sklearn --笔记
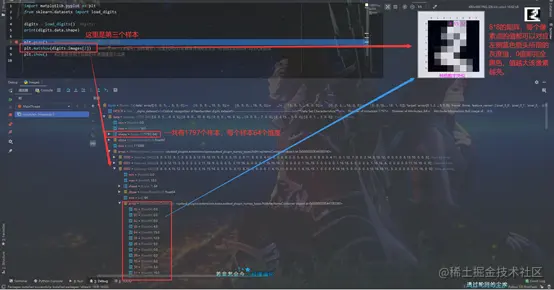
1、测试images.py
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
digits = load_digits()
print(digits.data.shape)
plt.gray()
plt.matshow(digits.images[2])
plt.show()
2、NeuralNetwork.py
import numpy as np
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x) * np.tanh(x)
def logistic(x):
return 1 / (1 + np.exp(-x))
def logistic_deriv(x):
return logistic(x) * (1 - logistic(x))
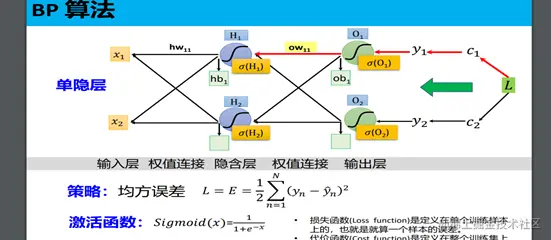
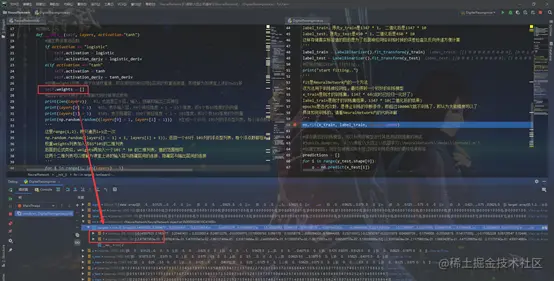
class NeuralNetwork:
def __init__(self, layers, activation="tanh"):
if activation == "logistic":
self.activation = logistic
self.activation_deriv = logistic_deriv
elif activation == "tanh":
self.activation = tanh
self.activation_deriv = tanh_deriv
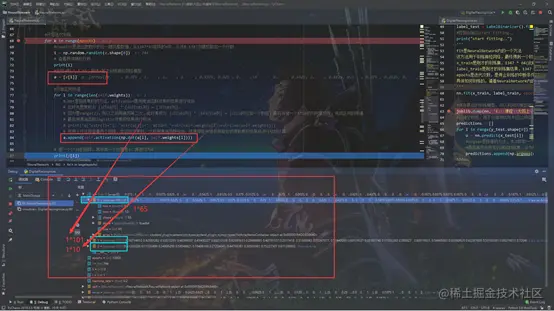
self.weights = []
print(len(layers))
print(layers[0] + 1)
print(layers[1] + 1)
print(np.random.random((layers[0] + 1, layers[1] + 1)))
'''
这里range(1,2),即只遍历l=1这一次
np.random.random((layers[i - 1] + 1, layers[i] + 1)),返回一个65行 101列的浮点型列表,每个浮点数都在0-1之间,具体的计算见下图
权重weights列表加入该65*101的二维列表
后面的公式类似,weights再加入一个101 * 10 的二维列表,值的范围相同
这两个二维列表可以理解为课堂上讲的输入层与隐藏层间的连接、隐藏层与输出层间的连接
'''
for i in range(1, len(layers) - 1):
self.weights.append((2 * np.random.random((layers[i - 1] + 1, layers[i] + 1)) - 1) * 0.25)
self.weights.append((2 * np.random.random((layers[i] + 1, layers[i + 1])) - 1) * 0.25)
def fit(self, x, y, learning_rate=0.2, epochs=10000):
'''
:param x:对应传过来的1347 * 64,内部值均已经归一化0-1
:param y:对应1347 * 10,已经二值化后的结果
:param learning_rate:学习率
:param epochs:迭代次数,也是终止条件
'''
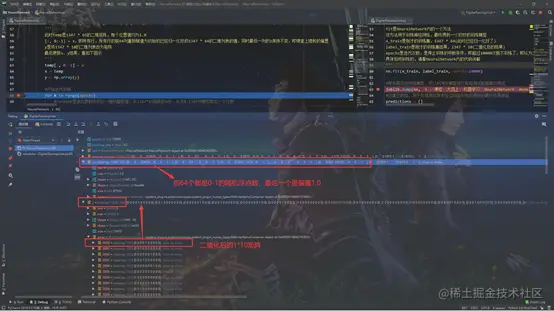
x = np.atleast_2d(x)
temp = np.ones([x.shape[0], x.shape[1] + 1])
'''
此时temp是1347 * 65的二维矩阵,每个位置值均为1.0
[:, 0:-1] = x,即所有行,所有行的前64列重新赋值为初始的已经归一化好的1347 * 64的二维列表的值,同时最后一列的1保持不变,即课堂上提到的偏置
y是将1347 * 10的二维列表改为矩阵
最后更新x、y结果,看如下图示
'''
temp[:, 0:-1] = x
x = temp
y = np.array(y)
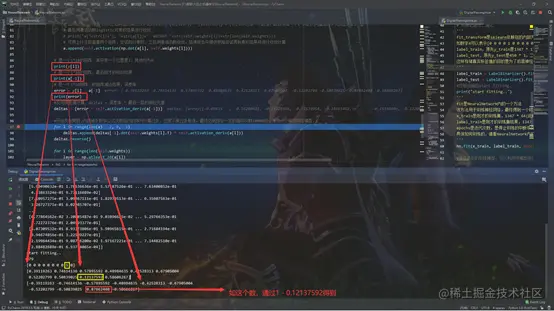
for k in range(epochs):
i = np.random.randint(x.shape[0])
print(i)
a = [x[i]]
for l in range(len(self.weights)):
a.append(self.activation(np.dot(a[l], self.weights[l])))
print(y[i])
print(a[-1])
error = y[i] - a[-1]
print(error)
deltas = [error * self.activation_deriv(a[-1])]
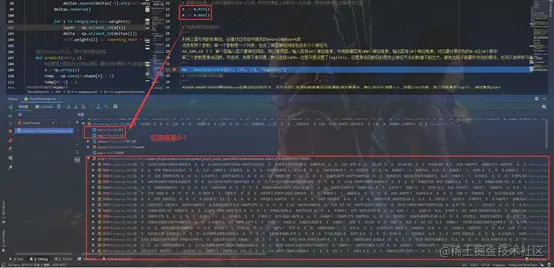
for l in range(len(a) - 2, 0, -1):
deltas.append(deltas[-1].dot(self.weights[l].T) * self.activation_deriv(a[l]))
