
- 强化学习(reinforcement learning,RL) :智能体可以在与复杂且不确定的环境进行交互时,尝试使所获得的奖励最大化的算法。
- 动作(action) : 环境接收到的智能体基于当前状态的输出。
- 状态(state) :智能体从环境中获取的状态。
- 奖励(reward) :智能体从环境中获取的反馈信号,这个信号指定了智能体在某一步采取了某个策略以后是否得到奖励,以及奖励的大小。
- 探索(exploration) :在当前的情况下,继续尝试新的动作。其有可能得到更高的奖励,也有可能一无所有。
- 开发(exploitation) :在当前的情况下,继续尝试已知的可以获得最大奖励的过程,即选择重复执行当前动作。
- 深度强化学习(deep reinforcement learning) :不需要手动设计特征,仅需要输入状态就可以让系统直接输出动作的一个端到端(end-to-end)的强化学习方法。通常使用神经网络来拟合价值函数(value function)或者策略网络(policy network)。
- 全部可观测(full observability)、完全可观测(fully observed)和部分可观测(partially observed) :当智能体的状态与环境的状态等价时,我们就称这个环境是全部可观测的;当智能体能够观察到环境的所有状态时,我们称这个环境是完全可观测的;一般智能体不能观察到环境的所有状态时,我们称这个环境是部分可观测的。
- 部分可观测马尔可夫决策过程(partially observable Markov decision process,POMDP) :即马尔可夫决策过程的泛化。部分可观测马尔可夫决策过程依然具有马尔可夫性质,但是其假设智能体无法感知环境的状态,只能知道部分观测值。
- 动作空间(action space)、离散动作空间(discrete action space)和连续动作空间(continuous action space) :在给定的环境中,有效动作的集合被称为动作空间,智能体的动作数量有限的动作空间称为离散动作空间,反之,则被称为连续动作空间。
- 基于策略的(policy-based) :智能体会制定一套动作策略,即确定在给定状态下需要采取何种动作,并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。
- 基于价值的(valued-based) :智能体不需要制定显式的策略,它维护一个价值表格或者价值函数,并通过这个价值表格或价值函数来执行使得价值最大化的动作。
- 有模型(model-based)结构:智能体通过学习状态的转移来进行决策。
- 免模型(model-free)结构:智能体没有直接估计状态的转移,也没有得到环境的具体转移变量,它通过学习价值函数或者策略网络进行决策。
习题
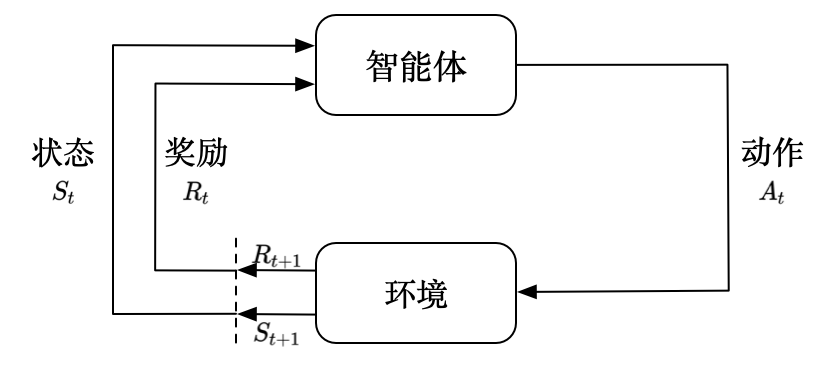
1-1 强化学习的基本结构是什么?
总的来讲是智能体通过动作,作用到环境,产生奖励并更改状态,再将状态和奖励反馈至智能体。
1-2 强化学习相对于监督学习为什么训练过程会更加困难?
主要是强化学习:一没有标注好的数据,二没有正确的标签,三智能体不能得到即时的反馈,所以很困难。
1-3 强化学习的基本特征有哪些?
- (1)强化学习会试错探索,它通过探索环境来获取对环境的理解。
- (2)强化学习智能体会从环境里面获得延迟的奖励。
- (3)在强化学习的训练过程中,时间非常重要。因为我们得到的是有时间关联的数据(sequential data), 而不是独立同分布的数据。在机器学习中,如果观测数据有非常强的关联,会使得训练非常不稳定。这也 是为什么在监督学习中,我们希望数据尽量满足独立同分布,这样就可以消除数据之间的相关性。
- (4)智能体的动作会影响它随后得到的数据,这一点是非常重要的。在训练智能体的过程中,很多时 候我们也是通过正在学习的智能体与环境交互来得到数据的。所以如果在训练过程中,智能体不能保持稳 定,就会使我们采集到的数据非常糟糕。我们通过数据来训练智能体,如果数据有问题,整个训练过程就 会失败。所以在强化学习里面一个非常重要的问题就是,怎么让智能体的动作一直稳定地提升。 1-4 近几年强化学习发展迅速的原因有哪些?
