

前言
在复习闭包的时候通过图解涉及到了JavaScript在执行时内存相关的知识点,所以就思考了下在归纳一下这方面的点。以及上一篇中关于闭包导致内存泄露的情况也可以在这篇文章里探讨一下。
其实JS中很多知识只要了解了内存的机制就大多数都能一通百通,迎刃而解。
还是以25分钟的时间让自己大脑发散思维一下,想想任何涉及到JS内存相关的知识点。
25分钟之后(其实5分钟就写完了,20分钟发呆)
内存基础
写代码本身是绕不开内存的,对于C这样的语言来说,它是能手动控制管理内存和释放内存,一般对程序员有更高的要求。对于JavaScirpt这样的语言,则是引擎自动帮我们管理内存,相对来说要求就没那么高。但这不代表说不用去了解这方面的知识,相反越是了解它如果管理内存,就越能加深对这门语言的理解。
在JavaScript中,对于类型的分类就两种。
- 基础类型:
- number
- string
- boolean
- null
- undefined
- bigInt
- symbol
- 引用类型
- Array
- Object
- Function
- ...
所以在内存中也分了两种内存用于存储JavaScript类型。基础类型由于大小确定,占据空间小,所以会被存在栈内存中,而引用类型由于大小不固定,并且占据空间可能会很大,所以使用堆内存来存储。
