

简介
在SQL Server中,有几种SQL分区。然而,一般来说,我们可以说,分区是一种将表(有时是视图)分成小块的方式,以达到性能的目的。在这篇文章中,我们将解释分区对于一个表的分区和SSAS来说意味着什么。我们还将提供一些指导,使分区过程自动化。
SQL 分区是什么意思?
让我们从表的分区开始。如果我们有一个有TB或GB信息的大表,一个搜索单行的select可能要花很长时间来执行。为了解决这个问题,一个经典的分区是将表分成小块,例如按月划分。你可以按月、日、年来划分。这取决于你的需要。
这就像一本厚厚的书。搜索单页的东西会花费太多的时间。即使有索引。然而,如果我们把书分成小书,搜索一页就会更快更容易。备份和恢复数据也会更快。
让我们从表的分区情况开始,然后再谈其他类型的分区。
SQL分区在表中是什么意思?
表的分区是指当表处理相当大的数据量时,将数据分割到多个表中以获得更好的性能。
在一个表中有2种主要的分区类型。水平分区和垂直分区。
在垂直分区中,你可以,例如,将数据分成2个表。
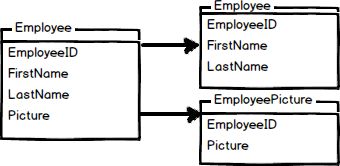
在前面的图片中,我们把Employee表分成2个表。Employee表包含名字和姓氏,另一个表是EmployeePicture。图片占用了大量的资源,所以单独处理这些数据是个好主意。将图像存储在一个独立的文件组和硬盘中是一个好的做法。
另一方面,我们有水平分区的方法
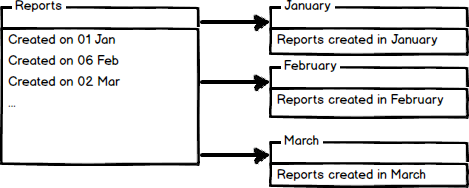
在水平分区中,我们把一个大表分成小表。上面的图片显示了一个报告在每个月的表格中的分区情况。
关于表分区的更多详细信息,以及如何一步一步地进行分区,请参考我们的相关文章。
分区对于自动化意味着什么?
我们之前解释过这个问题,并提供了一个创建水平分区的链接。我们可以使用脚本将表的分区过程自动化,并使用T-SQL查询来监控错过的分区。为了监控分区,你可以使用系统表,如以下。
- Sys.indexes
- Sys.objects
- Sys.system_internals_allocation_units
- Sys.partition_schemes
- Sys.partition_functions
- Sys.partition_range_values
下面的链接提供了一个自动维护分区的教程。
在SSAS Azure Tabular中,SQL分区是什么意思?
之前,我们谈到了在SQL Server数据库引擎中使用的表分区。我们与著名的、传统的OLTP数据库(在线交易过程)一起工作。交易型数据库是传统的数据库,在交易中插入、更新、删除数据。
SQL Server后来包括了OLAP数据库,作为一种新的数据库概念,用于处理有大量数据的报告。传统的OLTP数据库在需要几个连接和在数据库中使用几个GB时,生成报告的速度相当慢。这就是为什么微软首先从加拿大的Panorama软件公司购买了OLAP技术,创造了OLAP数据库(在线分析过程),然后微软改进了该技术。
微软创建了SSAS(SQL Server Analysis Services),这是用于创建OLAP数据库的技术。微软开始使用多维数据库。这项技术非常强大,但对于OLTP DBA或开发人员来说有点难以理解,因为它处理不同的架构、结构和组件。
为了简化创建报告的过程,微软推出了一个名为表格式模型的新功能。这是一种更容易理解和创建报告和查询的技术。要从头开始创建一个新的多维数据库,请参考以下链接。
如果你想创建一个表格数据库,请参考下面的链接。
这些技术开始时都是企业内部技术。然而,微软正在将所有的努力转移到云端。
现在,这些技术都在Azure中,那么,Tabular和多维数据库的SQL分区也在Azure中。
当你使用SSDT、创建列、DAX(数据分析表达式)查询、MDX(多维表达式)查询、XMLA(用于分析的XML)和TMLS(表格式脚本语言)时,如果模型是在企业内部或在Azure中,它是透明的。
在这篇文章中,我们将解释分区在Azure Tabular模型中的含义。然而,这个概念对于企业内部的Tabular模型是一样的。
在Tabular模型中,分区是什么意思?
我们可以说,这是一个相同的概念,即使用查询将表分成小块。 在Tabular Model中的分区是指使用查询将表的一部分分成小块。
在这个例子中,我们将展示如何做到这一点。我假设你已经安装了一个Tabular实例,并且你正在使用AdventureWorks Tabular项目(如果没有,请看实施SSAS Tabular模型的文章)。
在Adventureworks Tabular项目中,选择互联网销售表。

在菜单中,转到扩展>表>分区。
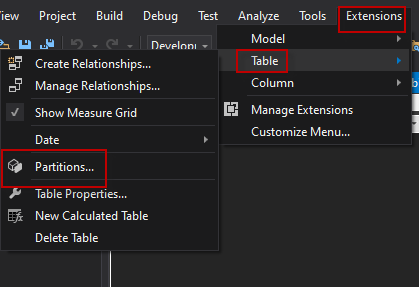
你会看到互联网销售的不同分区。本例中的分区是按年划分的。
互联网销售2010,2011,...2014。
分区之间的主要区别是在where子句中。每个分区的日期范围是不同的。例如,对于2011年的互联网销售分区,where子句是这样的。
WHERE (([OrderDate] >= N'2011-01-01 00:00:00′) AND ([OrderDate] < N'2012-01-01 00:00:00′))
另一方面,对于2012年的互联网销售是这样的。
WHERE (([OrderDate] >= N'2012-01-01 00:00:00′) AND ([OrderDate] < N'01-01 00:00:00′))

正如你所看到的,区别是非常简单的。让我们创建一个新的分区。
按新建 按钮,在分区名称文本框中写上Internet Sales 2015,在查询中,将WHERE条款修改为以下内容,然后按确定。
WHERE (([OrderDate] >= N'2015-01-01 00:00:00′) AND ([OrderDate] < N'2016-01-01 00:00:00′))

SQL分区不仅会改善适用于特定分区的查询,而且会减少处理信息的时间。如果你有一个只属于2012年分区的查询,那么这个查询将比没有分区的模型更快,因为当你有分区时,只有属于查询范围的查询被用来搜索。
在Azure Tabular模型的自动化方面,分区意味着什么?
如果你想在Azure分析服务表格模型中实现自动化分区,我们强烈建议你阅读这个链接。
结语
在这篇文章中,我们了解到SQL分区在两种不同的情况下意味着什么。在表的分区中,我们解释了什么是水平分区和垂直分区。我们需要创建文件组,添加文件并创建分区和分区方案。
另一方面,我们在SSAS中也有分区,这是一种用于报告的特殊技术。我们学习了如何使用SSAS Tabular项目在Tabular模型中创建分区。
最后我们介绍了与Azure SSAS中动态分区有关的文章。
