

在这篇文章中,我们介绍了一个全面的Apache Spark安装指南。
1.简介
Apache Spark是一个开源的集群计算框架,具有内存数据处理引擎。它提供Java、Scala、R和Python的API。Apache Spark与HDFS一起工作,可以比Hadoop Map-Reduce快100倍。
它还支持其他高级工具,如用于结构化数据处理的Spark-SQL、用于机器学习的MLib、用于图形处理的GraphX和用于连续数据流处理的Spark streaming。
下面的安装,步骤是针对macOS的。虽然其他操作系统的步骤和属性都是一样的,但命令可能会有所不同,特别是对于Windows。
2.Apache Spark的安装
2.1 Spark的先决条件
2.1.1 Java安装
在安装和运行Spark之前,请确保Java已经安装。运行下面的命令来验证所安装的java的版本:
$ java -version
如果Java已经安装,它将显示已安装的java版本:
java version "1.8.0_51"
Java(TM) SE Runtime Environment (build 1.8.0_51-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.51-b03, mixed mode)
如果上面的命令没有被识别,那么就从Oracle网站上安装java,这取决于操作系统。
2.1.2 Scala安装
在安装Spark之前,安装Scala是必须的,因为它对实现很重要。检查scala的版本,如果已经安装:
$scala -version
如果已经安装,上面的命令会显示已安装的版本:
Scala code runner version 2.13.1 -- Copyright 2002-2019, LAMP/EPFL and Lightbend, Inc.
如果没有安装,可以通过安装IntelliJ并按照这里描述的步骤来安装。也可以通过安装 sbt 或 Scala Built Tool 来安装,具体步骤见这里。
Scala也可以通过下载scala二进制文件来安装。
在macOS上,也可以使用下面的命令来安装scala。
brew install scala
2.1.3 Spark的安装
从spark官方网站下载Apache Spark。请确保下载最新的、稳定的spark版本。
另外,中央的maven仓库里有很多spark的工件,可以在pom文件中作为一个依赖项添加。
PyPi可以用来安装pySpark。运行命令pip install pyspark 进行安装。
在这个例子中,我下载了Spark 2.4.0并手动安装了它。
为了验证spark已经被正确设置,从spark HOME_DIRECTORY/bin运行下面的命令:
$ ./spark-shell
2019-12-31 13:00:35 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://192.168.10.110:4040
Spark context available as 'sc' (master = local[*], app id = local-1577777442575).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_51)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
3.启动Spark集群
有多种选择来部署和运行Spark。所有这些选项在驱动和工作者在spark中的运行方式上都有所不同。只是为了介绍一下这些术语。
驱动程序是Spark的主要进程。它将用户程序转换为任务,并将这些任务分配给工作者。
Worker是执行器所在的spark实例,它执行驱动所分配的任务。
我们将在下面详细讨论它们:
- 客户端模式
- 集群模式
3.1 客户端模式
在客户端模式下,驱动和工作器不仅运行在同一个系统上,而且还使用同一个JVM。这主要是在开发时有用,因为集群环境还没有准备好。同时,它也使任务的实施和测试变得更快。
Spark有一个捆绑的资源管理器,所以在客户端模式下运行时,我们可以使用相同的资源管理器来避免运行多个进程。
另一种方法是使用YARN作为资源管理器,我们将在谈到Spark的集群模式时详细介绍。
3.1.1 独立模式
独立模式是与Spark捆绑的一个简单的集群管理器。它使建立一个自我管理的Spark集群变得容易。
一旦下载并解压了spark,从spark HOME_DIRECTORY/sbin运行下面的命令来启动master。