关于堆和栈,这属于计算机基础,所以就不解释是什么了。 只说下它们之间的区别是栈内存运行效率比堆内存高,因为栈内存分配的空间是固定的,占用小索引快。
这里有个关于JavaScript的小知识点,那就是不论是基础类型还是引用类型,它们都是按值传递的。
在红宝书里关于这点很详细的解释。
基础类型很好理解,值直接存在栈上,所以对于变量查找值时,直接找到值就完事。 对于引用类型来说,实际上他们的变量也是存在栈内存上,但是值里存放的是引用类型的地址值。 所以在查找时,取的还是值,只不过这个值时地址值,然后通过地址值去堆内存中找到实际的对象。
用简单的代码加一个张图做个示例:
var a = 123
var b = {
name: 'xavier',
age: 188
}
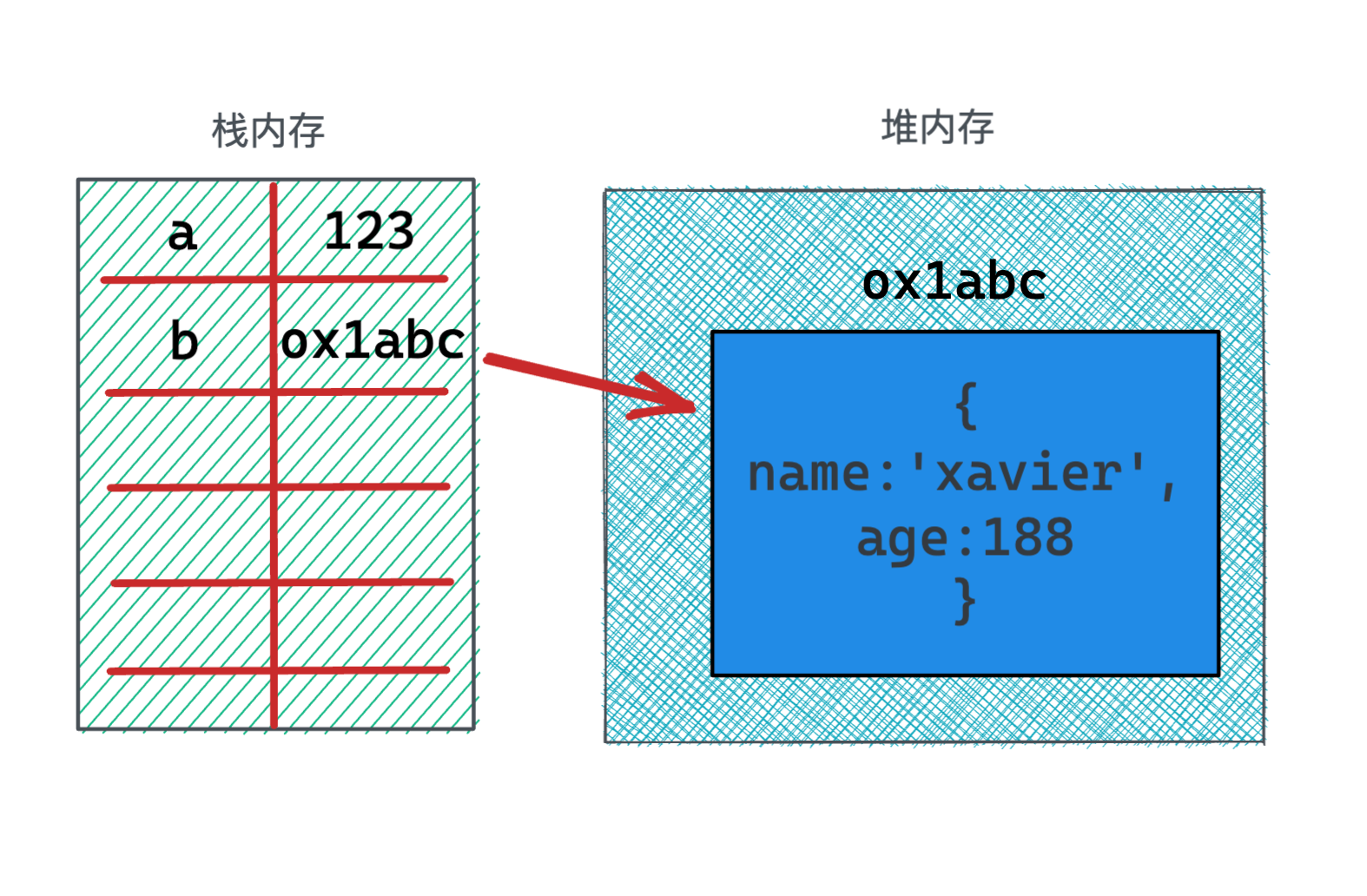
从这图里就能知晓两点,
- 栈内存存了变量的名称,并且对基本类型会存相应的值。而对引用类型存储的是指向堆内存中的地址。二者都是值。
- 引用类型里如果包含了基本类型,那么其实它里面的基本类型也是存在堆内存中。所以如果有人问基本类型是不是都存在栈内存里,这句话就是错的。
内存生命周期
不管是什么语言,是用手动还是自动的方式管理内存,内存的生命周期就3个步骤:
- 分配申请所需的内存空间
- 使用分配的内存进行读写
- 不需要之后进行释放
对栈内存来说,就是自动分配固定大小的内存空间,然后再不使用后会被自动释放。 对堆内存来说,空间大小是动态分配,所以大小不固定,并且不使用后也不会自动释放,而是等到一定时间后被垃圾回收。