- 首先,我们有了更多的算力(computation power),有了更多的 GPU,可 以更快地做更多的试错尝试。
- 其次,通过不同尝试,智能体在环境里面获得了很多信息,然后可以在环境 里面取得很大的奖励。
- 最后,我们通过端到端训练把特征提取和价值估计或者决策一起优化,这样就可以 得到一个更强的决策网络。
1-5 状态和观测有什么关系?
- 状态是对世界的完整描述,不会隐藏世界的信息。
- 观测是对状态的部分描述,可能会遗漏一些信息。
1-6 一个强化学习智能体由什么组成?
由一个或多个如下的组成成分:
- 策略(policy) 。智能体会用策略来选取下一步的动作。
- 价值函数(value function) 。我们用价值函数来对当前状态进行评估。价值函数用于评估智能体进 入某个状态后,可以对后面的奖励带来多大的影响。价值函数值越大,说明智能体进入这个状态越有 利。
- 模型(model) 。模型表示智能体对环境的状态进行理解,它决定了环境中世界的运行方式。 下面我们深入了解这 3 个组成部分的细节。
1-7 根据强化学习智能体的不同,我们可以将其分为哪几类?
- 基于价值的智能体(value-based agent) 显式地学习价值函数,隐式地学习它的策略。策略是其从学到的价值函数里面推算出来的。
- 基于策略的智能体(policy-based agent) 直接学习策略,我们给它一个状态,它就会输出对应动作的概率。基于策略的智能体并没有学习价值函数。把基于价值的智能体和基于策略的智能体结合起来就有了
- 演员-评论员智能体(actor-critic agent) 。这一类智能体把策略和价值函数都学习了,然后通过两者的交互得到最佳的动作。
1-8 基于策略迭代和基于价值迭代的强化学习方法有什么区别?
对于一个状态转移概率已知的马尔可夫决策过程,我们可以使用动态规划算法来求解。从决策方式来看,强化学习又可以划分为基于策略的方法和基于价值的方法。决策方式是智能体在给定状态下从动作集合中选择一个动作的依据,它是静态的,不随状态变化而变化。 在基于策略的强化学习方法中,智能体会制定一套动作策略(确定在给定状态下需要采取何种动作),并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。
而在基于价值的强化学习方法中,智能体不需要制定显式的策略,它维护一个价值表格或价值函数,并通过这个价值表格或价值函数来选取价值最大的动作。基于价值迭代的方法只能应用在不连续的、离散的环境下(如围棋或某些游戏领域),对于动作集合规模庞大、动作连续的场景(如机器人控制领域),其很难学习到较好的结果(此时基于策略迭代的方法能够根据设定的策略来选择连续的动作)。 基于价值的强化学习算法有Q学习(Q-learning)、 Sarsa 等,而基于策略的强化学习算法有策略梯度(Policy Gradient,PG)算法等。
1-9 有模型学习和免模型学习有什么区别?
- 有模型强化学习是指根据环境中的经验,构建一个虚拟世界,同时在真实环境和虚拟世界中学习;
- 免模型强化学习是指不对环境进行建模,直接与真实环境进行交互来学习到最优策略。 1-10 如何通俗理解强化学习?
其实就是不断通过观察、动作进行学习,获取最大奖励的过程,这个过程叫做强化学习。
面试题
1-1 友善的面试官: 看来你对于强化学习还是有一定了解的呀,那么可以用一句话谈一下你对于强化学习的认识吗?
强化学习就如同一个婴儿,不断通过探索学习,获取生存技能的过程。
1-2 友善的面试官: 请问,你认为强化学习、监督学习和无监督学习三者有什么区别呢?
强化学习不需要标注数据,其次和无监督学习比,不能直接反馈价值。
1-3 友善的面试官: 根据你的理解,你认为强化学习的使用场景有哪些呢?
比如机器人,阿法狗,无人送货车等等。
1-4 友善的面试官: 请问强化学习中所谓的损失函数与深度学习中的损失函数有什么区别呢?
不同,这个损失函数是累计的价值传播的损耗。而深度学习的损失函数是计算真值与预测值之间的差。
1-5 友善的面试官: 你了解有模型和免模型吗?两者具体有什么区别呢?
- 有模型(model-based) 强化学习智能体通过学习状态的转移来采取动作。
- 免模型(model-free) 强化学习智能体没有去直接估计状态的转移,也没有得到环境的具体转移变量,它通过学习价值函数和策略函数进行决策。免模型强化学习智能体的模型里面没有环境转移的模型。
