

今天,我想向大家介绍一下我在莫斯科国立大学物理系实验室的工作,我在那里攻读硕士学位。
我们实验室的主要活动之一是研究如何让激光束穿过大气层。我们如何利用它来传输数据?它将如何被空气的波动所改变?
对于数据传输,我们使用一个狭窄的射线("数据束")。我们还定期发送一个探测性的、宽口径的光束,通过其内部结构的变化(这确实很复杂),我们可以识别沿途的大气状态。利用这些信息,我们能够预测 "数据束 "的扭曲,并通过调整它来补偿它们。
这一切的主要目标是提高通过光束传输数据的可能速度,现在的速度真的很低。
就我个人而言,我开发的软件用于处理来自视频摄像机的信号。这个信号是由一束宽口径的激光产生的,在到达摄像机镜头之前,要经过一个很长的大气路径。
该软件的任务是确定传入光束的特性(图像的时刻,直到第4个),以及这些数量的时间-频率特性。为了更准确地确定频率分量,我们使用二次时频分布(QTFD),如Wigner-Ville分布。
其中一个重要的问题是,处理信号的时间是有限的。同时,二次时频变换是非局部的,这意味着要处理信号的某一时期,必须完全获得这一时期的所有样本,这使得实时处理不可能。
在这种情况下,有必要争取在积累下一个测量周期的样本时有时间来处理信号,这意味着处理时间不应长于测量的持续时间(姑且称之为 "准实时 "任务)。同时,这个任务很容易被分离成许多线程。
为什么是Haskell?
除了在一定程度上将运行时的错误数量降到最低的类型安全之外,Haskell使计算的并行化变得简单而快速。此外,还有一个名为Accelerate 的Haskell库,可以轻松方便地使用GPU的资源。
对于延迟敏感的任务,Haskell的一个重要缺点是垃圾收集器,它周期性地完全停止程序。有一些工具可以最大限度地减少与之相关的延迟,特别是--使用 "紧凑区域",这就部分地抵消了这一缺点。有了它,你可以向垃圾收集器指定,当某组数据中至少有一个元素被使用时,不应该被删除。这使你能够大大减少垃圾收集器检查数据集的时间。
此外,语言的懒惰性被证明是有利的。这可能看起来很奇怪:懒惰通常会引起批评,因为它产生了一些问题(由于未计算的thunks而导致的内存泄漏),但在这种情况下,由于有可能将算法的描述和它的执行分开,所以它是有益的。这有助于缓解任务的并行化,因为通常情况下几乎不需要对已经准备好的算法做任何修改,因为在描述了计算之后,我们并没有规定应该如何或何时执行。在命令式语言的情况下,调度计算完全落在程序员的肩上--他们决定什么时候和什么动作将被执行。在Haskell中,这是由运行时系统完成的,但我们可以很容易地指定应该做什么和如何做。
第一个任务:从激光束的视频记录中获得图像的时刻
在这个任务中,ffmpeg-light 和JuicyPixels 库被用来进行数据处理。
这项任务可以分解成几个步骤:获得图像、确定图像的矩值、以及获得整个视频文件中这些矩值的统计数据:
data Moment =
ZeroM { m00 :: {-# UNPACK #-}!Int }
| FirstM { m10 :: {-# UNPACK #-}!Int, m01 :: {-# UNPACK #-}!Int }
| SecondM { m20 :: {-# UNPACK #-}!Double, m02 :: {-# UNPACK #-}!Double
, m11 :: {-# UNPACK #-}!Double }
| ThirdM { m30 :: {-# UNPACK #-}!Double, m21 :: {-# UNPACK #-}!Double
, m12 :: {-# UNPACK #-}!Double, m03 :: {-# UNPACK #-}!Double }
| FourthM { m40 :: {-# UNPACK #-}!Double, m31 :: {-# UNPACK #-}!Double
, m22 :: {-# UNPACK #-}!Double, m13 :: {-# UNPACK #-}!Double
, m04 :: {-# UNPACK #-}!Double }
视频图像被转换为一个Image Pixel8 类型的图像列表,使用适当的函数进行折叠。平行处理的方法如下。
processFrames :: PixelF -> PixelF -> [Image Pixel8] -> V.Vector TempData
