

检测遗传性疾病的未来
对与遗传性疾病相关的疾病进行早期检测是现代医学最关注的问题之一。最近的研究指出,在早期阶段被诊断为肺癌的人有57%的机会在未来5年内存活,而被诊断为IV期癌症的病人的存活率为3%。对人类的另一个祸害--阿尔茨海默病的早期检测,使患者能够改变他们的生活方式,参与临床试验,并提前治疗大脑退化的症状,有效延长他们的生命。虽然基因检测只有助于评估晚期阿尔茨海默病的可能性,但对早发性阿尔茨海默病的出现有很好的指示作用,因为它是由三个不同的基因突变引起的(最近关于早发性阿尔茨海默病的DNA检测研究)。
有各种完全基于生物研究的疾病检测技术,尽管它们对于调查特定的病例可以非常精确,但通常它们缺乏一个非常关键的东西--它们需要对疑似疾病的患者进行额外的复杂的医学测试。这种测试的成本太高,无法在健康人身上定期进行。例如,任何人都可以偶尔进行一次常规血液检查,但几乎没有人愿意为了预防癌症而接受全身核磁共振检查,更不用说像活检这样的侵入性检查了。
因此,非常有必要开发易于执行的测试,以准确检测此类疾病。就目前而言,这一领域最有希望的方向是通过遗传学,尽管在我们到达目的地之前还有许多任务需要解决。而机器学习已经提出了很多工具来帮助完成这些任务。在这篇文章中,我想介绍一些遗传学数据的ML应用,以及理解它们的必要信息。值得注意的是,这个数据科学领域正在以令人难以置信的速度发展,所以请把这篇文章当作一个起点或灵感的来源,而不是一个全面的回顾或教程。
为了更好地理解以下材料,我建议你阅读Rachel Lea Ballantyne Draelos的这篇文章,其中包含了从微生物学角度以简单和优雅的方式介绍的所有基础知识。另外,为了使文章相当简洁,我将省略一些基本的机器学习算法如何工作的细节,而专注于特定的模型和应用。
遗传学的基础知识
人类对遗传学的研究始于1866年,当时格雷戈尔-孟德尔,也被称为 "遗传学之父",提出特征是代代相传的。在过去的155年里,我们在理解基因组的性质方面取得了长足的进步,甚至可以破译和修改它。要涵盖这段旅程的所有细节,需要几十卷的百科全书,但我只想用一段话就能搞定。
遗传信息构成了任何生物体内的所有过程,并储存在生物体的DNA中。而DNA是由4种核苷酸(T、A、C、G)组成的两个 "相反 "的字符串,长度约为30亿。几乎所有生物体的细胞都含有DNA。DNA被转录成RNA,其中也包含4种核苷酸(A、U、C、G)。RNA的每个核苷酸三联体,称为 "密码子",编码20个氨基酸中的一个,有几个例外用于编码序列的 "开始 "和 "停止"。蛋白质由氨基酸构成,是所有生物的最终构成部分。
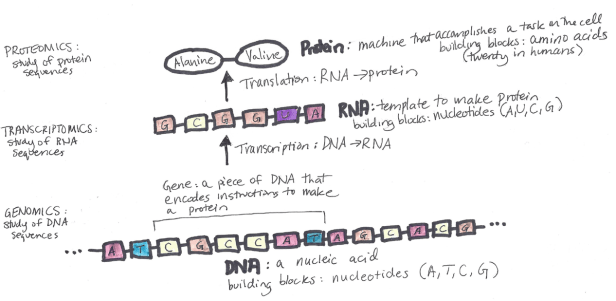
遗传流程,来自Rachel Lea Ballantyne Draelos的一篇文章。
请注意,上面的方案是非常简化的,有许多不同的陷阱,因为不是所有的RNA序列都能翻译成蛋白质,而且在构建蛋白质时也不是RNA的所有部分都被使用。事实上,只有大约3%的RNA序列被翻译成蛋白质,其他97%被称为非编码RNA(ncRNA)。ncRNA有时被称为基因组的 "暗物质",因为我们对其特性知之甚少。还有其他多种类型的RNA,如mRNA、tRNA、rRNA,它们在构建蛋白质的过程中都有各自的作用。分子生物学的中心教条中描述了生物系统内遗传信息的整个流程,但现代研究表明,即使是一些教条的陈述也不完全准确。
遗传变异
这里有一个问题要问你:为什么人与人之间会有如此大的差异?有些人非常高大,有些人可以不知疲倦地跑上几英里,有些人有蓝眼睛或卷发,有些人对艾滋病毒有免疫力。自从地球上出现第一批人的那一刻起,随着人口的增长和时间的推移,物种特征的种类不断扩大。为什么?
