

解析器组合器是解析的最有用的工具之一。与正则表达式相比,它们的可读性和可维护性要强得多,使它们成为完成更复杂任务的绝佳选择。
这篇文章有两个部分。首先,我将解释解析器组合器如何工作以及它们是由什么组成的。之后,我将指导你使用NimbleParsec(一个用Elixir编写的分析器组合器库)制作一个CSV分析器。
解析器组合器的介绍
在这一部分,我将简要介绍解析器组合器,我们将尝试从头开始构建功能性解析器组合器。我们要做的组合器将是低级的,比你用简单的regex得到的要差;它们的存在是为了说明这个问题。
如果你想看解析器组合器的操作,请直接去看NimbleParsec部分。
什么是解析器组合器?
在编程时,我们经常需要将输入(如字符串)解析为对计算机更友好的数据结构(如树或列表)。
做到这一点的一个快速方法是写一个捕获我们需要的一切的regex表达式。但是这些表达式可能会变得相当冗长和复杂,从而导致代码的丑陋。
如果我们可以改写解析器,将其一对一地映射到输入中的语义单元,并将其结合起来,形成一个针对该输入的解析器,会怎么样呢?
归根结底,解析器组合器就是这样的:一种将简单的解析器组合起来以创建更复杂的解析器的方法。
解析器
那么,解析器到底是做什么的?解析器的主要目标是将一串文本解析为不同的、更有结构的对象,如列表或树。
例如,我们可以接受一个整数的列表作为字符串"3, 1, 4, 1" ,并将该字符串变成一个列表,以更好地表示字符串的固有结构--[3, 1, 4, 1] 。
但是如果我们遇到一个像"3, 1, 4, 1 -- Monday, December 28th" ?或者"oops, I'm sorry" ?为了与其他解析器合成并处理可能的失败,我们还需要在解析器成功的情况下返回其余的输入内容,如果不成功则返回错误。
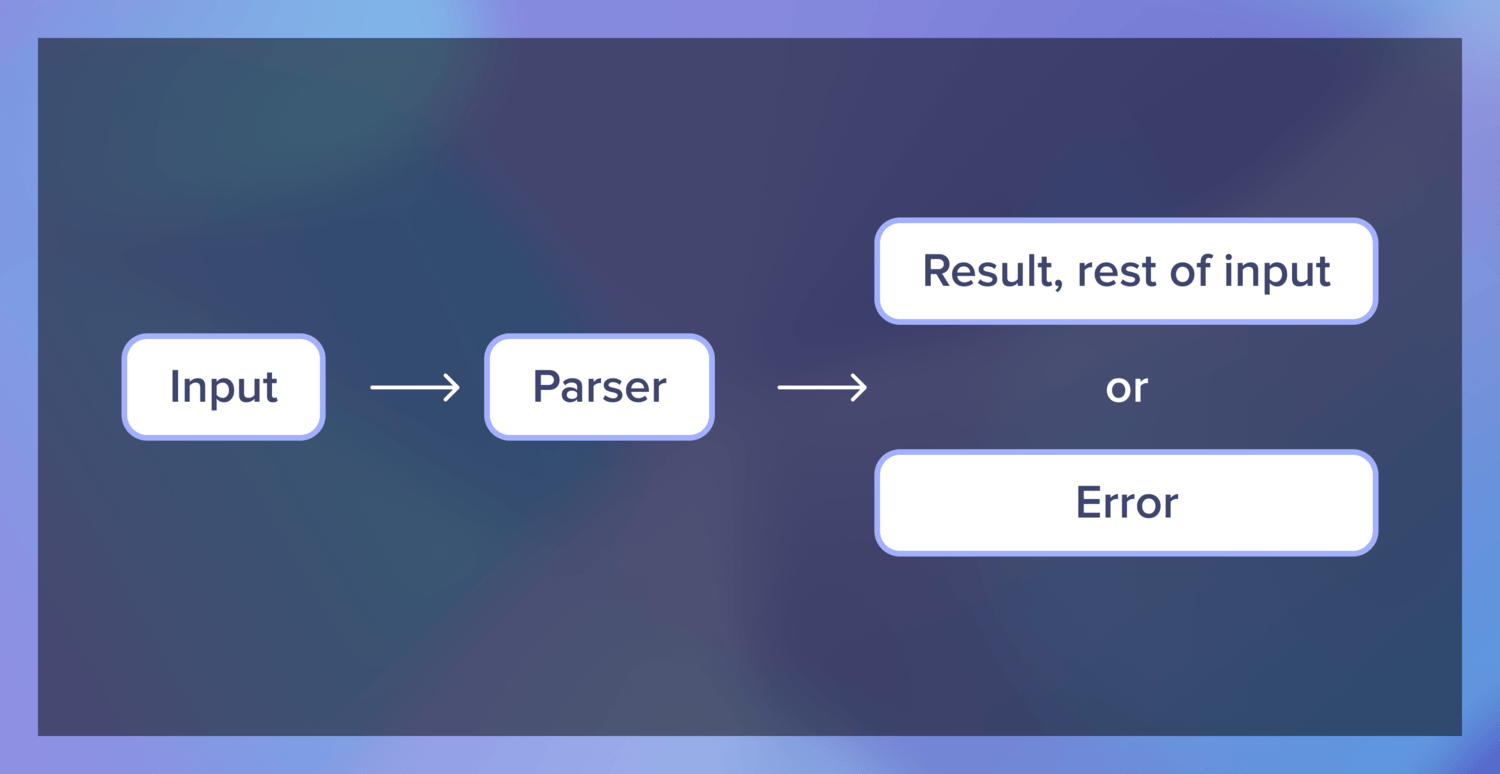
这里有一个在Elixir中解析一个十进制数字的低级解析器的例子:
def parse_digit(<<char, rest::bitstring>>) when char >= 48 and char <= 57,
do: {:ok, [char - 48], rest}
def parse_digit(_), do: {:error, :wrong_input}
如果你问我们能用它做什么,答案是:不多。😅 为了释放解析器组合器的力量,我们需要找到一种方法,把不同的解析器放在一起。
组合器
解析器组合器是一个将两个或多个解析器组合成另一个解析器的函数。

让我们想一想,我们可以用什么方式来组合分析器。最直接的组合是将两个连接在一起--让解析器逐一解析两个小数位:
def concat(fun, fun2) do
fn x ->
case fun.(x) do
{:ok, parsed, rest} ->
case fun2.(rest) do
{:ok, parsed2, rest2} ->
{:ok, parsed ++ parsed2, rest2}
err ->
err
end
err ->
err
end
end
end