processFrames cutoff factor imgs =
foldl' (\acc frameData -> (acc V.++ frameData)) (V.empty) tempdata
where tempdata = P.parMap P.rdeepseq (processFrame cutoff factor) imgs
这个函数需要2个辅助参数(背景值和缩放系数),一个图像列表,并返回一个类型为TempData 的值向量(它存储了时刻和其他一些值,以后将进行统计分析)。
每个图像的处理都是并行进行的,使用parMap函数。这些任务是资源密集型的,所以创建独立线程的成本是有回报的。
来自另一个程序的例子:
sumsFrames :: (V.Vector (Image Pixel8), Params) -> V.Vector (V.Vector Double, V.Vector Double)
sumsFrames (imgs, params) =
(V.map (sumsFrame params) imgs) `VS.using` (VS.parVector 4)
在这种情况下,使用using 函数开始计算的结果:
using :: a -> Strategy a -> a
它使用适当的策略开始计算一个给定的a ,在这种情况下--每个线程4个元素,因为计算一个元素太快了,为每个元素创建一个单独的线程会造成很高的开销。
从前面的例子可以看出,并行执行几乎不改变代码本身:在第二个例子中,你可以只删除VS.using (VS.parVector 4) ,最终结果根本不会改变,计算只是需要更长的时间。
第二项任务:对获得的数值进行时间-频率分析
在处理了激光束振荡的视频记录后,我们得到了一组数值,对于其中一些数值,有必要建立一个时间频率分布。一种常见的方法是构建频谱图,但它的分辨率相对较低--我们在频率上做得越高,在时间上就越差,反之亦然。你可以通过使用科恩类变换来解决这个限制。
\C_x(t, \omega;f) = \iiint_{-\infty} e^{-i\phi(s-t)} f(\phi,\tau) x(s+\tau/2)x^{*}(s-tau/2) e^{-i\omega\tau}d{\phi}dsd{\tau}] 。
这里x (t)是初始信号,f (φ, τ)是参数化函数,通过它来指定具体的变换。最简单的例子是Wigner-Ville变换。
\WV (t, \omega) = 2 \int_{-\infty}^{infty}x(t+n)x^{*}(t-n)e^{-2i{omega}n}dn\] 。
下面给出了频谱图和Wigner-Ville分布的比较。
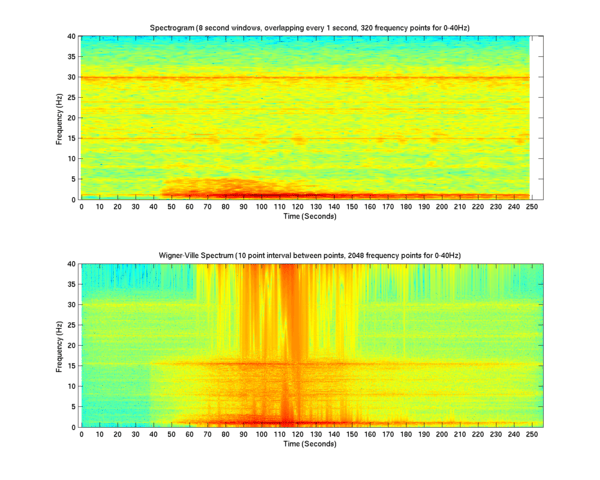
第二张图更详细(特别是在低频区域),但其中有干扰成分。为了对付它们,使用了各种抗混叠方法或Cohen类的其他变换。计算分几个阶段进行。
- 进行希尔伯特变换(我们得到一个分析信号)
- 构建矩阵A = x (t + n)* x (t-n)
- 对矩阵的每一列应用一维傅里叶变换
.JPG)
这里可以找到一个计算Cohen类(Choi-Williams)更复杂变换的算法例子。
为了计算这些转换,我们使用了 Accelerate库被使用。这个库使得在用户的要求下同时使用中央处理器(有效分配核心上的负载)和图形处理器成为可能(甚至无需重建程序)。
该库使用自己的DSL,在运行时被编译成LLVM代码,然后可以被编译成CPU的代码和GPU的代码(CUDA)。为图形处理器形成的计算核心被有效地缓存起来,防止在运行时不必要地重新编译。因此,当人们执行大量相同的任务时,运行时的代码编译只发生一次。
Accelerate 的DSL类似于REPA (常规并行数组库)的DSL,而且相当直观,Acc a 类型的值实际上是在编译时生成的代码(这就是为什么当试图向GHCi输出一个类型的值时,例如Acc (Array DIM1 Int) ,它将输出的不是一个整数数组,而是一些计算的代码)。这段代码是由单独的函数编译和运行的,例如。
run :: Arrays a => Acc a -> a
或
runN :: Afunction f => f -> AfunctionR f
这些函数在编译代码(用acelerate的DSL编写)时应用了各种优化,如 fusion.