遗传学对这个问题有一个答案。正如我们所知,DNA对我们身体的一切负责。这使我们得出一个重要的见解--每个人都有一个独特的基因组。甚至更进一步,同一生物体内的细胞可以有不同的DNA(例如,一种被称为线粒体异质的现象)。当然,密切相关的物种的基因组的差异往往比不同物种之间的差异要小。请注意,即使是相同的DNA序列也可以有不同的 "解释"。这样一个过程被称为表观遗传学的科学领域所描述,我将在文章后面简要介绍。
同一物种内基因组的差异是由DNA突变造成的。事实上,我们出生时都有DNA突变,从我们的父母那里继承而来(所谓的 "种系突变")。然而,你甚至可以在你的一生中获得DNA突变。通常情况下,它的发生是因为DNA复制过程中的错误,但有时突变是由外部因素引起的,如紫外线辐射、化学品或病毒。
大多数突变是无声的,不会明确地影响你,有些甚至是有益的,但也有少数突变会导致严重的健康问题。后者虽然相当罕见,但却是我们听到最多的:遗传病、癌症等。
基本突变之一被称为单核苷酸多态性或SNP,它是个体间DNA变异的最简单形式。SNP是一个单核苷酸对另一个单核苷酸的替换。据估计,SNP在整个基因组中的出现频率为1/1000 bp,其中 "bp "是经常使用的 "碱基对 "的缩写,它是一对通过氢连接的双链核碱基。尽管单个SNP很少导致疾病,但特定基因中的SNP组合可能导致各种疾病,你可以在本文的表1中查看其中一些。
描述和编排不同SNP的崇高任务多年来一直处于解决过程中。互联网上有几个公开的SNP数据库,如OMIM、ClinVar、DisGeNET和NCBI。
检测遗传性疾病
有人会问:检测与基因有关的疾病有什么难的?只要把一个人的整个基因组,寻找与疾病相关的所需模式,做出结论。完成了,这是你的处方,吃药吧,很快就会好起来。
好吧,正如你可能已经猜到的,这不是那么简单......首先,让我们考虑到一个事实,即基因组由大约30亿个核苷酸按特定顺序组成。获得这串DNA的过程被称为**DNA测序。**这是一项非常广泛和具有挑战性的任务,由于不在文章的范围内,我就不做过多的介绍。我想说的是,目前最经常应用的技术被称为 "下一代测序 "或NGS。它们读取DNA串的小部分,并通过后处理算法根据其重叠区域将其组合在一起。为了使NGS尽可能的准确和精确,已经投入了大量的努力,尽管有一些问题是由分析材料的异质性引起的。为了解决这个问题,人们发明了 "第三代 "DNA测序方法。这种方法依赖于单分子测序,是目前该领域最有前途的方法。关于DNA测序的更多信息,我建议你查看这篇论文。
