

Varun Ojha博士是英国雷丁大学的计算机科学讲师。此前,他曾在瑞士的公共研究大学苏黎世联邦理工学院担任博士后研究员,并在捷克共和国的奥斯特拉瓦技术大学担任居里夫人研究员。自2010年以来,他的研究主要集中在人工智能领域,特别是:神经网络、深度学习和计算机视觉。他还在研究数据科学中的优化技术。
在这次采访中,Varun Ojha博士分享了他工作中的理论见解和实践建议。我们讨论了诸如训练神经网络的最佳策略、过度拟合和开源数据集等话题。
采访Varun Ojha博士
你现在在做什么项目?
我专门研究称为神经树的算法。这些算法同时解决特征工程和函数近似的任务。我还在研究对抗性强的深度学习,研究如何使深度学习免受对抗性攻击。对抗性攻击是指对机器学习模型的输入导致其失败。例如,一个模型被设计用来识别汽车。如果你改变图像中的几个像素,汽车可能被识别为不同的物体。如何使这样的模型健壮可行?许多研究人员现在正试图解决这个问题。
我的神经网络研究主要是理论上的。最近,我一直在研究一种叫做反向传播神经树的稀疏神经树算法,它可以用来有效地解决机器学习问题,如分类、回归和模式识别。但是,尽管是理论性的,这项研究在现实世界中有直接的应用。
你的技术栈是什么?你最常使用的语言、框架和库是什么?
我用Java编程。但在我的领域,Python是最常用的编程语言。因此,我现在也在研究Python编程,因为这已经成为机器学习的语言,主要是由于Keras、TensorFlow和PyTorch等库。对于我的学生,我经常推荐PyTorch,因为它很容易使用而且很有效。
今天神经网络领域最重要的趋势是什么?科学家们正在努力解决的最大问题是什么?
现在最大的两个挑战是自然语言处理和计算机视觉。
其中一个研究问题是训练算法的成本问题。例如,在自然语言处理中,最大的网络是GPT-3,它有超过1750亿的参数。训练网络可能需要1000万到2000万美元,只有大公司才能负担得起。这些公司为特定的任务(如场景识别)训练网络,并将其提供给普通的研究人员,以应用于他们的工作。我在最近关于洪水监测的研究中使用了一个这样的预训练网络,我在其中训练算法来区分洪水场景和非洪水场景。
你正在试验的数据集是什么?你会推荐其中的哪一个,为什么?
我一般使用所谓的基准/最先进的图像识别数据集。MNIST,CIFAR10,ImageNet,COOC,Cityscapes, 和KITTI。它们都是开源的数据集,在Papers With Code和Kaggle等流行的网页上可以找到更多可以免费使用的数据库。
对于需要独立存储的自行收集的数据集,我一般使用云存储或大学提供的存储。但对于需要在亚马逊网络服务(AWS)上训练ML模型的项目,我们会在那里存储一个数据集。对于一些项目,我使用谷歌Collab Pro。我的一些学生也使用NVIDIA DIGITS。
数据集的选择取决于任务。由于我的研究集中在图像分类和算法的改进上,我更多地使用CIFAR10和ImageNet。我通常同时使用3-4个数据集来比较我的算法的性能。
你是如何选择NN结构并确定其中的最佳层数的?
选择NN结构是基于NN的研究中最关键的问题。对这个问题没有直接的答案。让我带你了解一下选择深度神经网络结构时的一些基本步骤。
在一个非常基本的层面上,输入和输出层取决于你要解决的问题。例如,对于一个图像分类问题,你的第一层通常是一个2D/3D卷积层。最后一个是密集层(全连接层),输出层的节点数等于数据集中的类的数量。对象分割任务的最后一层是2D/3D卷积层,因为我们需要对图像本身的部分进行分割。
除此以外,深度神经网络还有几种类型的层:卷积层、池化层、批量规范化层、丢弃层和密集/FC层。

每个人还可以选择内核/神经元的数量。在这里,深度和宽度与模型中的参数数量成正比,这意味着参数越大,训练时间越长,训练成本越高。另外,模型的复杂性和推理时间(在测试场景中对单一输入的模型预测速度)会随着参数的增加而增加。因此,在模型训练成本/时间/复杂性/可解释性和你想达到的精度之间存在权衡。
有广阔的超参数优化技术,你可以使用贝叶斯优化、强化学习算法和基于梯度的神经架构搜索等方法来确定正确的NN架构。
而在浅层神经网络方面,我则致力于研究一种叫做神经树的特殊类神经网络,网络架构的优化是通过遗传编程完成的。在我最近的一些研究中,"Backpropagation Neural Tree"我发现,"任何随机梯度下降训练的任何先验稀疏'任意变薄'的神经网络,与对称全连接神经网络相比,会有更好或同等程度的准确性。"事实上,我发现只有14%的NN和反向传播神经树参数能够以高准确度解决分类问题。
这表明,人们需要谨慎对待模型的复杂性。在机器学习中,复杂性越低,模型的泛化能力就越好。
对于没有太多经验的从业者,你会如何建议他们选择超参数?