JS中内存分配
对于变量来说,在变量创建时就完成了内存分配,这在之前复习闭包的文章里有通过图画过。会在内存里开辟空间存放变量和对象。
对于函数来说,在创建时也会在堆内存中分配一块空间,其内部的变量和对象则是在调用后生成执行上下文时才会创建。
通过一个小例子来讲解在代码执行过程中内存里变量的变化。
var a = 123
var b = a
b = '321'
var objA = {
name: 'xavier',
height: 188,
}
var objB = objA
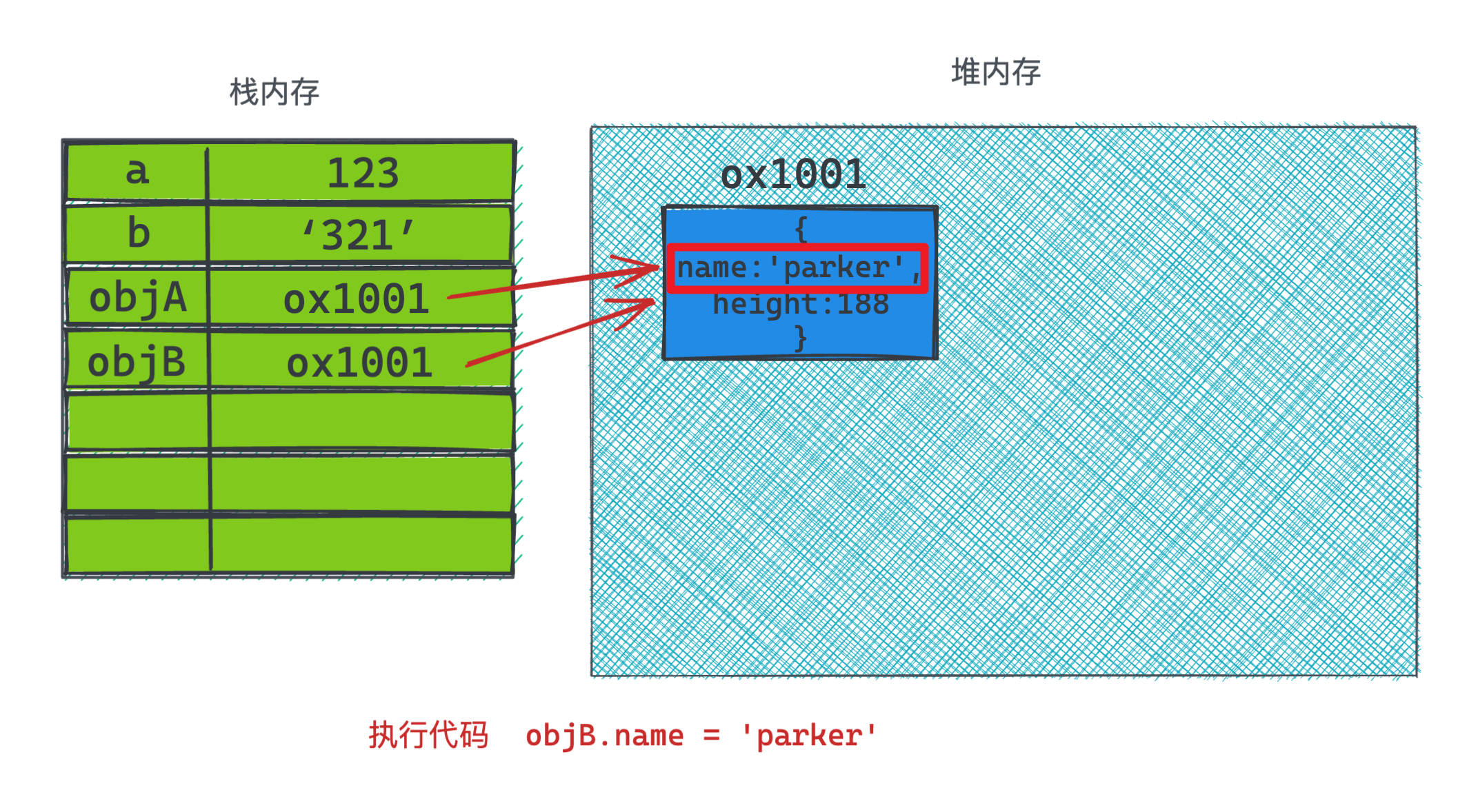
objB.name = 'parker'
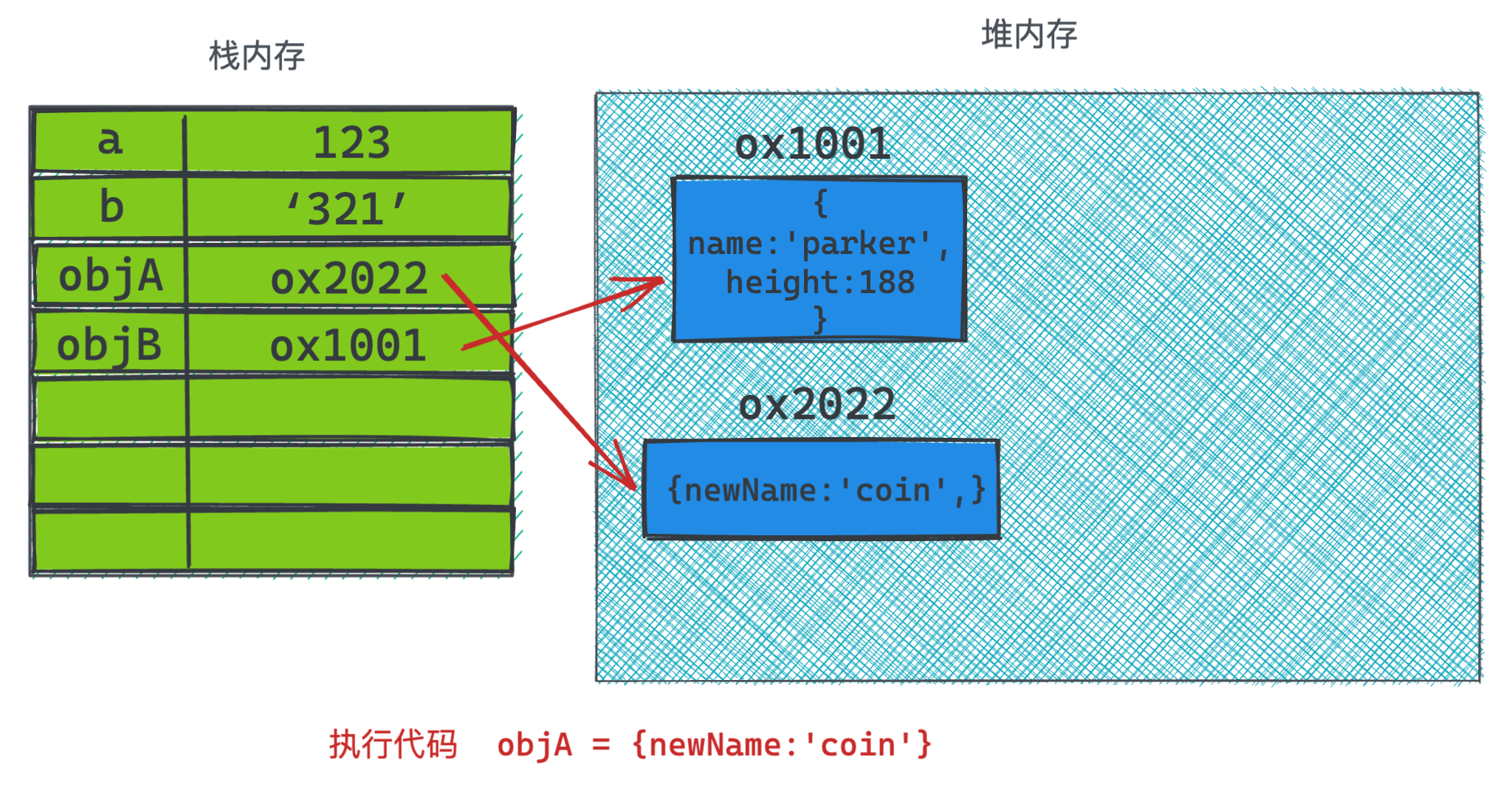
objA = {
newName: 'coin'
}
在代码刚执行时内存里的状态是:
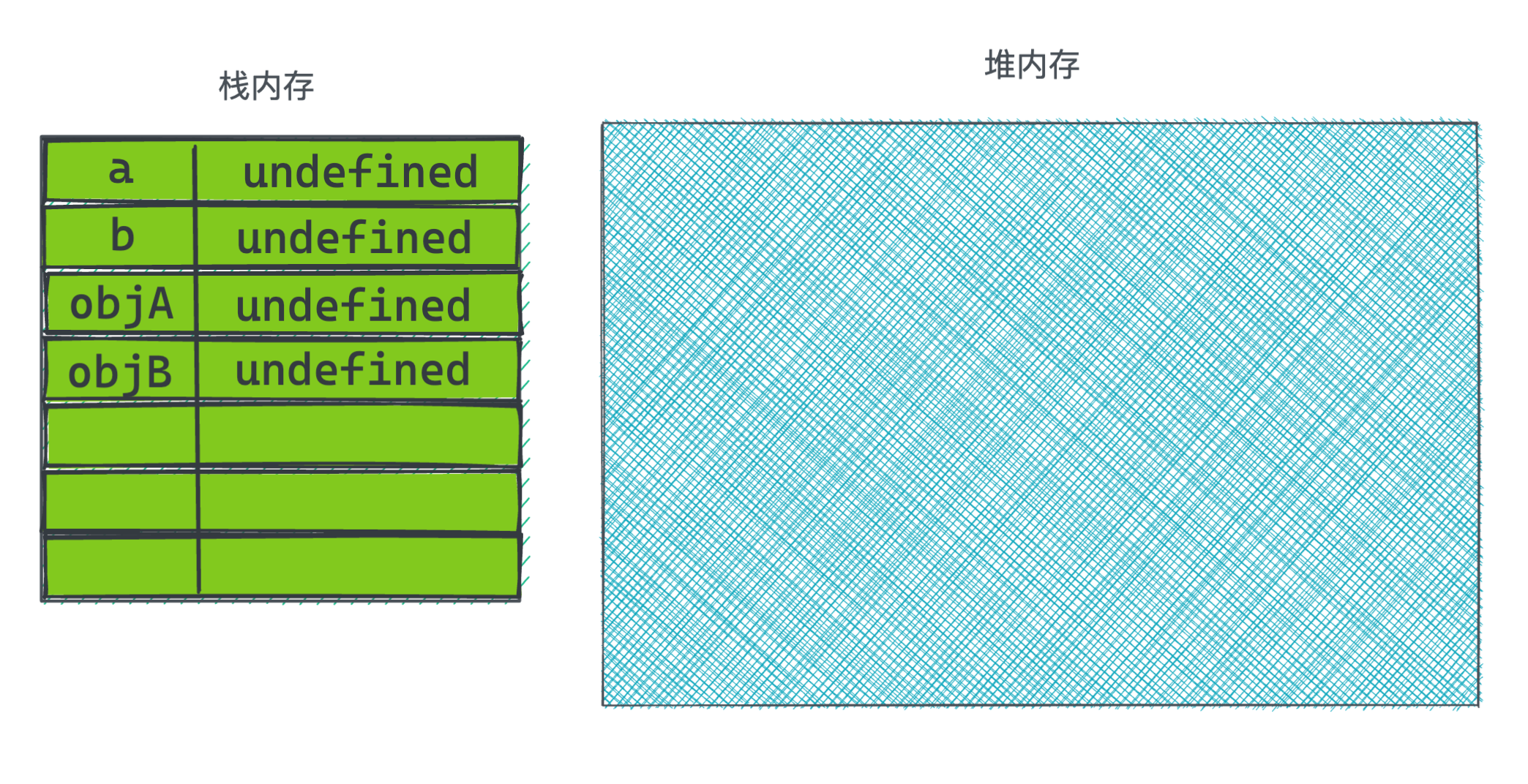
代码执行前两行先是给a赋值为123,然后变量b指向a,所以也相当于赋值了123,但到第三行后b又重新赋值成了字符串'321':
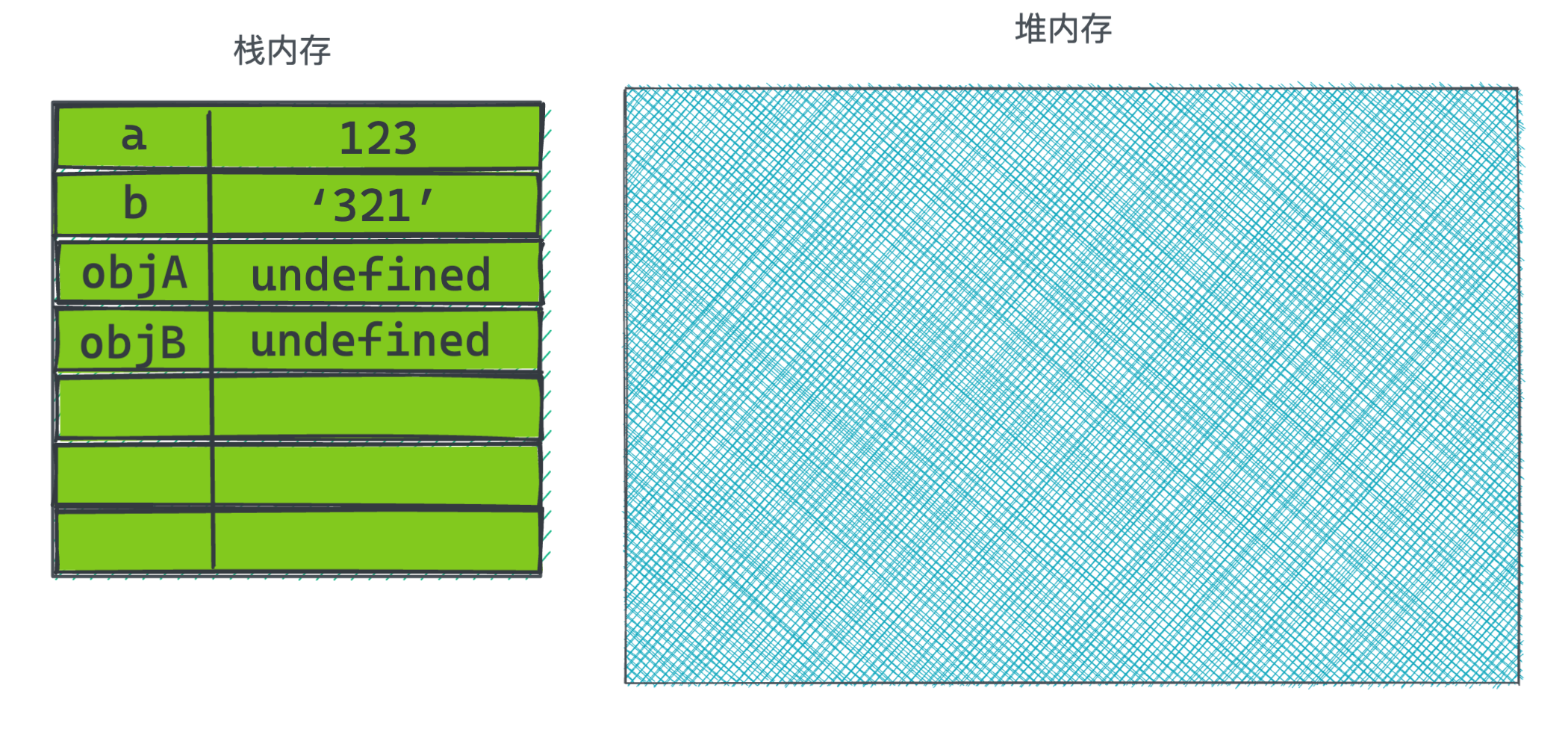
给变量objA赋值是,会在栈内存里保存指向堆内存的地址,堆内存里开辟一块空间用来保存objA对象。