$ ./start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /Users/aashuaggarwal1/Softwares/spark-2.4.0-bin-hadoop2.7/logs/spark-aashuaggarwal1-org.apache.spark.deploy.master.Master-1-Aashus-MacBook-Pro.local.out
上述命令将在localhost:8080处启动spark master,在那里可以在浏览器上访问spark门户。

Spark portal at localhost:8080Only
Master
在这里你可以看到,仍然没有工作者在运行。所以现在是时候启动一个工作者了。如果你在上面的图片中看到,显示的是spark master的URL。这就是我们要用来将已经运行的主站与从站映射的URL。从spark HOME_DIRECTORY/sbin运行以下命令。
$ ./start-slave.sh spark://Aashus-MacBook-Pro.local:7077
starting org.apache.spark.deploy.worker.Worker, logging to /Users/aashuaggarwal1/Softwares/spark-2.4.0-bin-hadoop2.7/logs/spark-aashuaggarwal1-org.apache.spark.deploy.worker.Worker-1-Aashus-MacBook-Pro.local.out
现在,如果我们访问localhost:8080,那么我们将看到1个工作线程也已经启动。由于我们没有明确给出内核和内存的数量,工作线程已经占用了所有的内核(本例中为8个)和内存(15GB)来执行任务。
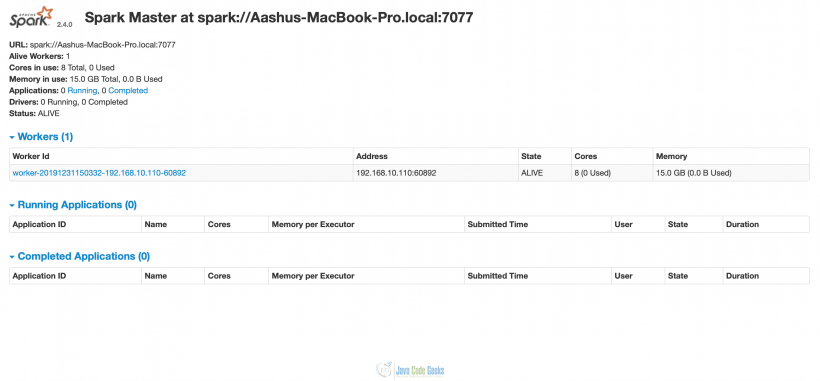
Spark portal at localhost:8080Master
with one slave
3.2 集群模式
客户端模式有助于开发,可以在本地桌面或笔记本电脑上快速进行修改和测试。但是为了利用Spark的真正力量,它必须是分布式的。
下面是生产中的Spark的典型基础设施。
虽然与Spark捆绑的默认资源协商器也可以在集群模式下使用,但YARN(Yet Another Resource Negotiator)是最流行的选择。让我们来看看它的细节。
3.2.1 Hadoop YARN
YARN是一个用于分布式工作负载的通用资源管理框架。它是Hadoop生态系统的一部分,但它支持其他多个分布式计算框架,如Tez和Spark。
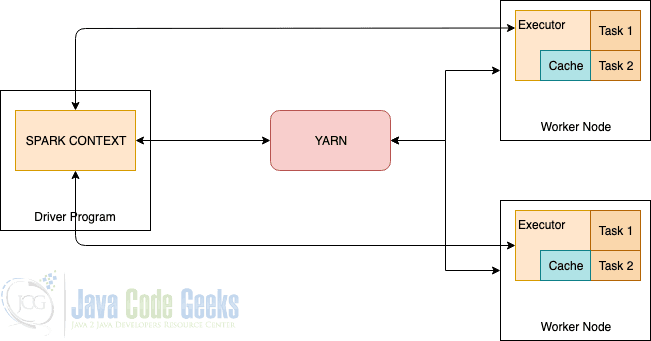
Spark与YARN
正如我们在上图中看到的,YARN和工作节点构成了数据计算框架。
YARN负责系统中所有应用程序的资源仲裁,而Executor则监控各个机器的资源使用情况,并将这些信息发回给资源管理器。
有几个YARN的配置是我们需要注意的。
arn.nodemanager.resource.memory-mb
yarn.nodemanager.resource.memory-mb- 它是指在一个节点中可以分配给容器的物理内存量,单位是MB。这个值必须低于节点上的可用内存。
yarn.scheduler.minimum-allocation-mb- 这是资源管理器需要为容器的每个新请求分配的最小内存。
yarn.scheduler.maximum-allocation-mb- 可以为一个新的容器请求分配的最大内存。
以下是在YARN中运行spark作业时的几个spark配置。
spark.executor.memory- 由于每个执行器都作为YARN容器运行,所以它受到Boxed Memory Axiom的约束。执行者将使用等于以下两项之和的内存分配*spark.executor.memory* + *spark.executor.memoryOverhead*
spark.driver.memory- 在集群部署模式下,由于驱动程序在ApplicationMaster中运行,而ApplicationMaster又是由YARN管理的,所以这个属性决定了ApplicationMaster可用的内存。分配的内存等于以下两项之和 *spark.driver.memory* + *spark.driver.memoryOverhead*.
4.总结
本文解释了如何使用独立的和YARN的资源管理器在客户端和集群模式下运行Apache spark。还有其他的资源管理器,如Apache Mesos和Kubernetes,也可以进行探讨。