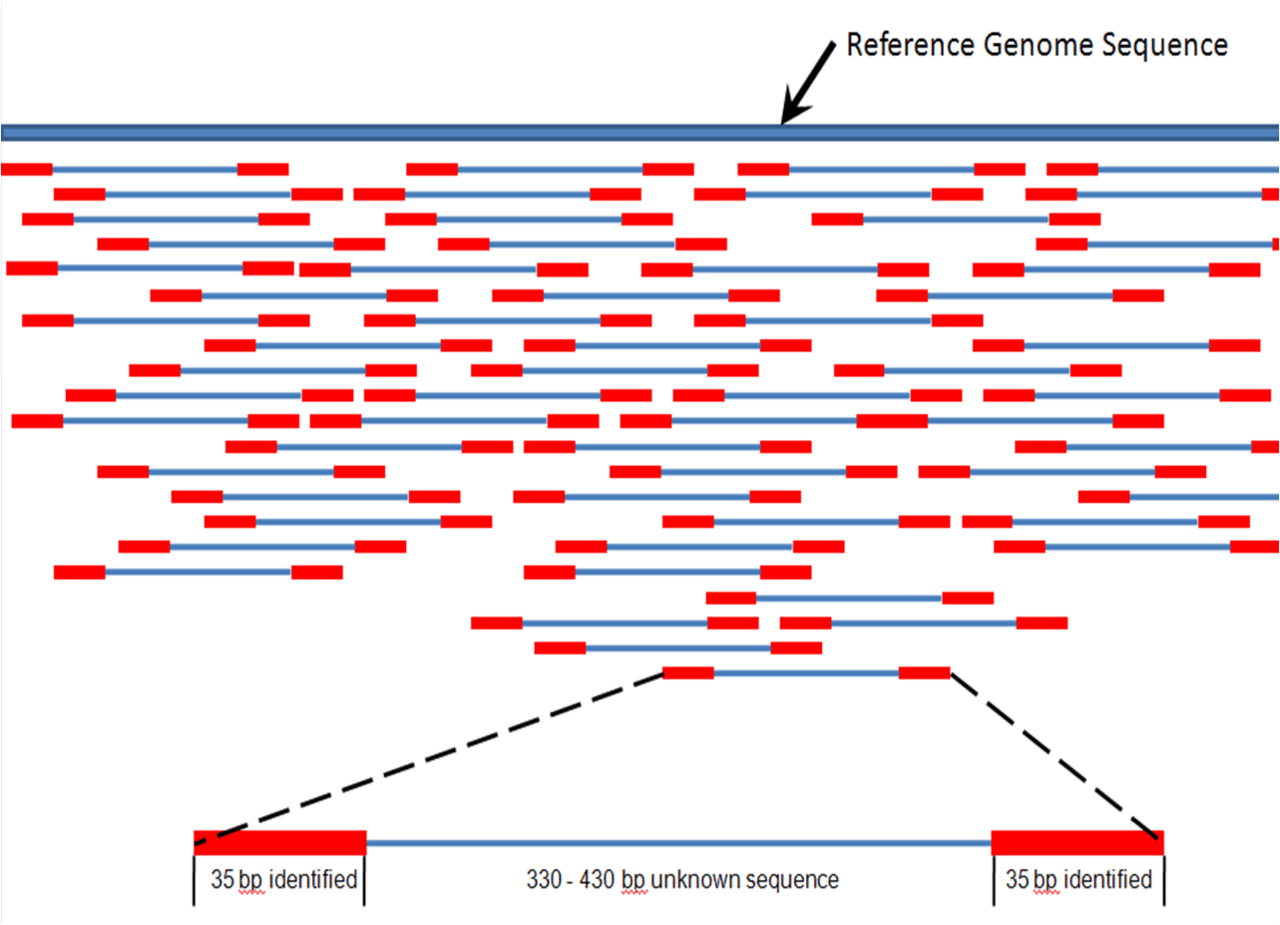
一个简化的NGS的例子。来源。维基百科
即使你已经获得了准确的DNA字符串或多个字符串,检测疾病的真正挑战才刚刚开始。正如我上面提到的,基因突变或突变组合是导致多种疾病的原因。其中一个问题是,有些疾病(如癌症)是由许多不同的、有时是罕见/未知的突变引起的,在DNA检测过程中几乎不可能人工寻找所有的突变。这就是为什么通常只建议有某些类型癌症的强烈家族史的人或已经被诊断为癌症的人进行癌症的DNA测试,以检查它是否由遗传基因突变引起,以便提醒其他家庭成员。另一个问题是,导致疾病的一些基因突变发生在特定的细胞或组织中,因此,即使是一个基因材料样本也很少足以准确检测出疾病。
由于这些原因,寻找突变的遗传物质并不总是检测疾病的最佳方法。例如,有一种肿瘤蛋白p53负责基因突变的抑制。它的相关基因TP53被归类为肿瘤抑制基因。p53的功能是修复受损的DNA,阻止细胞生长,并在一切完全出错时启动细胞解体。因此,基本上,p53负责生物体的稳定和可持续生长和更新。然而,突变的TP53可以停止产生p53,这往往导致可怕的后果,如癌症。在所有人类恶性肿瘤中,50%以上都发现了突变的TP53。可悲的是,突变的TP53大多可以在癌变组织中发现,不能成为癌症的有效指标。
因此,寻找疾病的过程被缩小到寻找准确的疾病指标并对其进行正确分类。这种指标被称为生物标志物,是某种生物状态或条件的可测量指标。医学生物标志物分为3种类型:分子生物标志物(如DNA、RNA、蛋白质水平)、细胞生物标志物(如组织病理学)或成像生物标志物(如CT、MRI、X射线等)。在诊断癌症时,生物标志物可以是血液或组织中存在的可追踪的物质,如由肿瘤细胞或身体其他细胞产生的对肿瘤有反应的生物分子。阿尔茨海默症最有希望的分子生物标志物是脑脊液中的淀粉样β(Aβ42)、总tau(T-tau)和磷酸化tau(P-tau)。对于类风湿性关节炎,类风湿因子(RF)和抗环瓜氨酸肽(抗CCP)被认为是很好的指标。请注意,在临床实践中使用的生物标志物必须满足某些严格的标准,如特异性和敏感性至少为0.9,但不同疾病的标准也不同。
遗传学中的人工智能
幸运的是,现有的遗传相关疾病的诊断系统正在迅速变化。由于计算科学、微生物学和实验室硬件的进步,在不同层面上搜索疾病生物标志物的过程已经变得更便宜、更快、更有效。这反过来又导致了更大的标记医学图像和研究的数据库。当然,这样的数据库也是数据科学家的完美研究场所。多所科技大学、大公司和人工智能初创公司正在与医疗机构合作,以便利用机器学习算法,特别是深度学习,开发新的疾病检测方法。