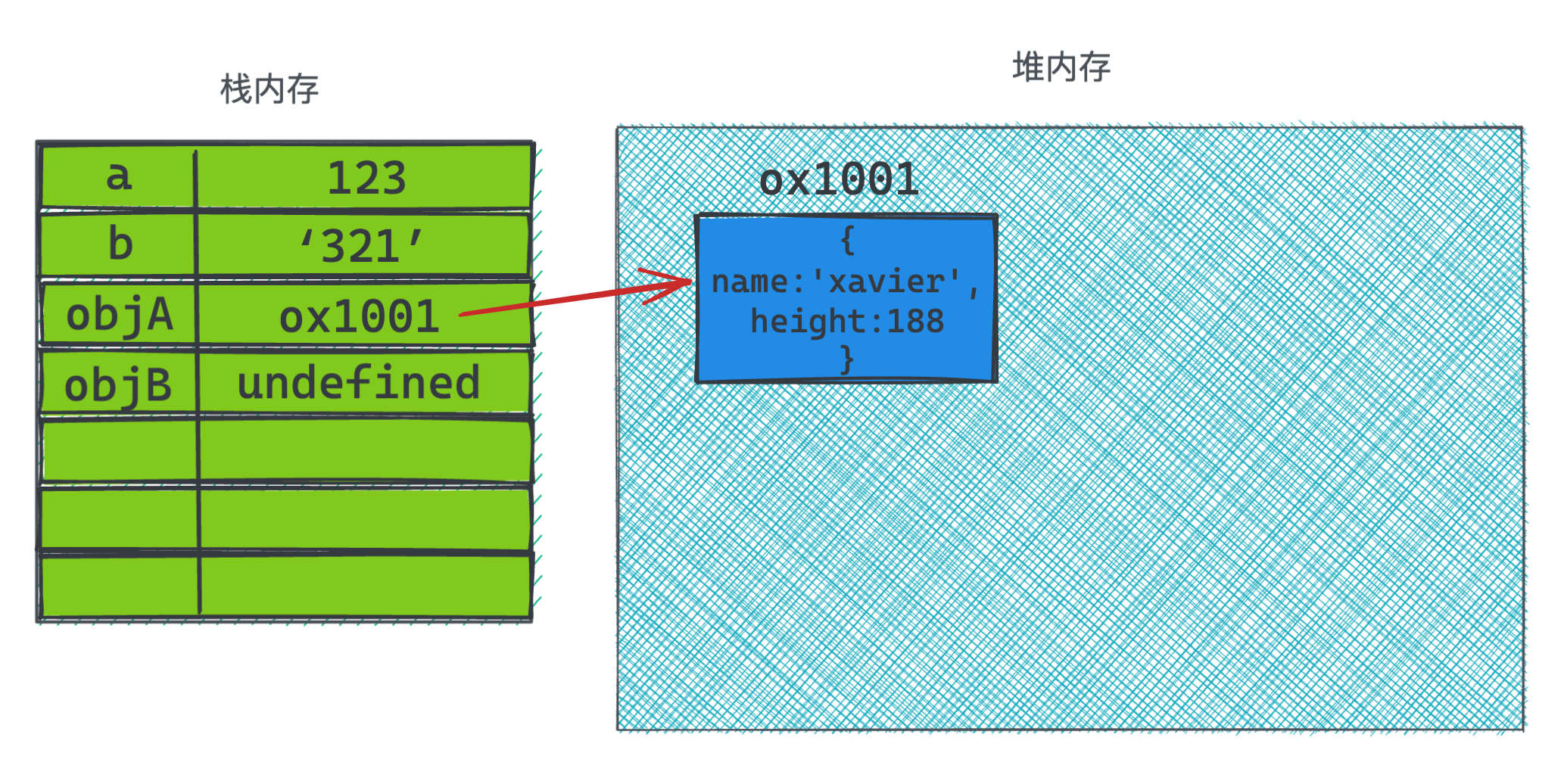
到了变量objB时,由于objB = objA, 此时实际上是将objA的引用地址的值赋值给objB. 所以objB所保存的是指向堆内存中对象的地址值。
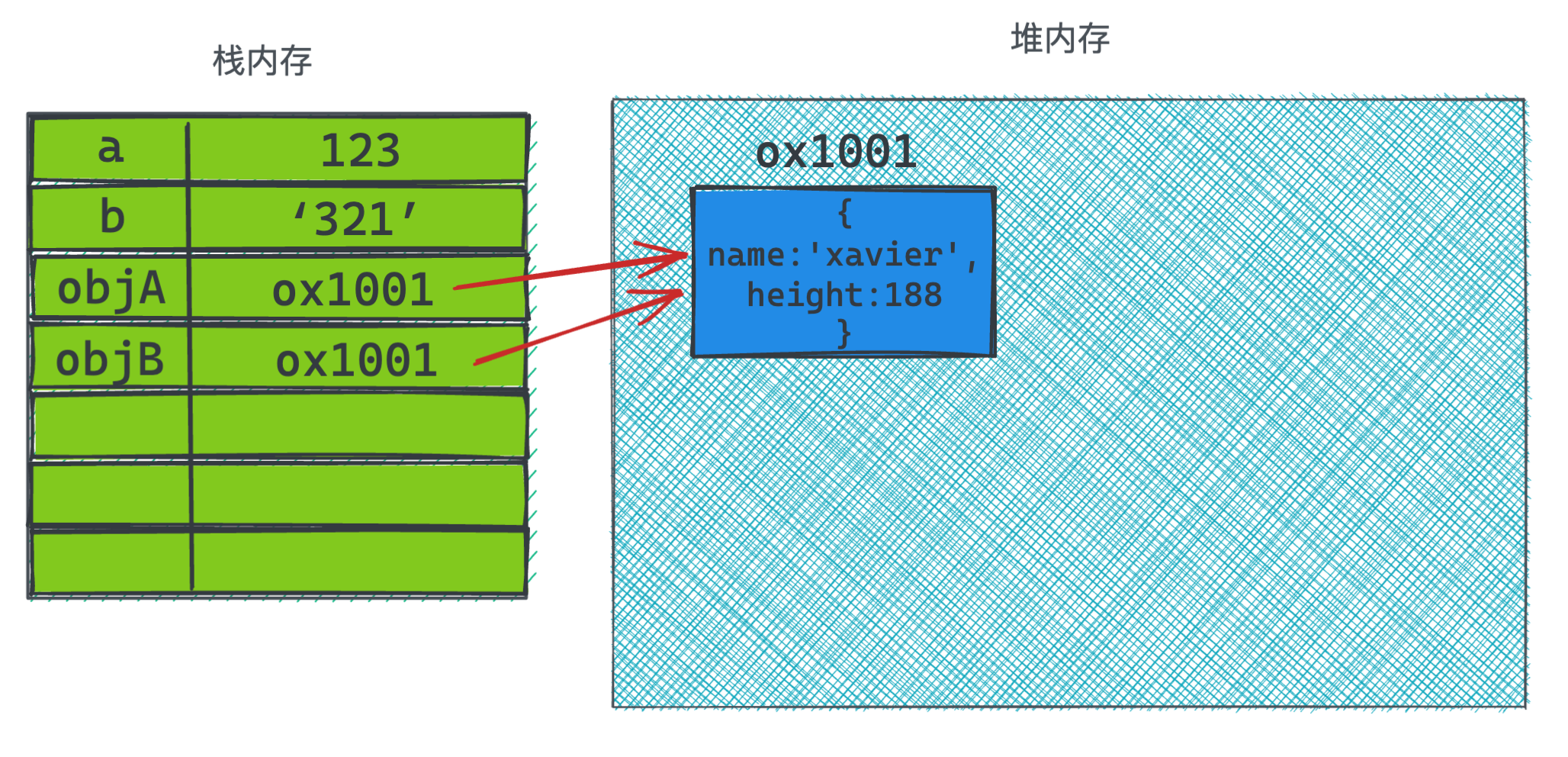
箭头的指向是相同的,所以这就是为什么称为引用类型,不同名称的变量指向的是同一个对象,所以当代码执行修改objB变量名称时,此时如果打印objA.name, 结果也会是修改之后的值。
然后到了最后又给objA指向了一个新的变量,此时内存里的变化就是:
垃圾回收
任何机器的内存都不是无限的,所以不可能在我们代码中不断声明创建新变量和函数时,就一直存放在内存中,而是当不在使用时,就需要进行内存释放,腾出更多的空间以供其他程序使用。 对于js来说,实现这功能的就是垃圾回收机制。
对于如何判定一个变量或方法是否属于垃圾,也就是不在使用的资源时,就需要相应的算法来处理,在js垃圾回收机制中最主要的就是两种算法:
- 引用计数
- 标记清除
1.引用计数
引用计数这名字听起来就知道基本只对引用类型相关了,基本类型在栈内存里是不需要的,当不需要时直接被覆盖或者被销毁了就行。 所以在js中所有引用类型都是对象,因而这算法就是定义,一个对象如果有访问另一个对象,那么就叫做对象引用了另一个对象。 因此如果一个对象没有被其他任何引用给指着, 那么就会被垃圾回收了。