你必须决定你是想使用复杂的还是简单的模型,并通过实验测试哪里的误差可以达到最小。比方说,你正在处理一个图像处理任务。
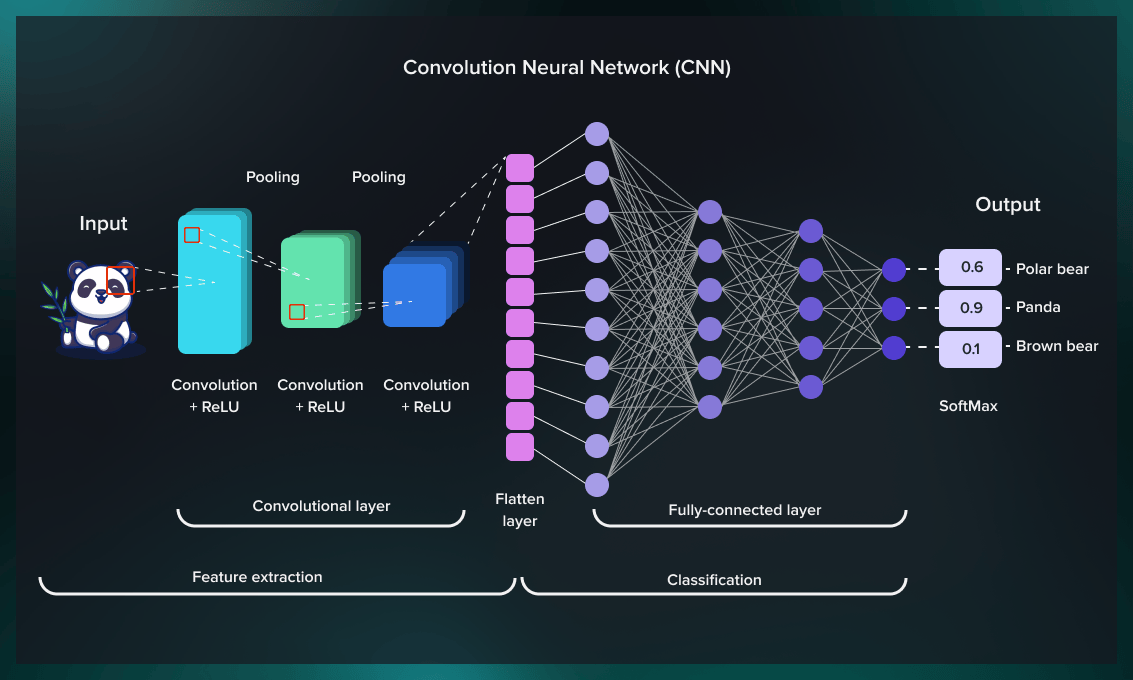
一旦第一层固定下来,因为你有一个数据集,并使用数字版的图像作为你的输入层。然后你做卷积层。在你做完这些之后,你继续做扁平化层,最后,做结果层。这样,你就建立了你的基本NN架构,测试性能,然后通过逐步增加层和改变超参数(如核的数量)来改进它。如果你发现性能不够好,你可以增加更多的层,看看它的发展情况。如果它最终变得更糟,可以尝试减少添加的层的数量。所以它总是一种实验性的方式。在这一点上,我们没有任何关于如何选择超参数的经验法则。在我们最近的一些工作中,我们试图分析深度学习超参数的敏感性。
平衡NN的大小、使用的方法和成本的标准是什么?
正如我之前所说,NN的训练成本(时间和金钱)和模型大小是需要小心权衡的。主要的标准是一个NN模型能预测多好的事情。因此,测试精度(即在未见过的数据集上的精度)是我们讨论的所有大型模型的驱动力。
然而,预训练的模型越来越受欢迎。因此,NN模型的大小在许多情况下可能不像从头开始训练NN那样有问题。对于NLP和视觉任务,都有预训练的模型可以应用,并为其特定的数据集进行微调或重新设计。在这里,人们在选择预训练的NN模型时,需要注意任务的相关性。例如,如果任务是一般的物体识别,那么像YOLO或Mask-RCNN这样在COCO东西数据集上训练的NN模型将是用户的选择。
因此,研究人员必须通过实验来找到这种平衡。你能给初步估计一些更实际的建议吗?
