1.梯度法
负梯度是一个可微函数的局部最速下降方向,沿此方向可以快速找到局部极小点。
| 梯度法 |
|---|
选择 x0∈Rn.
迭代xk+1=xk−hk∇f(xk), k = 0,1,2,... |
其中hk为步长,它必须为正数。
2.步长选择策略
有如下几种策略:
1.预先选择序列{hk}k=0∞,例如
hkhk=h=k+1h
2.全松弛(精确步长)
hk=argh≥0minf(xk−h∇f(xk))
3.Amijo规则:对h>0,确定xk+1=xk−h∇f(xk),满足
α⟨∇f(xk),xk−xk+1⟩≤f(xk)−f(xk+1)(1.2.16)
β⟨∇f(xk),xk−xk+1⟩≥f(xk)−f(xk+1)(1.2.17)
其中0<α<β<1.
第一种策略是最简单的,也常用于各种教材当中。
第二种策略是理论上的,实际上无法应用,因为即便在一维的情况下也无法在有限时间内找到最小的h
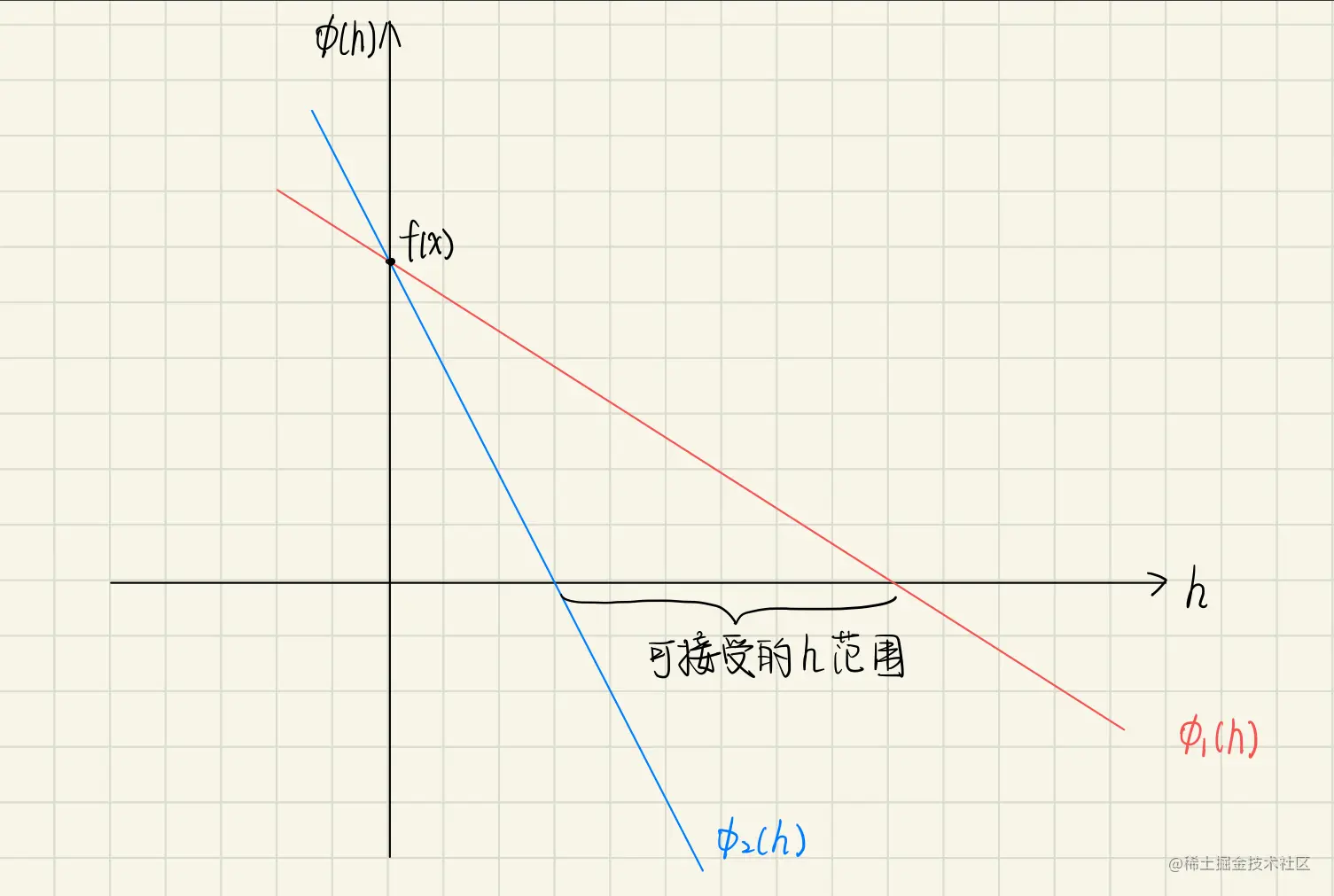
第三种策略用于很多实际的算法,从几何的角度来解释,取x∈Rn且∇f(x)=0时,考虑关于h的函数:
ϕ(h)=f(x−h∇f(x)),h≥0
于是该策略可接受的步长介于下面两个线性函数之间:
ϕ1(h)=f(x)−αh∣∣∇f(x)∣∣2ϕ2(h)=f(x)−βh∣∣∇f(x)∣∣2
这两个函数由(1.2.16)和(1.2.17)消去xk+1得到。
3.步长的最优选择
我们考虑y=x−h∇f(x),依据一些已有的结论公式,有
f(y)≤f(x)+⟨∇f(x),y−x⟩+2L∣∣y−x∣∣2=f(x)−h∣∣∇f(x)∣∣2+2h2L∣∣∇f(x)∣∣2=f(x)−h(1−2hL)∣∣∇f(x)∣∣2(1.2.19)
由此,我们希望得到一个f(y)的最优上界
对应如下的一维问题:
Δ(h)=−h(1−2hL)→hmin
利用简单的求导知识可以推知h∗=L1时取得最佳上界。
此时有
f(y)≤f(x)−2L1∣∣∇f(x)∣∣2
对于定长的策略,hk=h,接下来的分析就和上述过程一致,
最后推理得到最优的选择为hk=L1
对于全松弛策略我们有同样的结论,因为这种策略不会比定长策略差
而对于Armijo规则,依据(1.2.17)有
f(xk)−f(xk+1)≤β⟨∇f(xk),xk−xk+1⟩=βhk∣∣∇f(xk)∣∣2
同时由(1.2.19)又能得到
f(xk)−f(xk+1)≥hk(1−2hkL)∣∣∇f(xk)∣∣2