还是用个代码的小例子来解释
var objA = {
name: {
first: 'xavier',
last: 'parker'
},
age: 18
}
objA.name = 'coin'
objA = null
var objB = {}
var objC = {}
objB.d = objC
objC.e = objB
objB = null
objC = null
在代码刚创建执行时,内存里的情况为:
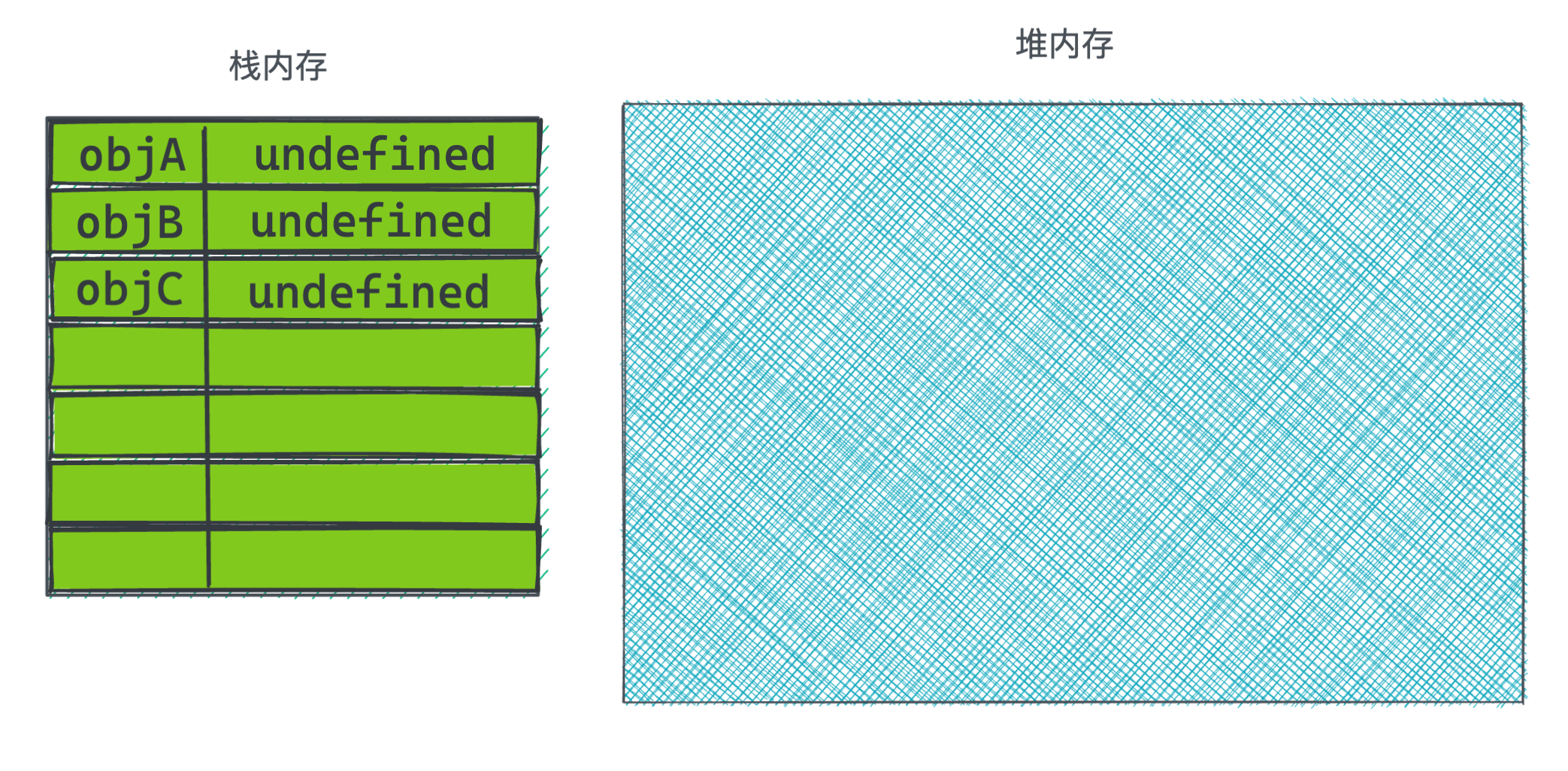
开始执行第一行代码,声明变量objA, 图里的箭头就是所谓的引用。当一个对象被箭头指向时,说明自身是属于被引用状态, 会计数+1。
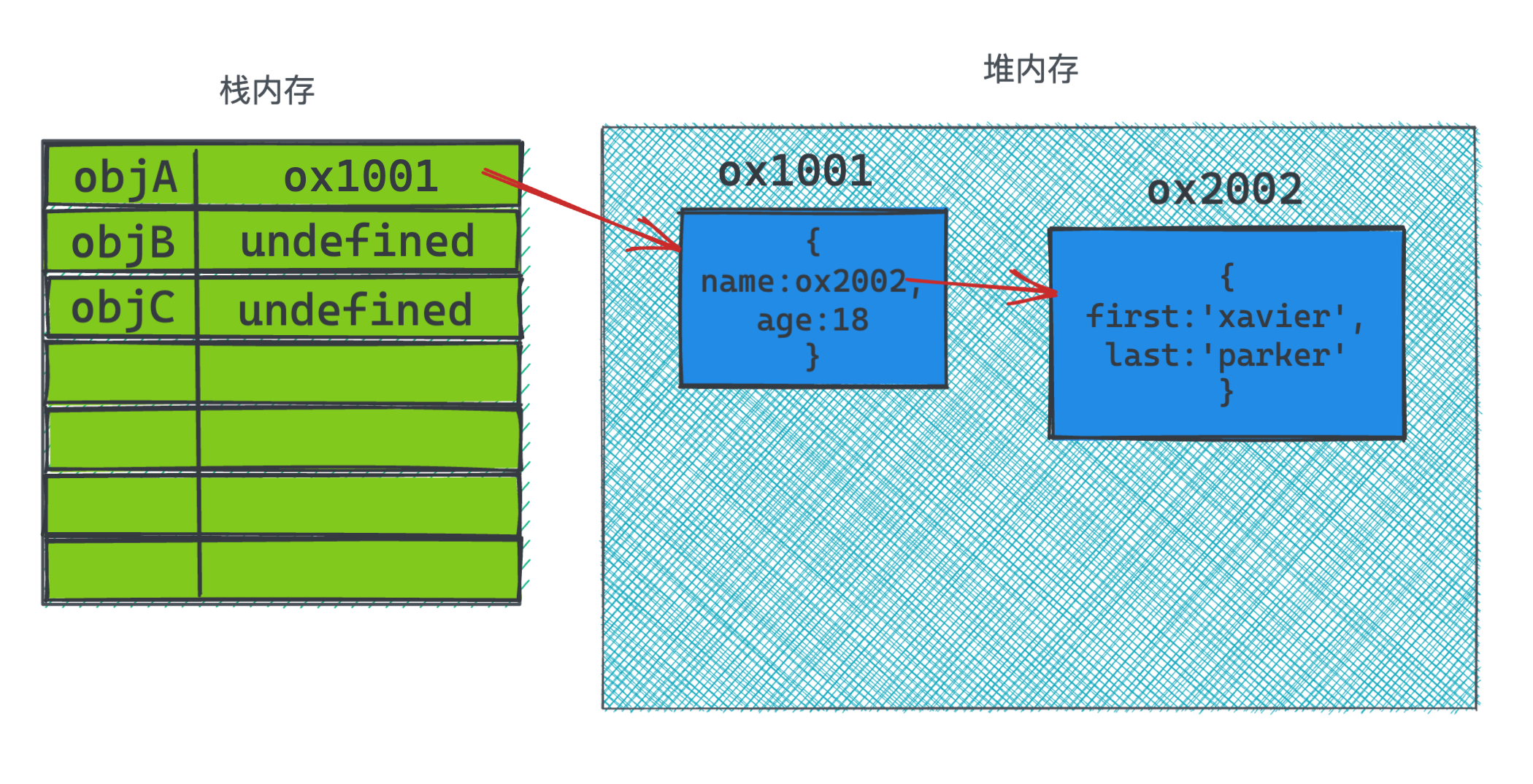
而当代码走到 objA.name = 'coin'时, 此时修改了堆内存里第一个对象的值,因而没有再引用到地址ox2002的对象,该对象不在被任何对象所引用,自身计数变为0。到了一定的时间之后,垃圾回收就会把这个对象给释放了。
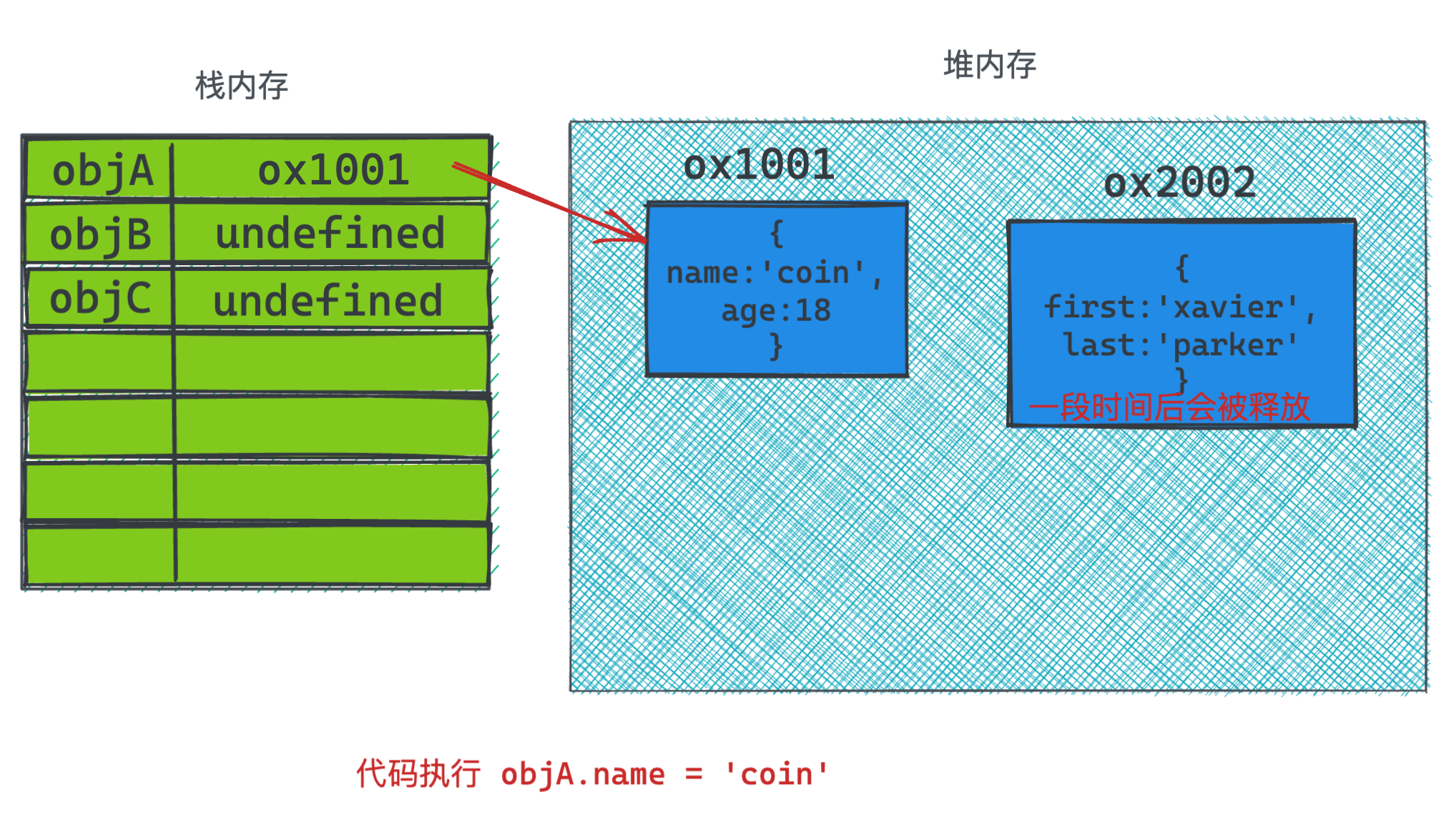
然后当 objA = null执行时, 说明在栈内存里已经为objA赋值为null, 它就不会再指向堆内存。自然ox1001过一段时间也会被释放。