深度学习是一个被称为人工神经网络(ANN)的高级抽象算法系列,能够识别数据中的多种结构和模式,经常是人类无法检测到的。虽然深度神经网络的概念发生在20世纪中期,但到了21世纪,由于并行计算和GPU加速方面的进展,它才得到普遍的普及。迄今为止,深度学习有成千上万的应用,其中最引人注目的是在自然语言处理和计算机视觉等领域,人工神经网络在多项任务中达到了超越人类的感知水平。在这里,我想展示一下最近ANN在遗传学上的一些应用实例,以及潜在的进一步研究。
组织病理学
尽管传统的ML已经在微生物学中得到了相当广泛的应用,但深度学习在最近获得了相当大的发展势头。卷积神经网络(CNN)是深度学习最发达的领域之一,在分析组织病理学图像的任务中显示了巨大的成果。
美国国家癌症研究所将组织病理学定义为 "使用显微镜对病变细胞和组织的研究"。基本上,组织病理学幻灯片是来自受疾病影响的器官组织的高分辨率显微镜图像。CNN已经被用来对图像进行总体分类(例如,是否存在癌症),检测受影响的细胞或区域,对多种癌症类型进行分类,甚至测量基因表达。在某些情况下,预测的质量与病理学家的预测相似,甚至超过了病理学家,但这种检测方法有几个缺点。最主要的是,为了获得检查材料,病人应该接受痛苦的外科手术--活检,因此它不能用于健康人。另外,训练CNN进行物体检测和分类需要大量的标记训练样本。在组织病理学分析的情况下,图像应该由有经验的病理学家进行标注,并且诊断应该得到历史的证明。人们可以从互联网上下载一些开源数据集,但样本量通常不大,而且稀有癌症类型的案例也不够多。
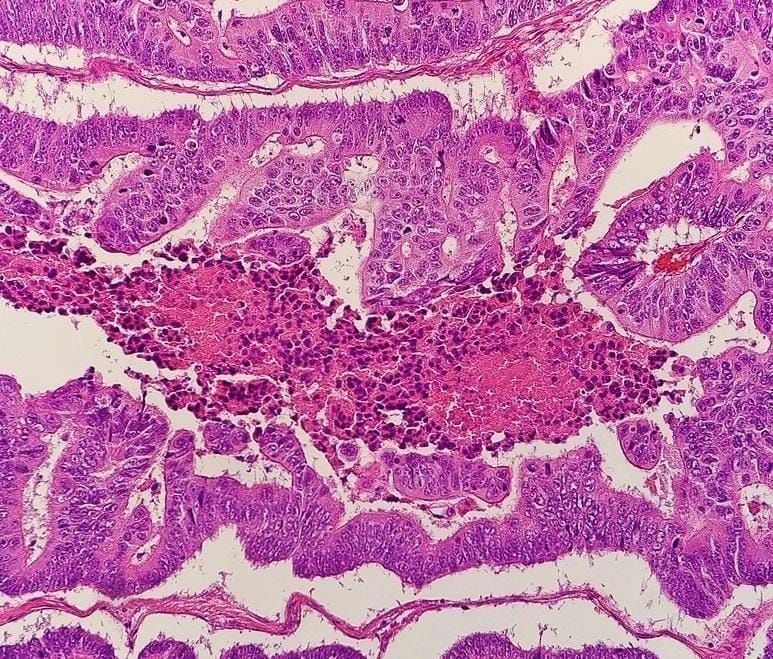
组织病理学图像显示结直肠腺癌。来源。维基百科
DNA变体
对基因变异和突变的理解可能是开发更好的医疗测试的关键,而人工智能已经为该领域做出了重大贡献。其中一个值得注意的例子是谷歌的DeepVariant,这是一个基于深度学习的开源变体调用器。DeepVariant中的CNN将测序读数作为输入,能够准确地重建基因组,同时调用所有变体和测序错误。凭借DeepVariant的前身模型,谷歌大脑团队在2016年赢得了SNP性能精度FDA真理挑战赛,后来又开发了DeepTrio,这是DeepVariant的一个扩展,可以更好地解决子/父基因组的遗传特性。
ncRNA