这里,产生的解析器将第一个函数应用于输入,然后将第二个函数应用于第一个函数返回的其余输入。我们将被解析的项目作为一个列表返回,同时返回第二个函数没有消耗的输入。如果有一个错误,它就会被进一步传递。
.png)
现在我们可以重复使用我们的组合器来创建一个解析器,可以连续解析2个、3个、甚至4个、甚至更多的整数但这仅仅是个开始。
还有其他多种组合器的可能性。一个常见的组合是选择,它的天真版本可能看起来像这样:
def choice(fun1, fun2) do
fn x ->
case {fun1.(x), fun2.(x)} do
{{:ok, parsed, rest}, _ } -> {:ok, parsed, rest}
{_, {:ok, parsed, rest}} -> {:ok, parsed, rest}
{err, _} -> err
end
end
end
在这里,它将逐一尝试解析两个不同的解析器,并选择首先成功的那个,或者返回一个错误。
我们的简单组合器可以做出一个解析器来解析两个或三个数字:
def digit_parser() do
fn x -> parse_digit(x) end
end
def two_digits() do
digit_parser()
|> concat(digit_parser())
end
def three_digits() do
digit_parser()
|> concat(digit_parser())
|> concat(digit_parser())
end
def two_or_three_digits() do
choice(three_digits(), two_digits())
end
iex(1)> SimpleParser.two_or_three_digits.("55")
{:ok, [5, 5], ""}
iex(2)> SimpleParser.two_or_three_digits.("5a")
{:error, :wrong_input}
通过组合不同的解析器,你可以建立大型的、复杂的解析器,比如说代表JSON或XML等语言的规则。
真正的分析器组合库通常提供各种不同的组合器,使之能够以可读的方式表示分析器。我们稍后将在我们的NimbleParser 例子中看到这一点。
解析器组合器的错误处理
我们初步的错误处理是相当幼稚的,我被告知有一种误解,认为分析器组合器对错误的处理很糟糕。让我们看看我们如何能够轻松地扩展我们的分析器,以显示意外输入的位置。
首先,让我们改变一下parse_digit 处理错误的方式:
def parse_digit(<<char, rest::bitstring>>) when char >= 48 and char <= 57,
do: {:ok, [char - 48], rest}
def parse_digit(<<char, _rest::bitstring>>), do: {:error, {:unexpected_input, <<char>>, 1}}
def parse_digit(""), do: {:error, :end_of_string}