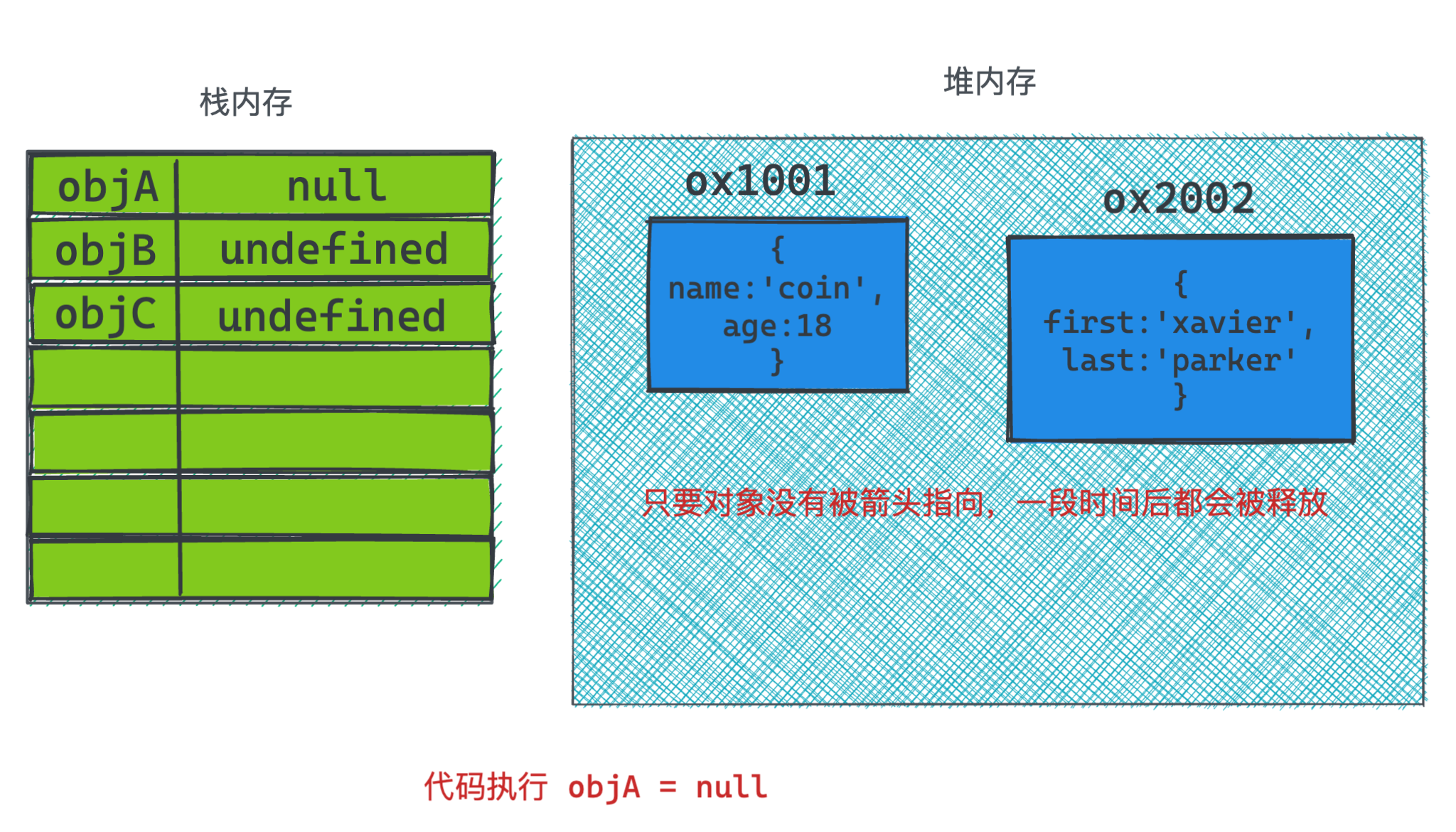
但后续执行的4行代码就是引用计数所无法解决的问题,他们存在互相引用,导致计数值永远没办法变为0,根据引用计数的算法来说,它们就无法被清除。
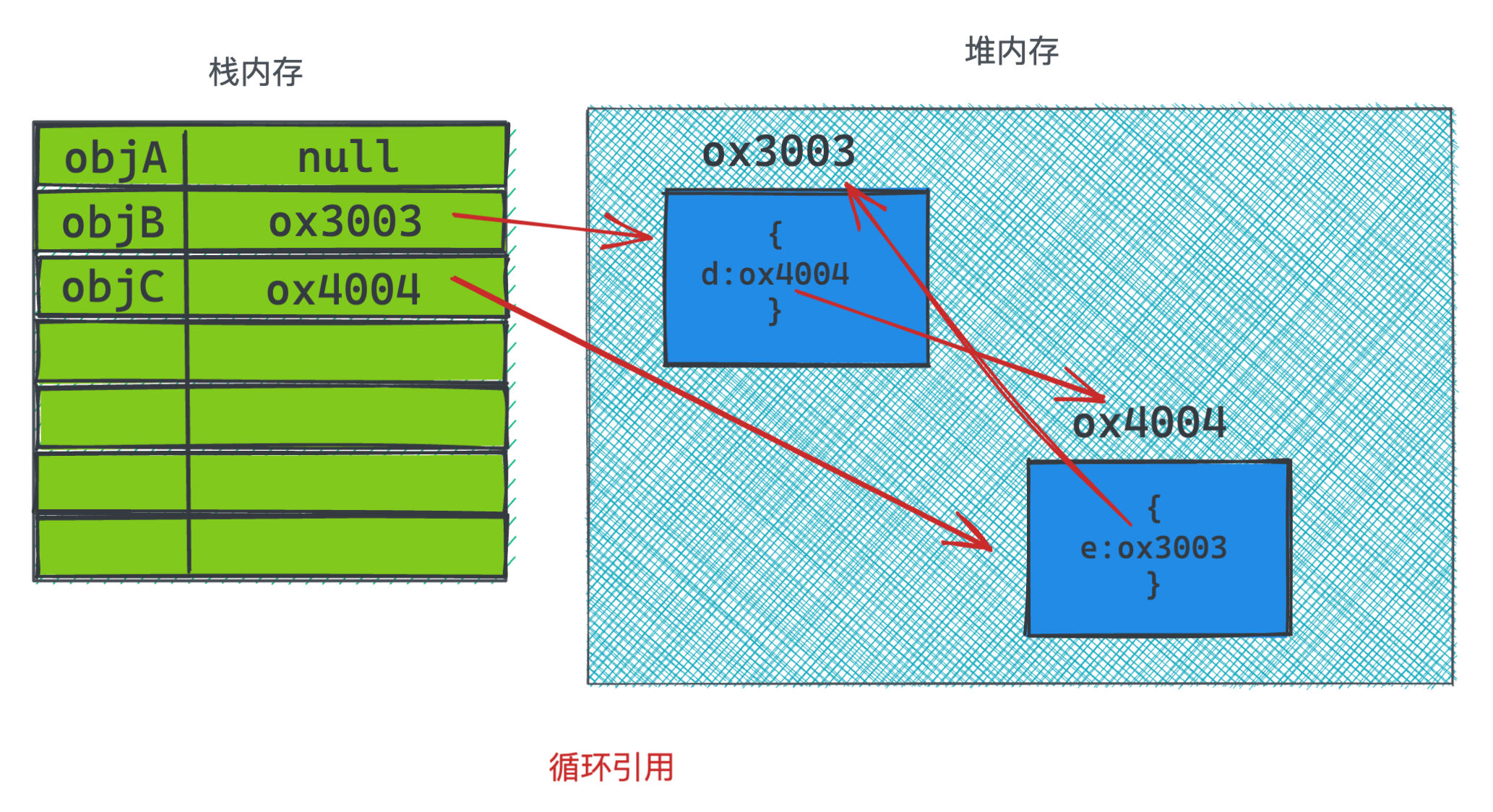
2. 标记清除
标记清除能够解决循环引用的问题,所以在2012年之后,js主要的垃圾回收算法就是以标记清除为主,并且还混合引用计数和其他回收算法一起。
对于标记清除的定义其实也很容易,就是看一个对象是否能从根元素上一路引用被搜寻到,如果可以,那就不清除, 如果不可以,那就清楚。 这里的根元素在js中就是全局对象。
其实根据之前引用计数的图里就很好理解,因为我都是使用var来定义变量,因而它们都挂载在全局对象上, 可以可以默认是根元素。
在以下这图里, 对于内存地址为ox2002的对象,根据根元素objA一路跟着箭头能够被索引到, 所以它就不会在内存中被释放。
而当之后代码修改,不再有箭头指向它时,自然就没有根元素再能跟着箭头搜索到,所以一段时间后就会被销毁。
而对于循环引用来说,在引用计数的算法里,它们是无法被销毁的,但是用标记清除算法,因为已经没有根元素能够指向它们,所以它们俩到了一定时间后就会被双双销毁。
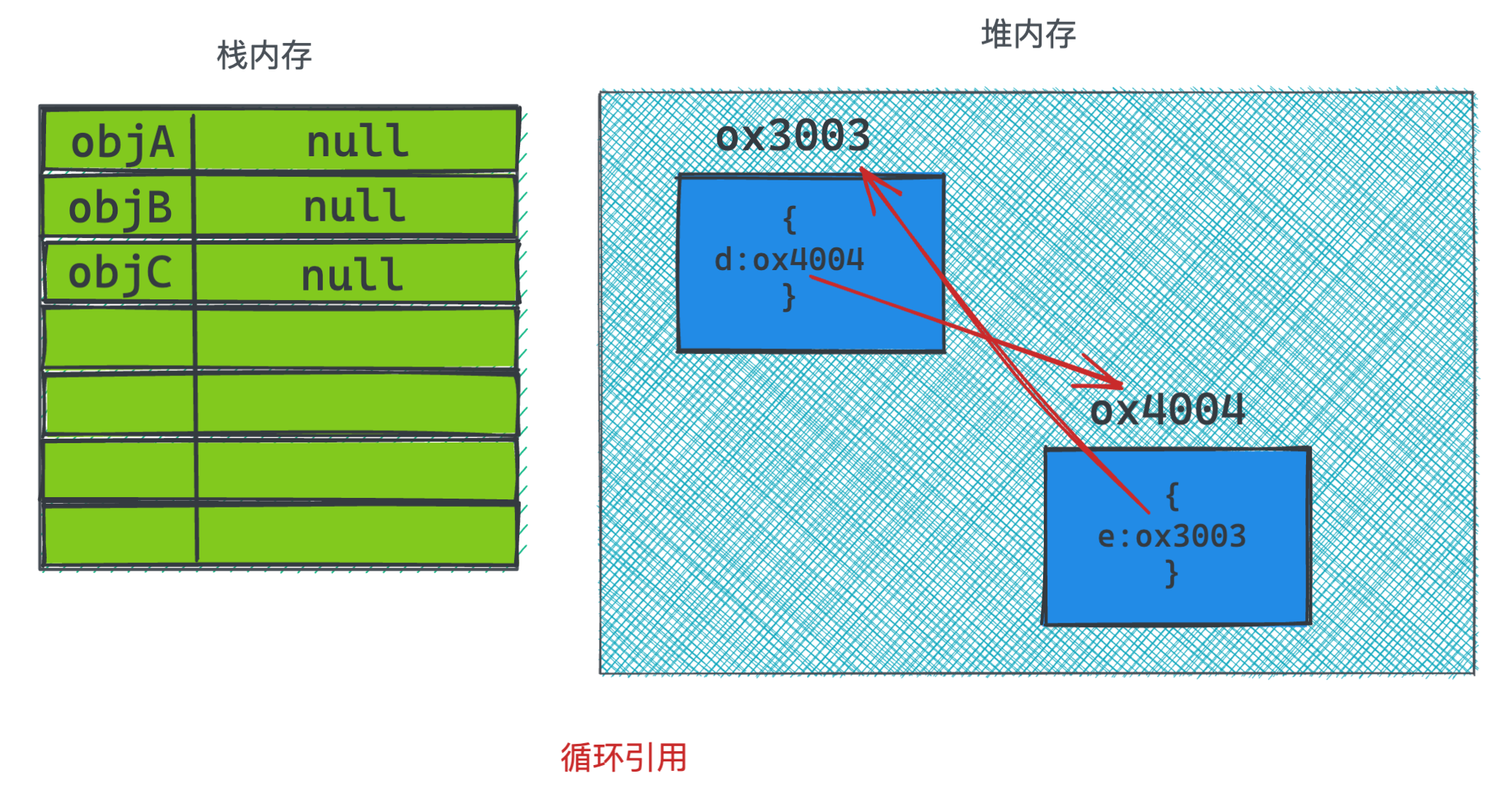
