

面向B端的系统有什么特点
-
实际用户数量可能不多,相比于C端动辄以万或百万计的同时在线人数,B端系统的总注册用户数量可能才几十几百个;
-
并发量几乎可以不考虑,但是一个操作的内部流程可能有数十个步骤,涉及的数据项比较多;
-
业务方操作系统的门槛较高,而且研发团队没什么办法降低它。
什么样的架构才算好
没有最好的,只有合适的。
- B端系统所采用的技术栈一般选择传统的和稳定的;
- 如果客户方已经有一套业务支持系统,采用的技术栈最好和原来的体系保持一致;
- 评估研发团队拥有的资源,包括人员数量、个人能力、允许投入的研发时间和业务成熟度。
一个来自真实项目的架构
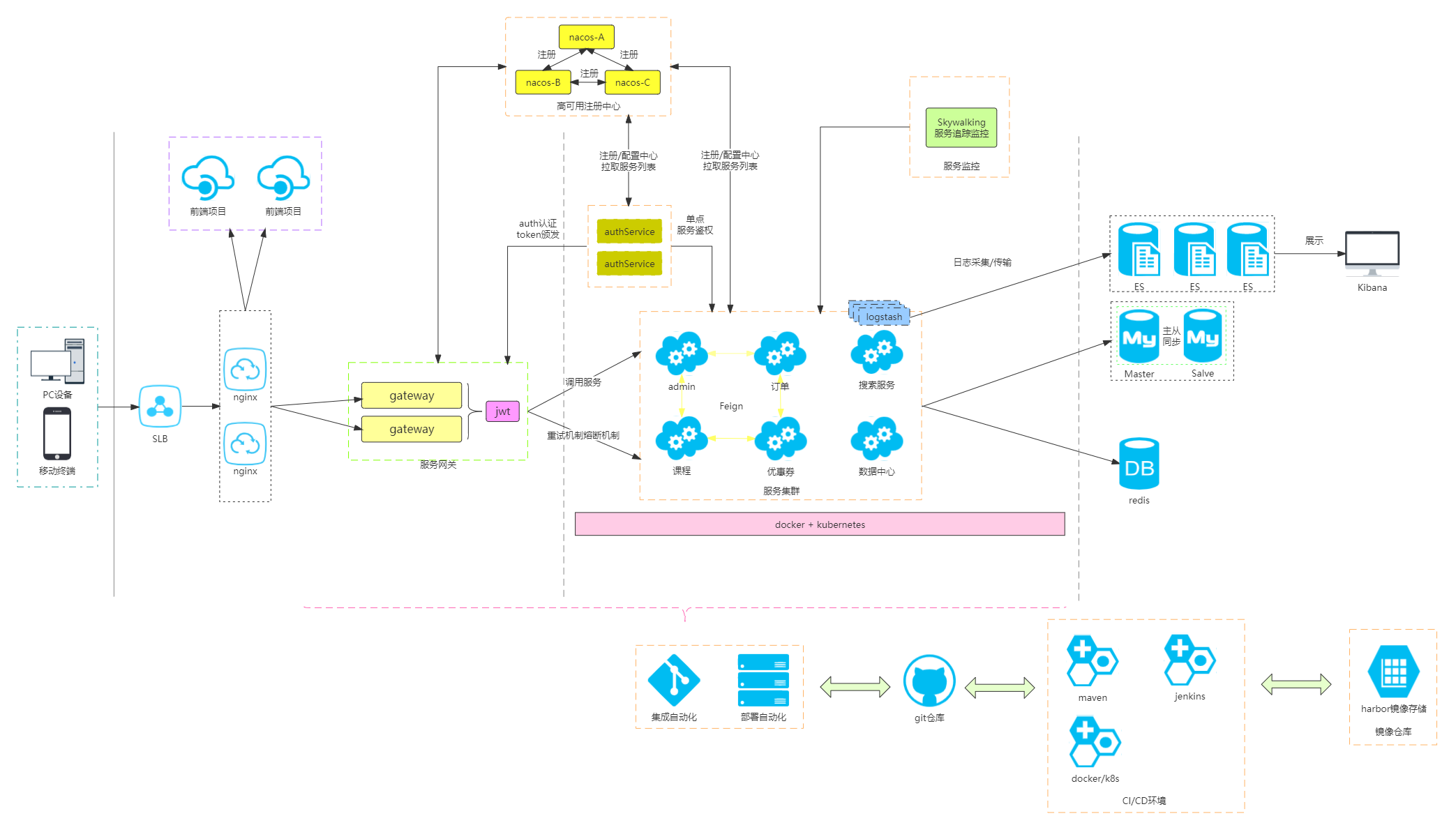
对上述架构的一些解释
配置和注册中心
- 采用开源的Nacos作为配置中心;
- Nacos同时还是服务注册中心;
- 部署在容器中,3个节点组成集群。
认证和鉴权
- 有一个单独的认证和鉴权服务,提供登录、查询用户信息和访问权限校验等基础能力;
- 从用户端发起请求时,在网关层通过OpenFeign调用认证和鉴权接口;
- 登录后返回给用户端的token是jwt格式的,从token中可以解析得出不敏感的少数几项用户信息,比如用户id和账号名。
后端服务的关系
- 从用户端发起访问请求时,通过网关转发给实际提供接口的后端服务;
- 各后端服务之间是平等的,通过OpenFeign可以相互访问,获得对方提供的能力;
- 后端服务之间共享同一个traceId,用户端发起的一个业务请求经过多个后端服务,通过traceId可以查到一次请求产生的整条链路的日志。
前端不简单
- 前端不应该承担复杂的业务计算和流程控制;
- 开发者不要对最终的用户提出太高要求,哪怕是业务复杂,使用门槛较高的B端系统;
- 用户不会和开发者共情,显示给用户的提示信息都要“说人话”。
尽量容器化
- 架构设计时,就要考虑可以水平扩展,通过容器化部署,水平扩展更加便捷;
- 服务器资源在容器化部署时可以更加灵活地调配,使用率更加充分;
- 容器化可以有较低的成本,监测服务健康性,并且自动维护服务的状态处于健康状态。
日志采集和分析
- 使用filebeat或logstash采集日志;
- 在Logstash中使用gork做日志切割,转换成结构化数据;
- 日志保存到Elasticsearch;
- 使用Kibana查看日志,监测系统运行情况。
如果像我一样在使用华为云产品化的Elasticsearch,而且是安全模式的,很可能用不了filebeat,因为华为云提供不了必要的SSL证书。
自动化部署
- 在Jenkins配置好编译和部署项目的任务,接收从Gitlab推送的事件;
- 在Gitlab中添加webhook,把源码合并事件或创建新标签的事件推送到Jenkins,触发测试环境部署;
- 在容器集群中给各节点打上标签,由容器自行调度,分配给不同的服务实例。
重要的题外话
技术不分贵贱,架构不是拼凑在一起的高大上的东西越多就一定越好。
- 一个普通的业务系统没必要考虑过多的冗余备份问题;
- 业务本身不成熟的系统没必要考虑中台;
- 能用单线程解决的问题就不要引入多线程;
- 技术只是解决问题的手段,不是目的;
- 能在业务设计上避免的难题,就不要用技术去硬扛。
