

以下是一些你可以发现你的数据处理工作太慢的方法。
- 工作在遇到超时时开始被杀死。
- 客户开始抱怨工作缓慢或失败。
- 你的云计算账单是上个月的两倍。
虽然这些通知机制确实有效,但最好不要依赖它们。当工作顺利完成,客户满意,而你的预算中又有大量剩余资金时,生活会更轻松。
这意味着你要在情况变得如此糟糕之前识别出意外的缓慢或高内存使用率。你越早发现性能问题,你就能越早解决它们。
那么,你如何识别你的数据管道或工作流程中的低效率任务呢?让我们来了解一下
从 "总是慢 "到 "有时慢"
我们将专注于数据处理任务,通常作为一个更大的工作流程或管道的一部分运行;这包括数据科学、科学计算和数据分析。每个工作的运行时间都有一个特定的结构。
- 加载一些数据作为输入。
- 以某种方式处理或分析输入,创建一个输出。
- 存储输出结果,之后工作或任务就结束了。
当你第一次开始执行这类长期运行的任务时,你可以合理地认为你的代码是低效的。因此,首先,你可以随机地对作业进行剖析,最好是在生产中,并使用剖析结果来识别你的代码太慢的地方,或使用太多的内存。你可以修复瓶颈,再次测量,反复进行,直到最终你创造了一个足够高效的基线。
这就是情况变得更加复杂的地方。
在这一点上,大多数工作都很快,但偶尔也会很慢。也许是因为环境的原因,也许是因为不同的输入会产生不同的行为。不管是什么原因,解决根本问题的第一步是识别出异常值的具体作业:那些运行速度比预期慢的作业。
你如何识别这些慢的异常值?一种方法是使用日志记录,这是你可能想要做的事情,以帮助调试和诊断。
用日志对性能进行建模并识别异常值
我们可以使用日志来解决性能问题,使用四步流程。
- 在你的程序中添加日志,最好是基于追踪的日志。
- 使用记录的信息来建立作业速度的模型。
- 这个模型可以帮助你识别异常值。
- 检查异常值,以确定和解决这个问题。
步骤1.增加日志记录,这是必要的,但不是充分的
为了看看日志在识别过慢的任务方面如何有用,我将使用基于跟踪的日志,简称跟踪,这是一种优越的日志形式。具体来说,我将使用由许多服务和工具支持的OpenTelemetry标准,并且我将在可能的情况下使用Honeycombability平台来实现数据的可视化。在实践中,你可以使用其他服务和/或正常的记录,仍然可以得到类似的结果,只是难度不同而已。
注意:Honeycomb很不错,但这个用例并不是它的主要重点。如果你有关于追踪观察性服务的建议,而这些服务是为数据处理工作设计的更好的,请告诉我吧
让我们从一个例子开始,一个程序加载一个文本文件,过滤掉一些我们不关心的词,然后把这些词写到一个JSON文件中。
import sys
import json
def to_words(text):
return [word.lower() for word in text.strip().split()]
def load_filter_words(filterwords_path):
with open(filterwords_path) as f:
return to_words(f.read())
def remove_filter_words(filter_words, countwords_path):
result = []
with open(countwords_path) as f:
for line in f:
for word in to_words(line):
if word not in filter_words:
result.append(word)
return result
def main(filterwords_path, countwords_path, output_path):
filter_words = load_filter_words(filterwords_path)
result = remove_filter_words(
filter_words, countwords_path
)
with open(output_path, "w") as f:
json.dump(result, f)
if __name__ == "__main__":
main(sys.argv[1], sys.argv[2], sys.argv[3])
接下来,让我们用OpenTelemetry添加一些跟踪。与普通日志不同的是,OpenTelemetry使用有开始和结束的跨度来追踪执行情况,而普通日志是一系列孤立的事件。跨度可以有子跨度,形成一个跨度树,而且跨度可以有附加属性。在OpenTelemetry API中,跨度可以使用装饰器或上下文管理器来添加。
@tracer.start_as_current_span("myspan")
def f():
# ...
def g():
with tracer.start_as_current_span("myspan2"):