可以看到,图还是这些图,但是通过不同的算法去解释,它就是不同的意思,因为在内存中,它们实际的行为就是类似图中这样,是存在地址引用。 用C语言的话来说就是指针,所以图里是很形象的。
闭包内存泄露
闭包导致的内存泄露其实也很好理解,在之前复习闭包的内容提过,一个函数创建时会有一个隐藏的属性[[scope]],会指向自己的父作用域,但在v8引擎优化下会创建一个Closure对象,里面存的就是父作用域里自身会用到的属性和方法。 如果这个闭包对象一直在内存中没有被释放,那就是产生了内存泄露。
用一个简单的小例子看一下内存一直无法释放的情况:
function foo() {
var arr = new Array(1024 * 1024).fill(1)
return function() {
console.log(arr.length)
}
}
var arrFns = []
for (let i = 0; i < 100; i++) {
setTimeout(() => {
arrFns.push(foo())
}, 100 * i)
}
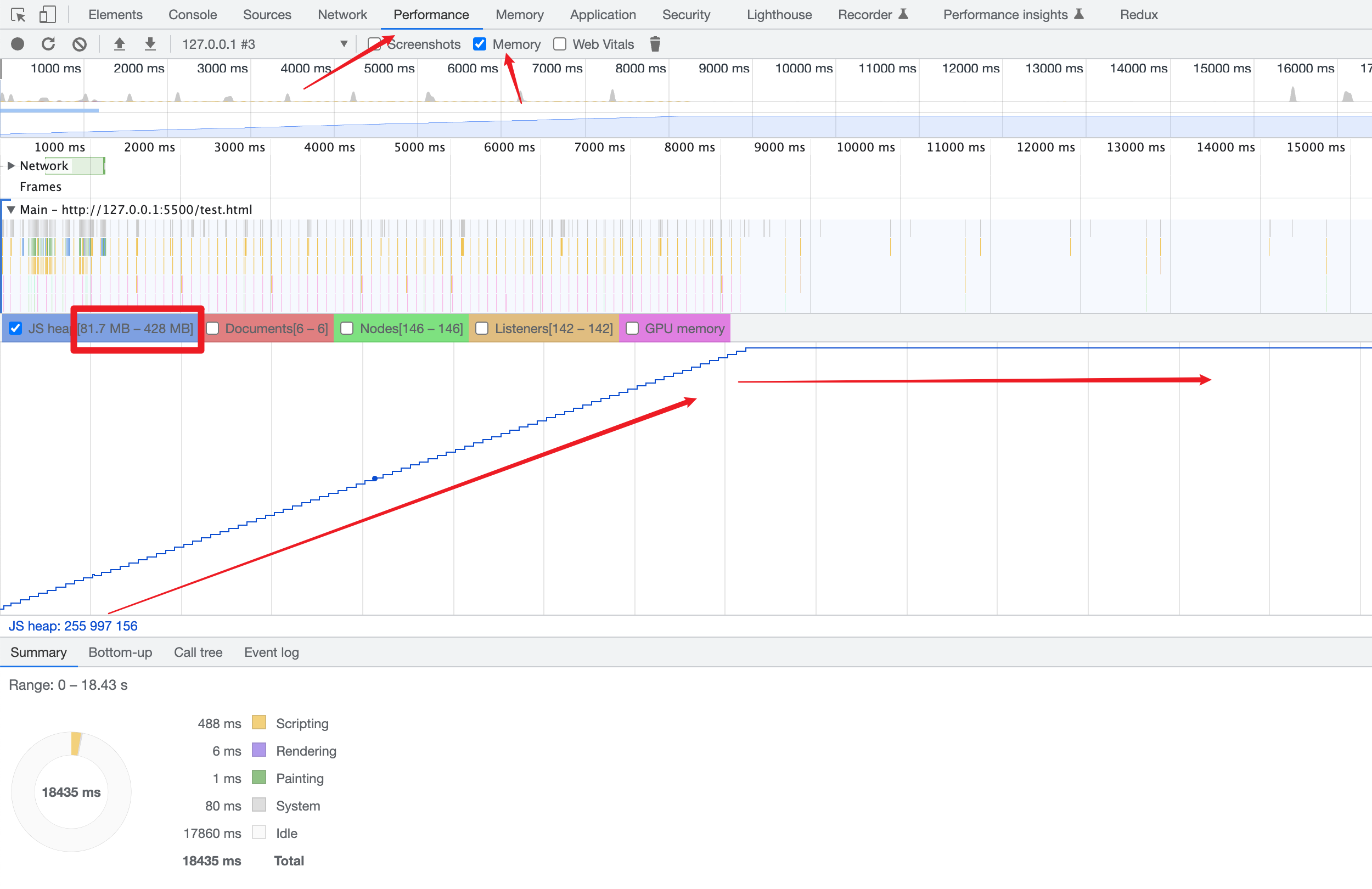
把代码丢到浏览器里执行,打开devTool。 选择Performance, 先执行一次清空缓存并重新加载后点击按钮执行。 差不多记录20秒左右。