比方说,你正在使用ImageNet。这是一个拥有数百万张图片的巨大数据集,对于一个普通的研究人员来说,即使有一个简单的模型,也很难通过。但是今天你可以使用GPU或者像Google Collab这样的云服务。Google Collab为你提供24小时的免费或有时非常便宜的计算。因此,你可以估计这种数据集是否可以在24小时内完成训练。相应地,你设置了epochs的数量。这样,你可以先用少量的迭代来测试你的算法,观察你的测试训练和验证损失的进展。然后,如果你看到两者都很好,你可以,比如说,设置100个epochs,并在一夜之间训练该数据集。当然,成本也取决于网络的大小。我不建议使用具有数十亿参数的网络,因为已经有大量的最先进的算法可以用于他们的应用。
你是如何解决过拟合问题的?你能分享一些实用的技巧吗?
过度拟合可以通过 "早期停止 "和在训练期间对NN进行正则化等技术来解决。早期停止检查NN训练性能与NN验证性能在任何特定时间点的比较。如果NN在未见过的数据上的验证性能从某一点开始显示出更差的结果,我们就停止NN的训练,并回落到以前的最佳状态。
除了早期停止外,使用权重正则化和退出层也能有效控制过拟合。在制作深度NN模型架构时,从相对较小的基础模型开始。然后使用网格搜索技术或我们前面讨论的超参数优化方法之一,迭代地增加层。
你从事实时物体识别工作吗?你能分享一下最新的趋势吗?今天有什么比YOLO更好的工作?
我在一些项目中使用了一些检测器(用于物体检测的深度神经网络),如Mask-RCNN和YOLO预训练的网络,如视频中的废水瓶检测,以及在赛船中测量速度和跟踪船只。对于其他一些项目,如用于洪水预测的水位识别,我使用了图像分割的R-CNN系列算法。我们在检测真实的洪水事件方面取得了相当高的准确率(约94%)。
这两个检测器有很多版本,如Faster R-CNN和YOLOv5。RetinaNet也是目前使用的一种非常有效的物体检测算法。
对于物体检测,每种算法都有自己的优点和缺点。例如,R-CNN系列的物体检测比YOLO系列的实时检测的推理时间要慢。然而,当实时检测不是一个约束条件时,那么R-CNN系列可以给出更高的检测物体的效率。还有一些库,如Facebook团队开发的Detectron2,支持类似R-CNN的算法进行物体检测。
NNN背后的过程是一个黑盒子。研究人员如何向企业解释结果?你是否开发了自己的系统来评估结果?
的确,神经网络的黑匣子性质是一个大问题。这与一种叫做决策树的流行机器学习算法相对立,后者是一种可解释的机器学习。神经网络的基本设计首先是混合几个加权的输入特征,其次是使用非线性变换将其转化为另一个特征。这种加权混合和逐层使用激活函数的非线性转换在很大程度上归因于使NN成为一个黑盒子。
NN的可解释性是一个具有挑战性的研究领域。当涉及到图像识别时,我们可以观察到算法在每个迭代中的行为。对于卷积深度神经网络,人们可以检查卷积层的特征图,以直观地发现,对于一个给定的输入,哪个内核/部分的NN过程和输入图像的哪个部分负责预测。例如,如果你输入一个汽车的图像到这个NN中,哪些NN部分处理车轮、挡风玻璃、汽车的形状等,都可以被检查出来。
为了解释神经网络,我们可以使用可视化的层级特征相关性传播,了解特征的相互作用,也就是说,我们可以尝试了解对于什么输入,NN会以什么方式表现出来,或者对于扰动输入特征,其准确性会有多大变化,以及NN对图像的哪些部分给予最多关注。
正如我所说,我的工作是关于被称为神经树的算法。这些是一种神经网络,其中神经树对给定输入的决定通过树的特定分支传播,使可解释性成为这类神经信息处理算法的内在因素。你可以查看我在《神经网络》(2022)上发表的关于反向传播神经树的工作,以了解更深入的情况。
您未来的研究计划是什么?你想探索什么?
我将继续研究神经网络,我的目标是开发可解释的算法。正如我们所讨论的,缺乏可解释性是这个领域的一个大问题。
我还在研究如何降低训练成本。总的来说,就是要更好地理解神经网络。我的雄心是开发高效的神经网络算法,其灵感来自于神经科学,即以人脑中的神经元为模型。我觉得这非常令人兴奋。