# ...
如果每个跨度在其上下文中被调用,就会自动嵌套在一个父跨度中。
在下面的例子中,注意任务的不同步骤--加载、处理和输出数据--都有自己的跨度。我们还确保将输入文件的大小和过滤词的数量记录为属性。
# ...
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.http.trace_exporter import (
OTLPSpanExporter,
)
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
TRACER = trace.get_tracer("example")
# ...
@TRACER.start_as_current_span("load_data")
def load_filter_words(filterwords_path):
# ...
@TRACER.start_as_current_span("process_data")
def remove_filter_words(filter_words, countwords_path):
# ...
def main(filterwords_path, countwords_path, output_path):
# Initialize tracing:
provider = TracerProvider()
processor = BatchSpanProcessor(OTLPSpanExporter())
provider.add_span_processor(processor)
trace.set_tracer_provider(provider)
with TRACER.start_as_current_span("main") as span:
span.set_attribute(
"input_size", os.path.getsize(countwords_path)
)
filter_words = load_filter_words(filterwords_path)
span.set_attribute(
"filter_words_count", len(filter_words)
)
result = remove_filter_words(
filter_words, countwords_path
)
with TRACER.start_as_current_span("output_data"):
with open(output_path, "w") as f:
json.dump(result, f)
# ...
现在我们可以设置一些环境变量,当我们运行任务时,跟踪信息将被发送到Honeycomb。
$ python v2-with-tracing.py short-filter.txt middlemarch.txt output.json
下面是一个在Honeycomb用户界面中显示的单次运行的跨度树的例子;我们可以看到,在这个例子中,处理数据花费了大部分时间,其次是加载数据。
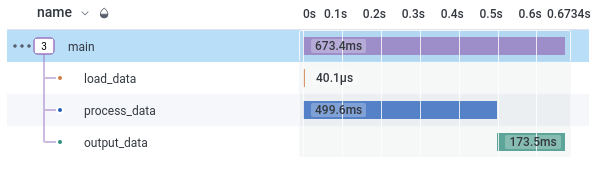
对于每个跨度,我们有一些属性;那些我们明确记录的属性,还有一些标准属性,包括跨度运行的时间:duration_ms 。通过对HEATMAP(duration_ms) ,查询名称为"main" (即顶级跨度)的跨度,我们可以看到不同的任务花费了不同的时间(Y轴)。X轴是任务开始的时间。
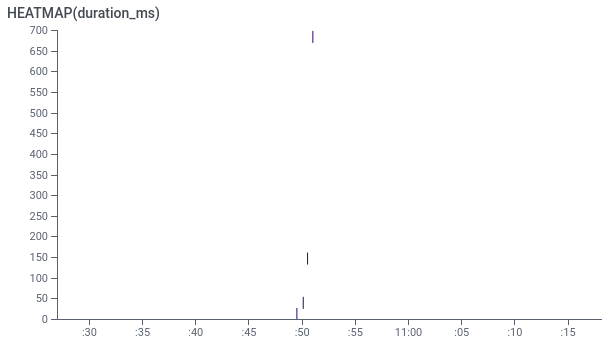
因为我们想找到缓慢的异常值,所以我们要关注那些在Y轴上比较高的任务。例如,有一个任务花了700ms,相比之下,下面那些快得多的任务最多只花了150ms。但是,这个700ms的任务真的是一个异类吗?