最终生成的图例就是下图这样,浏览器里脚本执行时内存不会完全是0,还会有一些其他的操作导致有一小部分内存,所以图里是从81.7m一直增长到428m结束。然后内存中就一直驻留着这400多m内存不会释放, 这种情况下就叫做内存泄露。
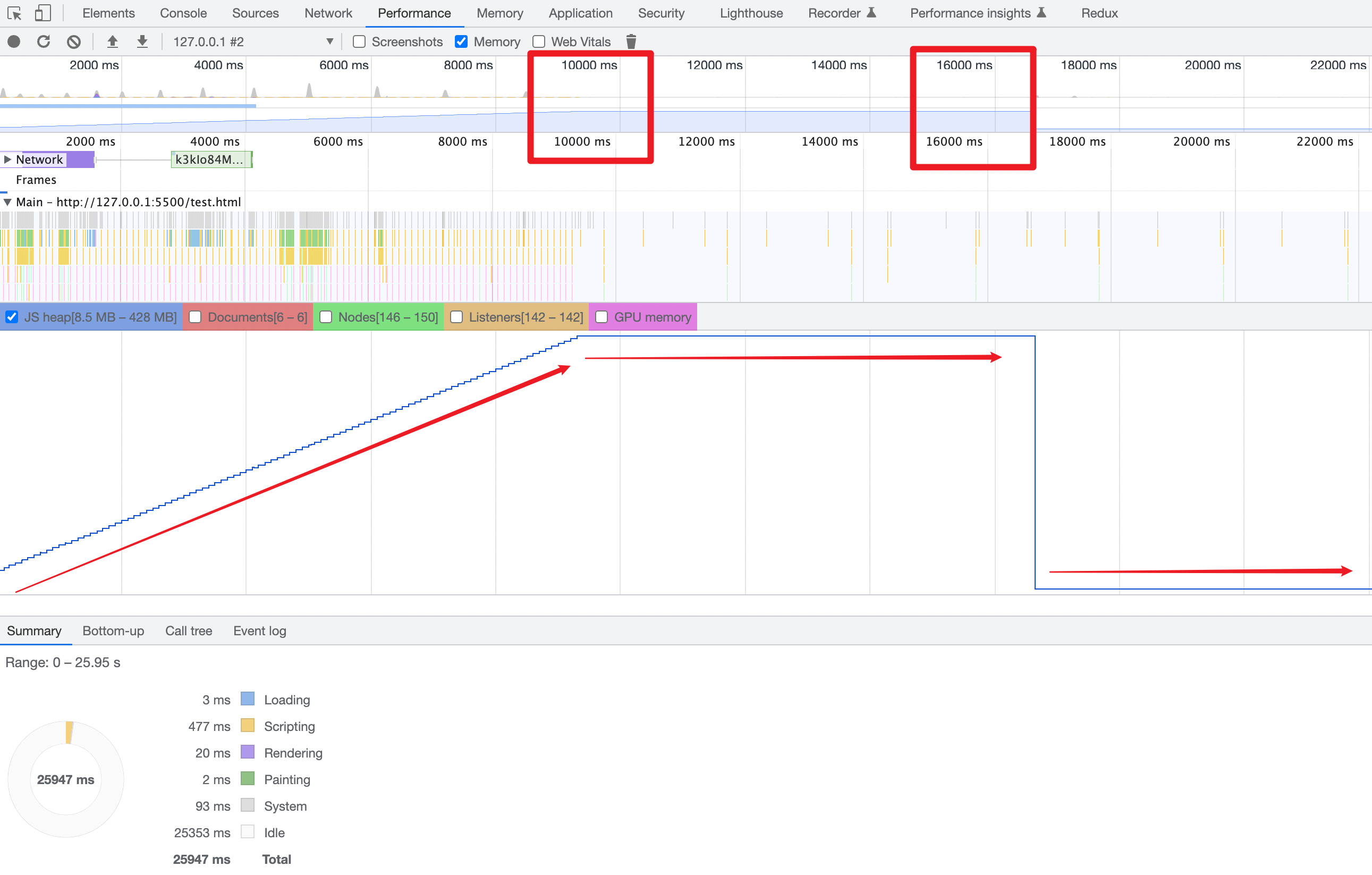
想要释放了也容易,只要在后面设置15秒后arrFns = null即可。
function foo() {
var arr = new Array(1024 * 1024).fill(1)
return function() {
console.log(arr.length)
}
}
var arrFns = []
for (let i = 0; i < 100; i++) {
setTimeout(() => {
arrFns.push(foo())
}, 100 * i)
}
setTimeout(() => {
arrFns = null
}, 150000)
总结
关于内存相关的内容还是很浅略的复习了一些,可以说对任何一门语言来讲,越是了解它在内存之中是如何运作的,越是能够真正掌握这么语言里相关的特性和机制。才能够在写代码时就清晰的知道代码会是怎么运行的,对编写高质量代码有很重要的作用。
上述所有内容只是我自己归纳总结的知识,可能会存在一些错误,如果有看到这篇文章并且知晓错误的地方,恳请指出,一方面帮我纠正谬误,另一方面也免于我误导了其他读者。