目前的证据表明,非编码RNA在肿瘤发生、阿尔茨海默病和心血管疾病中起着很大的作用,有可能成为一个伟大的生物标志物或治疗目标。具体来说,ncRNAs可以通过各种不同的机制影响癌细胞的命运和生存,包括转录和转录后修饰、染色质重塑和信号转导。简而言之,ncRNAs创造了一个复杂的相互作用网络,并作为致癌物或肿瘤抑制物发挥作用。揭示ncRNA及其亚型的特性是基因组学中最热门的话题之一,尤其是它与疾病的联系,但即使是将ncRNA与编码RNA部分以及彼此区分开来也确实是一项艰巨的任务。ncRNA的形式、长度和特性各不相同,有许多为ncRNA分类量身定做的伟大项目,使用了深度学习,但它们只涵盖整个挑战中较小的一部分。要充分了解ncRNA并在临床实践中加以利用,未来还需要大量的工作,但我们正走在正确的道路上!。关于ncRNA及其用ML分类的更多细节,我建议你阅读这篇伟大的论文,它涵盖了过去几年中最成功的方法。
循环DNA和RNA
为了开发高度准确的血液测试(也被称为 "液体活检"),人们将需要一个准确的血源性疾病生物标志物。其中最有希望的是循环游离DNA(cfDNA)和循环RNA(cfRNA)。cfDNA和循环RNA分别是DNA和RNA的细胞外片段,可以在血液、尿液、滑液或唾液中发现。一些健康的细胞也会释放遗传物质,但cfDNA/cfRNA的水平升高通常是不同疾病的指标。虽然cfRNA的功能探索较少,但在阿尔茨海默氏症、癌症和帕金森氏症检测领域,有一些正在进行的伟大的生物学研究,使用循环非编码RNA作为生物标志物。我想提到这个领域,因为它为人工智能的应用提供了巨大的机会,尽管到目前为止只有很少的存在(这里有一个例子,基于循环的miRNA,测试多种机器学习算法来检测阿尔茨海默氏症)。与诊断癌症有关的cfDNA类型是循环肿瘤DNA(ctDNA)。ctDNA直接来源于肿瘤或循环肿瘤细胞,因此它不仅可以用于检测癌症,还可以用于分析整个肿瘤基因组,因为ctDNA携带其部分。迄今为止,最大的挑战是血浆中目标DNA的浓度可能相当低,因此需要适当的检测和测序方法来准确评估ctDNA的存在。ANNs被成功地用于帮助检测ctDNA,例如,本文提出了一个高度准确的CNN,它根据从液体活检中收集的遗传物质检测与肺癌有关的cfDNA的突变。
cfDNA还有更多的用途,用于不同的目的。如果你对cfDNA的已知特性感兴趣,我建议你查看这个来源以获得更多的见解。另外,这里有一个可用的cfDNA数据集的列表,供你实验使用。
.png)
cfDNA和ctDNA。资源。ResearchGate
DNA甲基化