**困难在于,运行时间部分是由输入大小决定的。**在我们的例子中,正如通常的情况一样,输入规模越大,运行时间就越长。如果你有一个较小的输入,任务会运行得更快。
下面是AVG(duration_ms) ,按输入大小分组的"main" 跨度;你可以看到,输入大小越大,跨度的时间就越长。

有时你可能会认为这些较慢的任务仍然算作离群值,在这种情况下,你可以继续进行第4步,解决这个问题。但是在较大的输出上运行得更慢往往是预期的、正常的行为。这意味着你希望有一种寻找离群值的方法,将输入大小考虑在内。
第2步。根据输入大小对预期运行时间进行建模
既然我们在记录输入大小,我们可以想出一个简单的模型。
- 我们的文本文件中的字数越多,我们预计它的运行时间就越长。
- 我们记录的是文件大小,它与字数不完全相同,但高度相关。
- 从我们对代码的理解和对上表的观察来看,运行时间很可能与字数或文件大小成线性关系。
- 因此,我们期望
duration_ms / input_size,这将是相当恒定的;任何比率高得多的都是异常值。
Honeycomb允许你添加"衍生列",基本上是从现有的属性中计算出一个新的属性。在这种情况下,我们可以添加一个名为duration_to_input 的列,定义为DIV($duration_ms, $input_size) 。
现在,如果我们建立一个表格,将AVG(duration_to_input) 与input_size 进行比较。

在这一点上,输入大小不是duration_to_input 变化的原因,而且值的范围要小得多:最大的值只有1.5×最小的值,而以前我们看到的是两个数量级的范围。因此,这似乎是一个合理的性能模型;并不完美,但这没关系。
由于微小的数字比较难读,我们可以尝试将其规范化一些,用平均值除以0.000075 。我们将把公式改为duration_ms / (input_size * 0.000075) ,或者在Honeycomb的系统中改为DIV($duration_ms, MUL($INPUT_SIZE, 0.000075)) 。

注意:如果你想更系统地做这件事,你可以用SciPy来建立一个更精确的数学模型。为了获得原始数据,Honeycomb让你把查询结果下载为CSV。
第3步。识别异常值
在这一点上,我们可以说,如果duration_to_input ,大约是0.7-1.3,我们面对的是一个正常的结果。如果数值明显变高,比如说1.5或更高,我们可以认为是一个异常值。
让我们看一个例子。
$ python v2-with-tracing.py long-filter.txt romanempire.txt output.json
AVG(duration_to_input) 如果我们看一下Honeycomb,特别是看一下trace.trace_id ,所以我们可以看到单个运行,我们看到这个运行要慢得多。而且关键的是,即使在调整了输入大小之后,它也慢了很多。
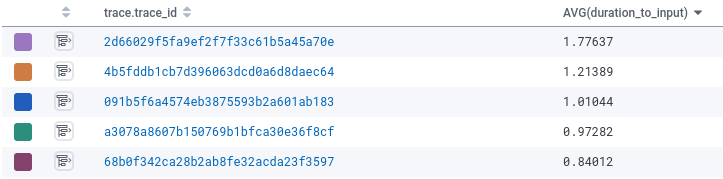
新运行的比率为1.77,远远高于其他任何工作。我们发现了一个异常点!
当然,手动查询并不是发现异常值的最好方法。一旦你对模型感到满意,并对正常范围有了一定的认识,你可能希望在异常值出现时得到自动通知。Honeycomb有一个叫做"触发器 "的功能,当某些标准被满足时就会通知你;其他工具也应该有类似的功能。
第四步。修复通过异常值发现的错误和/或调整模型
使用Honeycomb的用户界面进行更多的调查(使用BubbleUp工具将异常值与基线进行比较,或者只是阅读跟踪属性),发现这个异常值有不同的词数需要过滤掉。之前我们使用的是30个词(short-filter.txt ),这次我们使用了174个词(long-filter.txt )。
看来,性能不仅与被过滤的文本文件中的字数有关,就像我们最初假设的那样,而且还与过滤字数有关。
**这是一个性能错误,还是我们应该调整我们的模型以考虑到过滤词的数量?**在这种情况下,这可能是一个错误。如果我们使用字典或集合,检查一个字符串是否包含在其他字符串的集合中,应该是一个快速、相当恒定的O(1) 操作。
这就说明了错误的原因:我们使用了一个列表来表示filter_words ,所以每个词的查找都是O(N) ,而不是O(1) 。这很容易解决,虽然我不会在这里展示,但结果是一切都开始运行得更快。
