

在这篇文章中,我们将学习如何在Azure Synapse Lake数据库中配置属性和关系。
简介
在我之前的文章《开始使用Azure Synapse湖泊数据库和湖泊表》中,我们学习了如何创建Azure Synapse实例并创建湖泊数据库以及其中的表。我们在Azure Data Lake Storage上创建了数据,然后在Azure Synapse Lake Database上创建了数据结构,并将这个结构配置为与数据集成,最后成功访问了这些数据。在生产场景中,通常有数百个表,可能会以特定的方式用约束和关系来建模。而且,结果可能需要以更加图形化的方式进行分析,而不仅仅是在数据网格上以表格形式表示的数据。Azure Synapse湖数据库以及表提供了一种图形化和直观的方式来配置约束、属性和表关系。
配置Azure Synapse数据库和表的属性
假设已经按照前两篇关于Azure Synapse湖泊数据库的文章,在其中创建了湖泊数据库实例和表。这是进行本练习其余步骤的绝对先决条件。在上一篇文章中,我们以创建客户表结束,该表指向Azure Data Lake Storage上托管的数据文件。假设我们打算出于任何原因克隆这个表,通常是为了创建相同表的副本或存档,其中表的模式是相同的,但数据不同。在这种情况下,我们可以点击客户表的省略号,如下图所示,我们会得到一个选项来随时克隆这个表。

现在,表已经到位,我们可以开始查看默认配置,并根据需要进行定制。点击该表,配置窗格将出现在底部,如下图所示。它有三个标签--常规、列和关系。让我们逐一看一下这三个标签。在常规属性选项卡中,我们可以找到修改表的名称、描述和浏览时列出的显示文件夹等选项。本节中的下一组属性与存储有关。我们可以通过选择题为 "从数据库默认继承"的复选框,将表配置为从Azure Synapse Lake数据库实例配置本身继承所有属性,如链接服务、输入文件夹和其他此类相关属性。

我们可以从这一部分修改与表有关的其他属性,包括链接服务、输入文件夹或文件位置以及数据格式。其他选项,如行头允许数据中的多行,数据分隔,压缩和分区,可以根据数据源中的数据类型进行配置。
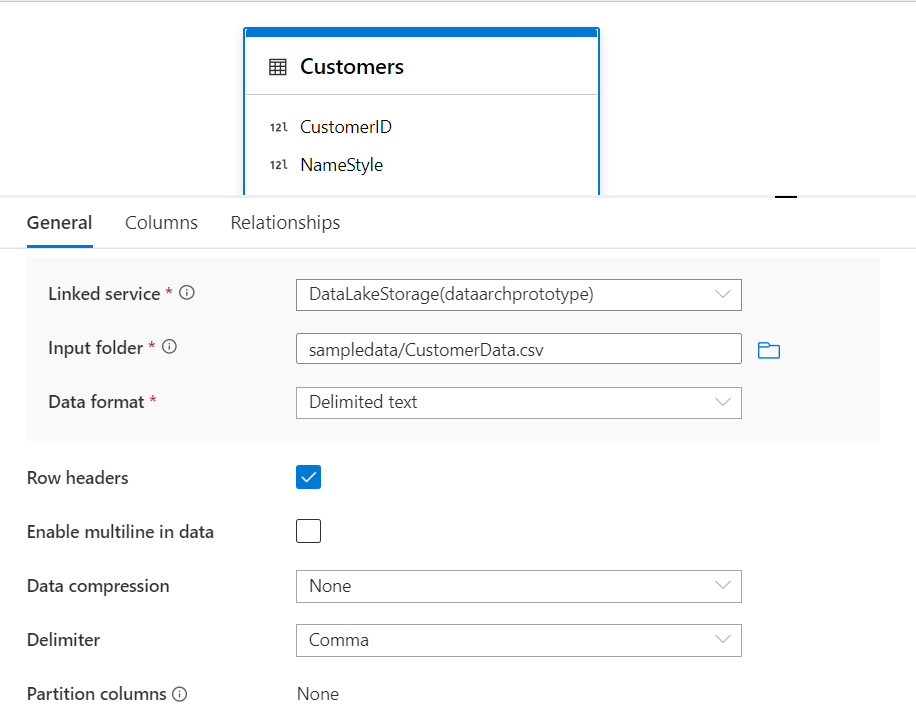
下一个选项卡是 "列"选项卡,在这里我们可以找到表格中列出的所有列。这是我们可以修改表的模式的地方。我们可以通过选择每个字段名的相关复选框来添加约束条件,如主键。我们还可以在这里修改数据类型,以及数据的长度或精度。在任何时候,我们也可以在这个标签中添加或删除字段。要保存这些变化,有必要发布这些变化,否则这些变化将被从工作区丢弃。

比方说,我们想把Customers表中的CustomerID字段作为主键,所以我们可以勾选PK复选框,不勾选Null复选框,然后发布更改。当我们选择两个或多个相同数据类型的字段时,我们可以使用Convery Type菜单选项将一个列从一种类型批量转换为另一种类型。

配置窗格中的下一个也是最后一个选项卡是关系选项卡。在这个选项卡中,我们可以选择为表定义关系。关系可以是传入的,也可以是传出的。简单地说,这意味着一个表可以有一个作为外键的键,它可能是另一个表的主键。换句话说,该表是一个子表的关系。另一种关系是,表作为主表,其主键被用作另一个表的外键。在这里,我们可以从Azure Synapse Lake数据库实例中定义的各种表中定义这两种类型的关系。要尝试配置关系功能,我们至少需要一个表。

按照我们之前注册客户表的步骤,使用Azure Data Lake Storage上托管的不同数据文件注册另一张表。在这种情况下,我创建了一个地址表,它的CustomerID与Customers表中的相同。一旦这个表被注册,它看起来如下所示。在这里,我们有意将字段名保留为C1、C2等,以模拟两个表中的字段名可能不相同的情况。