表观遗传学是编码到基因组上的第二层信息,指导基因组的功能和活动。表观遗传学通过两种机制发挥作用:改变基因组三维构象和/或蛋白质-DNA相互作用的染色体蛋白质的修饰以及DNA链本身的化学修饰。最具特色的DNA化学修饰是将胞嘧啶甲基化为5-甲基胞嘧啶(5mC),几乎只发生在由DNA磷酸盐骨架与鸟苷连接的胞嘧啶碱基上,称为CpG位点。局部和整体的高甲基化与癌症组织的过程紧密相连,甚至在疾病的早期阶段就可以观察到,因此它们是疾病预测的ML模型的一个非常有用的输入。计算DNA甲基化通常与ctDNA测试密切相关。虽然评估所收集样本的 "平均 "甲基化的任务得到了很好的解决,但由于所收集材料的异质性和非目标DNA的高背景,这种方法在实践中并不总是有用。有一些FDA批准的测量甲基化的测试用于临床实践,其中大部分在这个测量DNA甲基化的现代方法的伟大概述中列出,但在单细胞水平上测量甲基化的任务仍然有一些困难。例如,现代的单细胞甲基化分析方法,如scBS-seq,受限于中等的CpG覆盖率,大约为20%。本文提出了解决这一问题的方法之一,作者开发了一个基于双向GRU的CNN和RNN组合,称为DeepCpG,它能够预测DNA读数中缺失的CpG位点的甲基化状态。DeepCpG在很长一段时间内被认为是最先进的模型,尽管最近的深度学习方法表明效果更好,如MRCNN卷积网络。
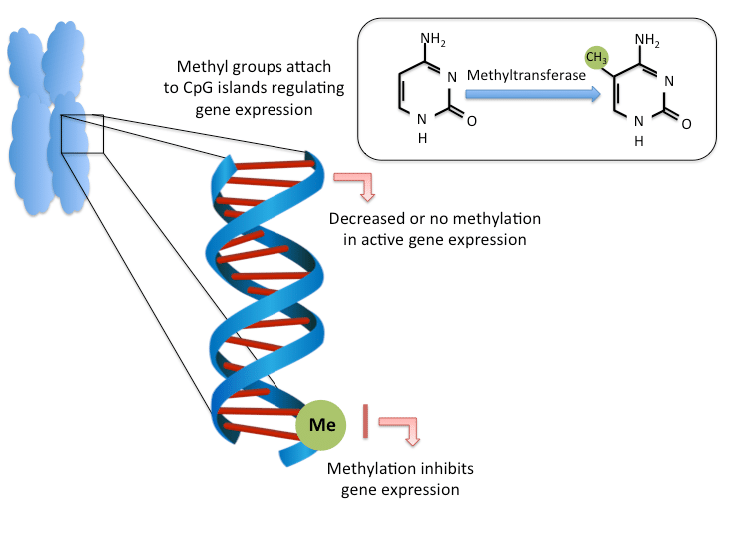
DNA甲基化过程。资料来源:Nevin, Clare & Carroll。Nevin, Clare & Carroll, Michael.(2015).精子DNA甲基化、不孕症和跨代表观遗传学。人类遗传学与临床胚胎学杂志》。1. 10.24966/GGS-2485/100004。,ResearchGate
杂项
人工神经网络也已成功用于检测和识别病毒DNA,设计药物和抗体。这个话题与目前的文章密切相关,但由于它相当广泛,我打算在以后的文章中单独介绍。
请注意,ML在疾病检测方面有多种应用,适用于不同的医疗测试。计算机视觉CNN技术用于CT和MRI医学图像和活检,信号处理RNN用于心电图和脑电图,以及其他许多。
结论
医学中的人工智能正在不断发展和变化。我试图涵盖其中的一小部分,并为你提供一个不错的起点。现在,我希望你对现代人工智能技术如何应用于遗传学和检测遗传性疾病领域有一个印象。不要以为我已经列举了所有的研究领域,并牢记上述大多数的应用和模型可以在许多方面得到改进。我追求的目标是激励你潜心研究这个领域,突破界限,最终使我们的世界变得更美好!"。已经有了一些伟大的进展,但更多的问题还没有得到解答。