结合上述两式,可以得到hk≥L2(1−β)
同理利用(1.2.16)能够得到
f(xk)−f(xk+1)≥α⟨∇f(xk),xk−xk+1⟩=αhk∣∣∇f(xk)∣∣2
继续与hk≥L2(1−β)相结合,可以得到
f(xk)−f(xk+1)≥L2α(1−β)∣∣∇f(xk)∣∣2
综合上述三种策略对应的结论,我们可以一般化地描述一个统一的结论
f(xk)−f(xk+1)≥Lw∣∣∇f(xk)∣∣2(1.2.20)
其中w是一个正常数
4.性能评估
我们将(1.2.20)式对k=0,1,⋯,N进行累加,可以得到
Lwk=0∑N∣∣∇f(xk)∣∣2≤f(x0)−f(xN+1)≤f(x0)−f∗(1.2.21)
其中f∗是函数局部最小值
由上述式子可以得知左式是有界的,那么
∣∣∇f(xk)∣∣→0当k→∞时
我们先做出如下定义
gN∗=0≤k≤Nmin∣∣∇f(xk)∣∣
其含义就是所有不同k中最小的梯度
结合(1.2.21)可以得到
gN∗≤N+11[w1L(f(x0)−f∗)]21(1.2.22)
该式子可以描述∣∣∇f(xk)∣∣收敛的速率。
5.举个例子
考虑两个变量的函数
f(x)=f(x1,x2)=21x12+41x24−21x22
求出该函数的梯度为∇f(x)=(x1,x23−x2)T。
于是可见有三个点满足梯度为0
x1∗=(0,0),x2∗=(0,−1),x3∗=(0,1)
这三个点可能是函数的局部极小值。接着计算Hessian矩阵
Hessian矩阵
H=⎣⎡∂x12∂2F∂x2∂x1∂2F⋮∂xn∂x1∂2F∂x1∂x2∂F∂x22∂F⋮∂xn∂x2∂F⋯⋯⋱⋯∂x1∂xn∂F∂x2∂xn∂F⋮∂xn2∂F⎦⎤
用于判定极值点
当Hessian矩阵正定时,任意向量v有vTHv>0,为极小值点
当Hessian矩阵负定时,任意向量v有vTHv<0,为极大值点
当Hessian矩阵同时具有正负特征值时,该点为鞍点。
于是此处的Hessian矩阵为
∇2f(x)=[1003x22−1]
于是点x2∗,x3∗代入矩阵为正定的,是局部最小值,而x1∗则为鞍点。
接下来考虑从(1,0)出发的梯度算法路径,会发现无论怎么走第二个坐标恒为0,最终将会收敛到x1∗,由此可见,缺乏约束的情况下,梯度法只能靠近一个稳定点。
参考资料
[1] Lectures on Convex Optimization(Second Edition)
[2] Hessian矩阵