现在要为新创建的地址表定义关系,选择这个表并点击关系菜单项,如下图所示。选择 "至 "表选项,因为客户表是作为地址表的父表。一旦我们选择了这个选项,就会弹出如下所示的详细信息行。

在左侧,选择客户表,字段为客户ID,在右侧,我们将选择地址表,其相关字段为客户ID,即外键字段。

现在关系被定义了,这两个表现在是相关的。我们可以打开一个脚本窗口来探索这些相关表的数据。如下图所示,这里我们有一个SQL查询,将两个表的CustomerID字段连接起来。点击运行按钮来执行查询,结果如下图所示。
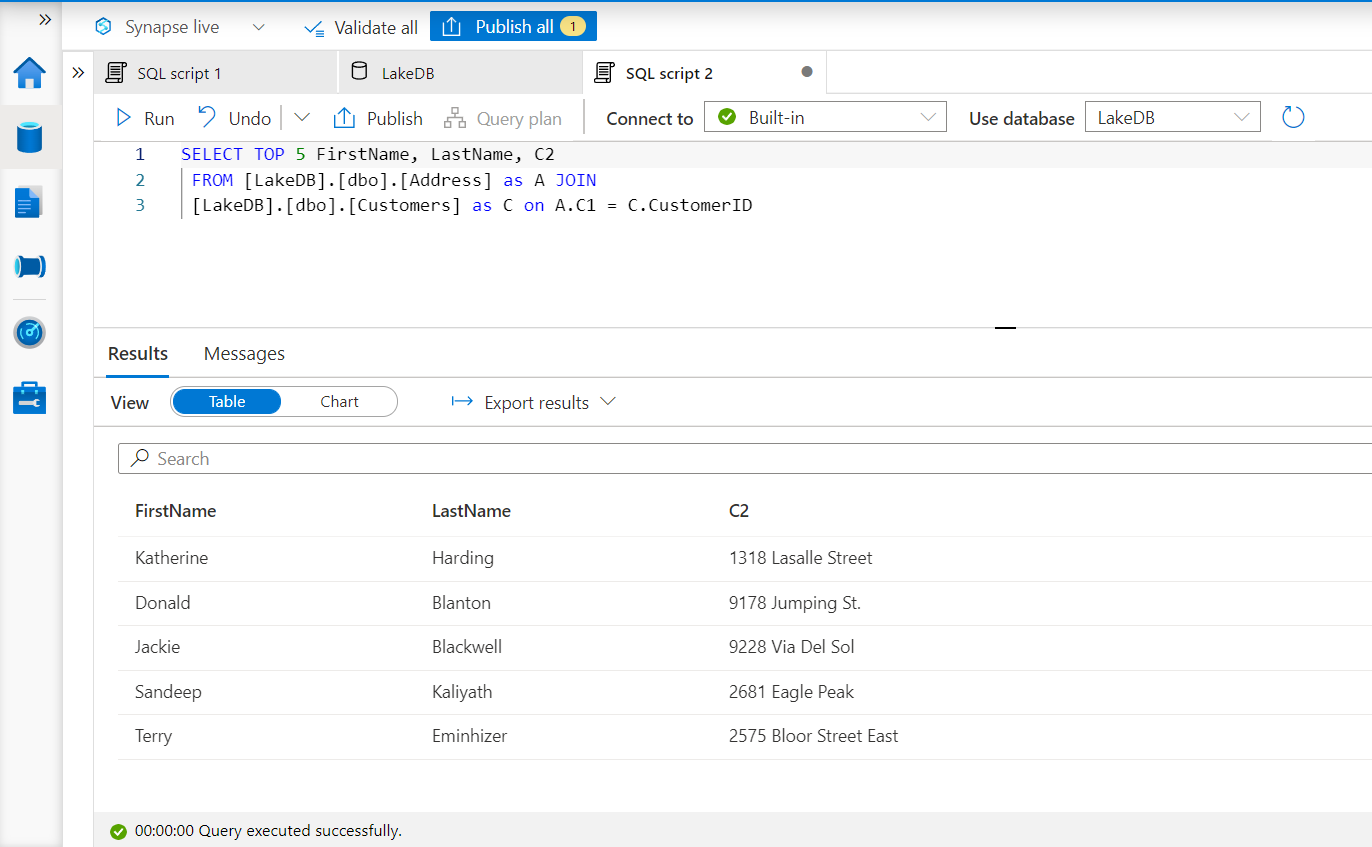
默认情况下,数据以表格的形式显示,但我们还可以对这些数据做更多的处理。有一个选项可以将这些数据以CSV和JSON等格式导出。比方说,我们打算以图形的方式来探索这些数据。我们不需要复制或导出这些数据,并将其带到不同的工具中,用这些数据创建基本图表。这个选项在相同的结果界面中是可用的。点击图表选项,我们将能够找到如下所示的图表选项。
支持多种类型的图表,根据图表的类型,配置图表的选项可能有所不同。在这种情况下,我们有一个查询,我们正在计算按标题分组的客户数量。这个数据显示了客户基于某个属性的分布,饼图是显示数据分布的最简单和广泛使用的图表之一。我们只需选择图表类型为饼图,类别为标题,图表就会如下图所示。这也可以以jpeg和png等格式导出这个图表图像。

通过这种方式,我们可以对Azure Synapse Lake数据库和表的元数据进行建模,并以直观的方式探索数据。
总结
在这篇文章中,我们学习了如何使用可视化建模器来配置与Azure Synapse Lake数据库和表有关的属性和关系,并以直观的方式从多个表中探索数据。