deltas.reverse()
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)
def predict(self, x):
x = np.array(x)
temp = np.ones(x.shape[0] + 1)
temp[0:-1] = x
a = temp
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return a
3、DigitalReconginize
import joblib
from sklearn.preprocessing import LabelBinarizer
from NeuralNetwork import NeuralNetwork
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
import numpy as np
from sklearn.metrics import confusion_matrix, classification_report
import warnings
warnings.filterwarnings("ignore")
digits = load_digits()
x = digits.data
y = digits.target
x -= x.min()
x /= x.max()
'''
利用上面引用的依赖包,创建对应该包中提供的NeuralNetwork类
该类有两个参数,第一个参数是一个列表,包含了每层神经网络包含多少个神经元
64,100,10 》》 输入层有64个神经维度,中间隐藏层有100个神经维度,输出层有10个神经维度,对应最终要识别的0-9这10个数字
第二个参数是激活函数,可选项,如果不做设置,默认选择tanh。这里只是设置了logistic,设置激活函数目的是防止神经节点的数值不能过大,避免出现不能最终收敛的情况,也可以加快学习速度【注意logistic不是取对数】。
'''
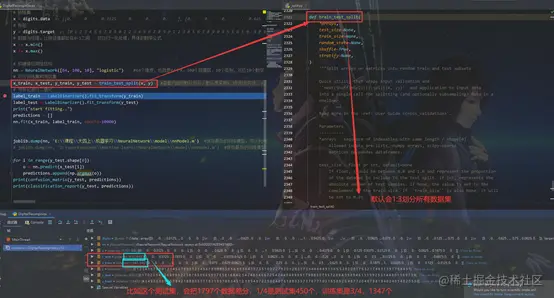
nn = NeuralNetwork([64, 100, 10], "logistic")
'''
train_test_split是sklearn依赖包的内部方法,该方法可以将原始数据集将训练集和测试集差分,默认拆分比例是3:1,按照1797总数,所以训练集有1347个,测试集有450个
x_train是训练集的所有影像维度和,即1347 * 64;x_test是测试集所有影像维度和,即450 * 64;
y_train是训练集的所有真实标签和,即1347 * 1;y_test是测试集的所有真实标签和,即450 * 1;
'''
x_train, x_test, y_train, y_test = train_test_split(x, y)
'''
fit_transform是sklearn依赖包的内部方法,该方法可以将某一具体数值进行二值化存储。
如数字4可以表示[0 0 0 0 1 0 0 0 0 0];1可以表示为[0 1 0 0 0 0 0 0 0 0]
label_train,原先y_train是1347 * 1, 二值化后是1347 * 10
label_test,原先y_test是450 * 1,二值化后是450 * 10
这样存储真实标签值的目的是为了后面神经网络训练时候的误差检查及反向传递方便计算
'''
label_train = LabelBinarizer().fit_transform(y_train)
label_test = LabelBinarizer().fit_transform(y_test)
print("start fitting..")
'''
fit是NeuralNetwork内的一个方法
该方法用于训练神经网络,最终得到一个较好的训练模型
x_train是刚才的训练集,1347 * 64(此时已经归一化好了)
label_train是刚才的训练集结果,1347 * 10(二值化后的结果)
epochs是迭代次数,是停止训练的中断条件,即超过10000次就不训练了,即认为大致精度可以了
具体如何训练的,请看NeuralNetwork内的代码详解
'''
nn.fit(x_train, label_train, epochs=10000)
predictions = []
for i in range(y_test.shape[0]):
o = nn.predict(x_test[i])
predictions.append(np.argmax(o))
'''
用测试数据集的预测标签和该样本的本身真实标签做对比
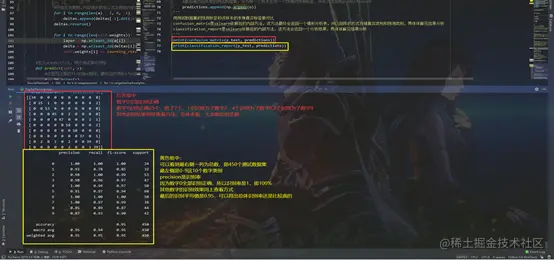
confusion_matrix是sklearn依赖包的内部方法,该方法最终会返回一个情形分析表,并以矩阵的方式存储真实类别和预测类别,具体详解见结果分析
classification_report是sklearn依赖包的内部方法,该方法会返回一个分析结果,具体详解见结果分析
'''
print(confusion_matrix(y_test, predictions))
print(classification_report(y_test, predictions))