def parse_digit(_), do: {:error, :not_string}
除了输入错误之外,EOS错误也很容易发生,所以我确保涵盖这一点。
现在我们可以修改我们的连接组合器,以跟踪输入错误的位置,如果它发生的话:
def concat(fun, fun2) do
fn x ->
case fun.(x) do
{:ok, parsed, rest} ->
case fun2.(rest) do
{:ok, parsed2, rest2} ->
{:ok, parsed ++ parsed2, rest2}
{:error, {:unexpected_input, input, pos}} ->
{:error, {:unexpected_input, input, String.length(x) - String.length(rest) + pos}}
err ->
err
end
err ->
err
end
end
end
选择组合器已经很好地处理了这些错误。你可以在这里看到最终的结果。
现在,当我们尝试做two_or_three_digits.("5a") ,我们会得到{:error, {:unexpected_input, "a", 2}} 。如果我们把代码作为一个库公开,我们可以很容易地做出漂亮的错误信息。
当然,这段代码只是为了演示,但类似的方法在megaparsec ,这是一个Haskell分析器组合库,以其漂亮的错误报告闻名。
你可以在哪里使用分析器组合器?
由于解析器组合器比重组函数强大得多,你可以用它们来解析具有复杂、递归结构的项目。但是它们也可以用于简单的解析器,例如,一个项目可以有很多不同的备选方案。
不过,它们并不能取代regex。每个工具都有它的好处。我会用regex来处理简单的脚本或单行代码,用分析器组合器来处理大多数其他的分析需求。
顺便提一下:我在这一部分得到了Jonn Mostovoy的帮助,他最近出版了一本关于在Rust中使用分析器组合器的实践指南。如果你有兴趣了解如何在裸机语言中处理它们,我建议你去看看。
用NimbleParsec创建你自己的CSV解析器
NimbleParsec是一个使用元编程的库,为你提供高效的解析器,编译成二进制模式匹配。在这一节中,我们将使用它来建立一个简单的CSV解析器,它将接收一个CSV文件并将其转换为一个列表的列表。
设置
首先,让我们使用mix new CSVParser ,创建一个名为CSVParser的新项目。之后,将{:nimble_parsec, "~> 1.0"} 添加到mix.exs 的依赖列表中,并在模块中导入NimbleParsec:
defmodule CSVParser do
import NimbleParsec
end
语法
现在我们必须考虑CSV文件的结构。
CSV由多行组成,每行由逗号分隔的数值组成。我们也许可以定义一个CSV值,然后用这个定义来定义一个行。让我们用英语写出简单的定义:
- 值是一个字符串(我们暂且忽略数字、转义字符和浮点)。
- 行由一个值组成,然后是可能重复的(逗号,然后是值),然后是一个EOL字符。
我们如何使用库中的函数来反映这个简单的语法?