一旦我们实现了这个修复,所有的工作都会运行得更快,所以我们需要调整duration_to_input 模型。但是,我们不需要让模型变得更复杂,只需要用不同的常数来调整它,以考虑到更快的基线性能。
在其他情况下,修复可能不那么系统化,同样的性能模型可以继续保持不变。
用剖析法诊断性能问题
在这种情况下,代码足够短,源代码加上跟踪信息就足以确定问题。在现实世界的代码中,这往往要困难得多。这就是剖析的用武之地,它是对你从日志中获得的信息的一种补充:你真的希望在生产中默认开启剖析。
**如果在生产中持续进行剖析,每当你发现一个缓慢的标识符,你就可以立即获得剖析信息。**例如,Sciagraph性能观察性SaaS是专门为Python数据处理任务设计的。下面是它对这次运行的显示。
它直接将你指向if word not in filter_words: ,因为大部分时间都花在这一行。
识别内存使用的异常值
到目前为止,我们一直在对性能运行时间进行建模。但是你可能还想识别那些使用过多内存的作业,这可能会导致交换,或者被Linux的内存不足杀手杀死。而这意味着客户投诉、作业失败,以及潜在的高云计算成本。
为了支持寻找高内存使用量的异常值,我们基本上遵循完全相同的过程,只是我们不使用duration_ms 或其他一些衡量耗时的方法,而是需要使用衡量内存使用量的方法。有两种基本的方法可以测量内存,但无论哪种方法,我们都希望得到峰值内存,因为这是硬件资源方面的瓶颈所在。
选项1:峰值常驻内存(RSS)
峰值常驻内存可以使用Python resource模块;然后你可以把它作为一个属性添加到顶层跨度中。
from resource import getrusage, RUSAGE_SELF
with TRACER.start_as_current_span("main"):
# ...
max_rss = getrusage(RUSAGE_SELF).ru_maxrss
span.add_attribute("max_rss", max_rss)
然而,正如在其他地方详细解释的那样,这种测量方法受到可用内存的限制,而且不能再高了。如果你的机器上只有8GB的内存,你将永远看不到超过8GB的内存;一个试图分配8GB、16GB或32GB的程序将报告相同的最大常驻内存,这可能是一种误导。
选项2:分配的内存峰值
另外,你可以测量程序所要求的峰值内存量。这也有问题,例如,mmap() ,只是懒洋洋地分配,所以不清楚是否应该计算,直到它变脏。另一方面,这将告诉你程序实际要求的数量,无论可用的内存是多少。
除了性能分析外,Sciagraph还将在生产中对你的工作分配的内存使用情况进行分析。它与OpenTelemetry集成,确保分配的内存峰值也被记录在您的日志/跟踪系统中。
另外,如果你在做离线剖析,你可以使用Fil或Memray进行分配内存剖析,但它们在生产中不被设计为默认开启。
你需要日志记录!
正如我们在文章开头所说,你希望客户满意,并在你的银行账户中留下大量的钱。这就要求你有足够快的工作。当你刚开始使用一些新的代码时,你可以简单地。
- 对代码进行剖析,最好是在生产中。不需要找到异常值,只需随机挑选一个作业。
- 识别瓶颈。
- 修复缓慢的地方。
然而,最终,正常情况下的速度会足够快,你会想要识别缓慢的标识符。这就是日志的用处;你可能已经有了某种日志,用于调试目的。你也可以使用日志记录你的工作的运行时间性能,并在此基础上识别缓慢的异常值。
你不需要使用Honeycomb来这样做,也不需要使用OpenTelemetry。我确实希望有一天会有专门为更大规模的批处理作业和数据管道设计的日志服务(如果它们真的存在,请告诉我!)。但是,即使有Python的内置 logging在运行结束时记录一条信息,包括经过的时间和输入的大小,真的非常容易。
重要的是,要有一些方法来查询所产生的日志并提取适当的记录。你还需要一些方法来获得异常值的自动通知。然后,每当你发现异常值时,你就可以看看你的日志,看看你的剖析,并立即开始修复性能和内存问题--如果幸运的话,在你的客户注意到之前。