此外,最新版本还具有在Haskell编译时运行表达式编译的能力(使用runQ函数)。
Wigner-Willy变换计算函数的例子:
...
import Data.Array.Accelerate as A
import qualified Data.Array.Accelerate.Math.FFT as AMF
...
-- | Wigner-ville distribution.
-- It takes 1D array of complex floating numbers and returns 2D array of real numbers.
-- Columns of result array represents time and rows — frequency. Frequency range is from 0 to n/4,
-- where n is a sampling frequency.
wignerVille
:: (A.RealFloat e, A.IsFloating e, A.FromIntegral Int e, Elt e, Elt (ADC.Complex e), AMF.Numeric e)
=> Acc (Array DIM1 (ADC.Complex e)) -- ^ Data array
-> Acc (Array DIM2 e)
wignerVille arr =
let times = A.enumFromN (A.index1 leng) 0 :: Acc (Array DIM1 Int)
leng = A.length arr
taumx = taumaxs times
lims = limits taumx
in A.map ADC.real $ A.transpose $ AMF.fft AMF.Forward $ createMatrix arr taumx lims
因此,我们能够使用GPU的资源,而不需要对CUDA进行详细的研究,并且我们获得了类型安全,帮助我们切断了大量的潜在错误。
之后,得到的矩阵被从视频存储器中加载到RAM中进行进一步处理。
在这种情况下,即使是在一个相对较弱的显卡(NVidia GT-510)上,在被动冷却的情况下,计算也比在CPU上快1.5-2倍。在我们的案例中,10,000个点的威格纳-威利转换发生的速度比30秒还要快,这完全符合准实时的概念(在更强大的GPU上这个数值可以小得多)。 基于这些信息,原始激光束将被修正,以补偿大气脉动。
此外,这种时频分布的结果会以文本形式永久保存在磁盘上,以便日后分析。在这里,我面临着这样一个事实:双转换库将数字直接转换为Text或Bytestring,这在巨大的数据集(1000万个值或更多)的情况下会产生很大的负荷,所以我写了一个补丁,增加了对Builder值的转换(对Bytestring和Text),这使存储文本数据的速度加快了10倍。
在有大量小块数据的情况下,如果有可能的话,它们会被移到紧凑区域。这增加了内存消耗,但大大减少了与垃圾收集器的操作相关的延迟。此外,垃圾收集器通常在一个单线程中启动,因为并行的垃圾收集器经常会引入大的延迟。
结论
准确的时频分析方法在很多领域都非常有用,比如医学(脑电图分析)、地质学(非线性时频分析被长期使用)、声学信号处理。我甚至发现了一篇关于使用二次时频分布来分析发动机振动的文章(而且真的很有用)。
时频分布的问题目前还没有得到解决,所有的方法都有各自的优点和缺点。带滑动窗口的傅里叶变换(STFT)可以显示真实的振幅,但分辨率很低,维格纳-维尔分布具有很好的分辨率,但它只显示准振幅值,可以显示哪里的振幅较高,哪里的振幅较低,并且有高水平的干扰交叉项。许多QTFD既要对抗干扰,又要不失去分辨率(这是一个困难的任务)。
关于Accelerate 库,我可以说在开始时很难避免嵌套并行,这是不允许的(不幸的是在编译时没有被检测到)。
我把这个软件的第一个版本作为 window-ville-accelerate包。现在我已经添加了Choi-Williams和Born-Jordan分布。在未来,我想添加更多的分布,并将其作为qtfd-accelerate 包发布。