构建块
让我们试着为值和行建立单独的解析器。
为了实现value,我们需要考虑用什么字符来分隔这些值。一个很好的竞争者是, ,但你也可以遇到换行符\n 和\r 。值也可以是空的,所以我们需要提供这个。
最适合我们目标的是utf8_string ,它让我们提供几个参数,如not (不解析哪些字符)和min (最小长度):
value = utf8_string([not: ?\r, not: ?\n, not: ?,], min: 0)
然后,我们需要定义一个行。对我们来说,一行是一个值,然后是一个逗号和一个值,重复0次或多次,然后是一个EOL字符。
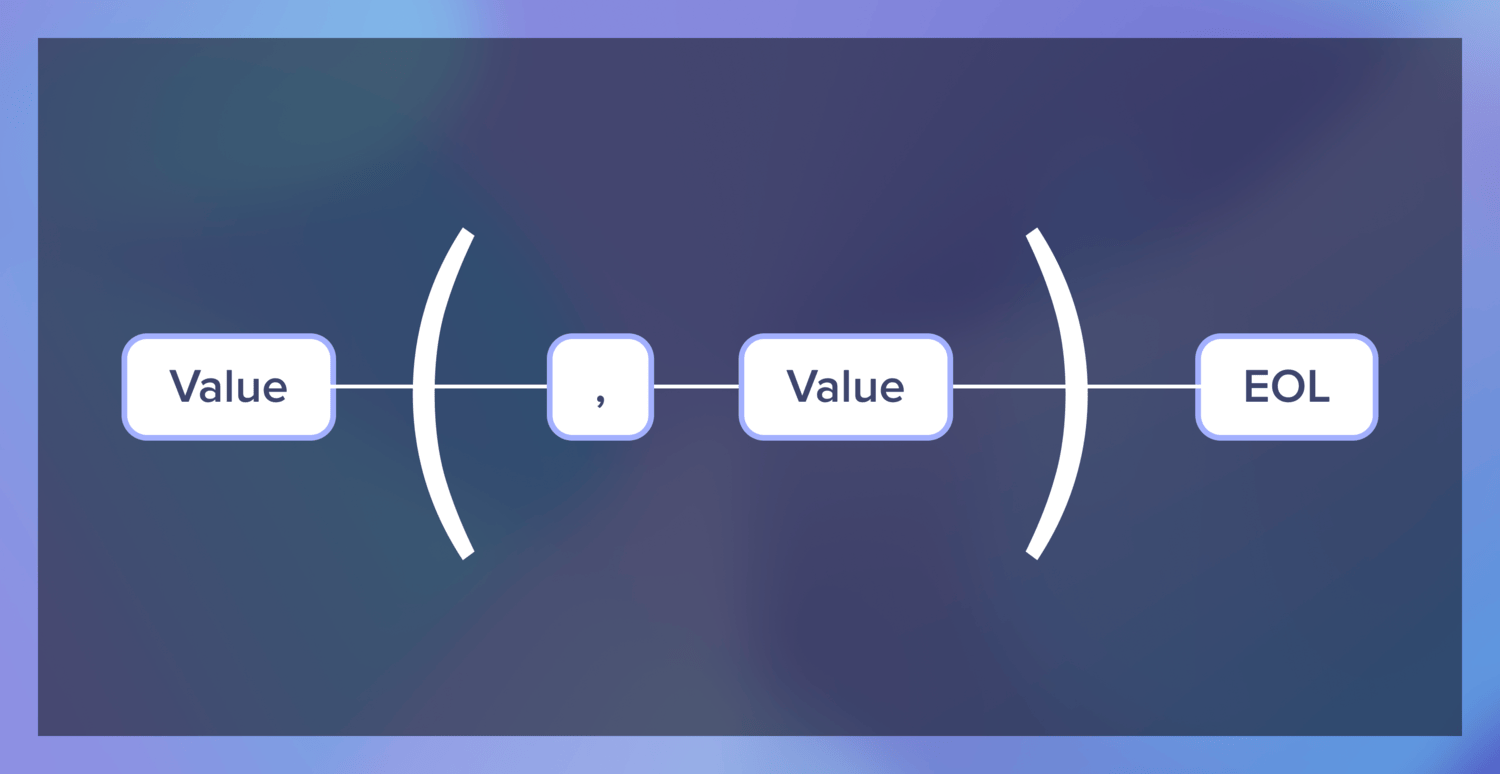
我们已经定义了值,但让我们快速定义一个涵盖Windows、macOS和Linux的EOL解析器。
eol =
choice([
string("\r\n"),
string("\n")
])
正如我们之前看到的,choice使我们能够从一个函数列表中解析出第一个成功的选项。
之后,我们可以使用组合器ignore,concat, 和repeat 与我们定义的解析器一起定义一个行:
line =
value
|> repeat(ignore(string(",")) |> concat(value))
|> ignore(eol)
ignore 将忽略该字符并向前推进,不解析任何东西, 组合两个解析器, 重复一个解析器,直到它不成功为止。concat repeat
把它组合起来
现在我们有了行元素,定义完整的解析器就非常容易了。要做到这一点,我们需要使用defparsec 这个宏:
defparsec :file, line |> wrap() |> repeat(), debug: true
在这里,我们解析一个行,用[] ,然后重复这个过程,直到它不成功。现在,如果我们读取一个CSV文件,CSVParser.file(file_contents) 将解析简单CSV文件的内容。
这里是所有的代码:
defmodule CSVParser do
import NimbleParsec
value = utf8_string([not: ?\r, not: ?\n, not: ?,], min: 0)
eol =
choice([
string("\r\n"),
string("\n")
])
line =
value
|> repeat(ignore(string(",")) |> concat(value))
|> ignore(eol)
defparsec :file, line |> wrap() |> repeat(), debug: true
end
万岁,一个可以工作的CSV解析器!
或者是吗?🤔
为转义做准备
我们的CSV定义是非常简单的。它没有涵盖CSV中可能出现的一些东西,而且它对数字和字符串的处理也是一样的。可以说,我们可以在换行符上分割文件,在所得的列表上映射出逗号的分割,并取得相同的结果。
但是,由于我们已经建立了一个良好的基础,向解析器添加新的定义要比改进一个双行函数简单得多。现在让我们试着解决其中的一个问题。
其中一个问题是,CSV文件的条目中可能有逗号。我们的分析器总是在逗号上进行分割。让我们添加一个选项,通过用双引号包裹条目来转义逗号。
要做到这一点,我们需要扩展我们的值定义。
一个转义的值由零个或多个字符组成,用双引号包围。如果转义值里面有一个双引号,那么这个双引号就需要被另一个双引号所转义。
换句话说,这些都是有效的选项:
text
"text"
"text, text"
"text, ""text"""
首先,我们的项目被双引号所包围:
escaped_value =
ignore(string("\""))
???
ignore(string("\""))
然后我们需要弄清楚如何解析双引号内部的内容以满足要求。
在经历了一个相当迂回的方法来实现这一点之后(你不会想知道🙈),我在Real World Haskell中发现了一个提示,我们可以直接逐个读取项目的字符,只匹配连续的两个双引号或一个非引号字符。
这样就可以解析一个字符了:
escaped_character =
choice([
string("\"\""),
utf8_string([not: ?"], 1)
])
现在我们可以在escaped_character 上使用重复组合器,然后将我们解析的所有字符连接起来:
escaped_value =
ignore(string("\""))
|> repeat(escaped_character)
|> ignore(string("\""))
|> reduce({Enum, :join, [""]})
让我们把原来的值重命名为regular_value ,并让值在escaped_value 和regular_value 之间选择。
escaped_character =
choice([
string("\"\""),
utf8_string([not: ?"], 1)
])
regular_value = utf8_string([not: ?\r, not: ?\n, not: ?,], min: 0)
escaped_value =
ignore(string("\""))
|> repeat(escaped_character)
|> ignore(string("\""))
|> reduce({Enum, :join, [""]})
value =
choice([
escaped_value,
regular_value
])
我们需要把escaped_value 放在前面,因为否则,在我们有机会转义之前,解析器就会在我们的字符串上用regular_value 来成功。
你可以在这里看到完整的解析器代码。
进一步的改进
当然,这个解析器还可以进一步改进。例如,你可以添加对额外的空白或数字的支持,这是一个令人兴奋的练习,可以自己去做。
我希望这是一个令人兴奋的旅程,而且你今天学到了一些新东西如果你想阅读更多关于Elixir的文章,欢迎你浏览我们的Elixir文章,并在Twitter、DEV或Medium上关注我们,以便在我们发布新文章时收到更新。
此外,我的队友还发表了一篇关于Haskell中解析器组合器的文章,非常详细。如果你想了解更多关于分析器组合器(以及在Haskell中构建S表达式分析器),我建议你去看看。
