

本文已参与「新人创作礼」活动, 一起开启掘金创作之路。
1.缓存的定义
缓存: 数据交互的缓冲区域,有存储和缓冲的作用,提升性能。
更快读写的存储介质+减少IO+减少CPU计算=性能优化
2.缓存的作用
1》降低系统的响应时间、减少网络传送时间和应用延时时间,进而提高了系统的吞吐量,增加了系统的并发用户数量。
2》有效的减少底层关键组件如核心应用、数据库等的压力。在高并发下有效的减轻系统的负荷。
3》提升应用的性能、稳定性和可用性。
削峰:减少数据库的QPS
屏蔽耗时操作:缓存耗时对象的创建,比如某些代理对象,线程池,savepoint等
容器: 本地缓存 单例池
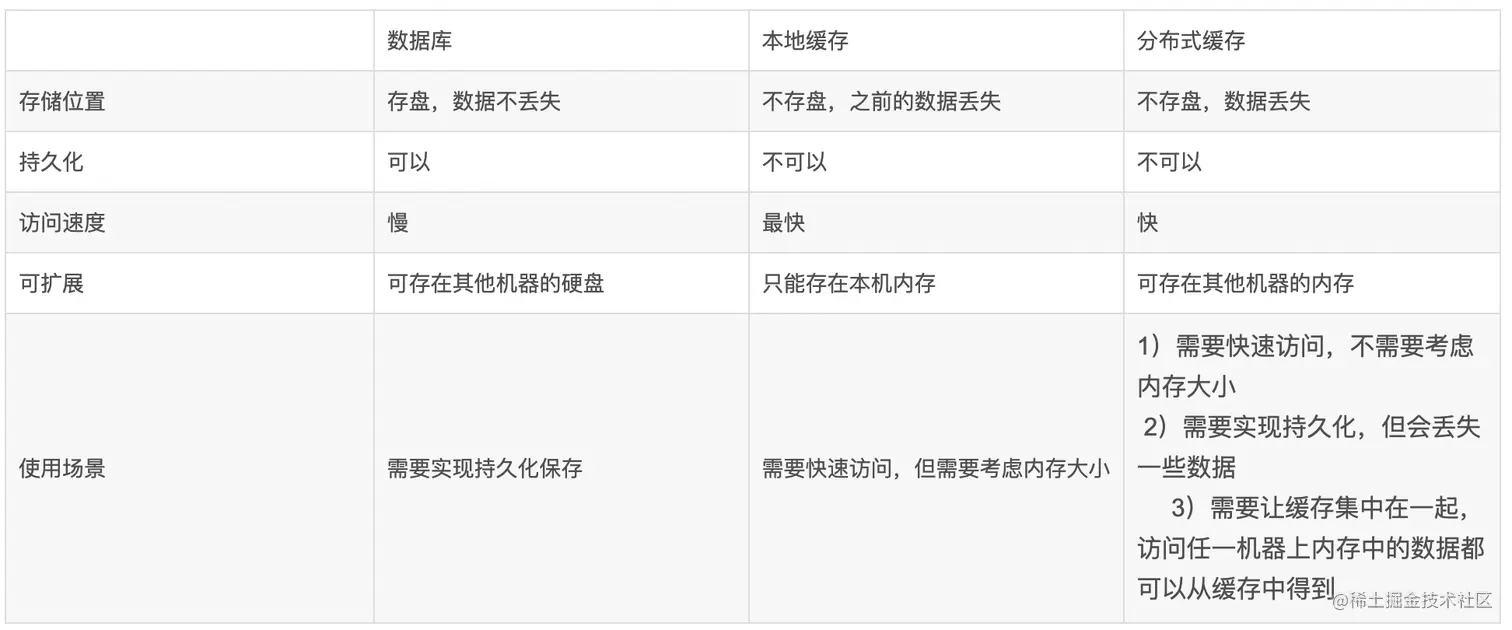
3.缓存对比
 4.缓存的应用场景
4.缓存的应用场景
本地缓存(内存):程序自带的集合对象:map list,存放的数据不能太多,还需要考虑刷新机制
在程序中,有些表数据,数据很少,但是程序加载的时候要马上访问,并且访问的很 频繁,比如(例如系统配置参数,区域信息),针对这种情况,将数据放到程序的本地缓存中即内存中,从而提升系统的访问效率,减少数据库访问,数据库访问要占用数据库连接,同时网络消耗比较大,但同时要注意,缓存的占用空间、缓存的失效策略。
缓存组件: 分布式缓存
5.缓存带来的问题
数据的一致性、实时性受影响。(需要对数据的一致性,时效性进行评估,进而确定是否要缓存或设定缓存的过期时间)在一定程度上会牺牲数据的强一致性,如何保证高可用性和数据强一直性就要根据业务场景做出衡量(CAP理论)
缓存介质带来的不可靠性。(一般使用内存做缓存的话,若机器故障,如何保证缓存的高可用?可考虑对缓存进行分布式做成高可用,同时,需要接受这种不可靠不安全会给数据带来的问题,在异常情况下进行补偿处理,定期持久化等方式)
进程内缓存可能会增加GC压力:在具有垃圾收集功能的语言中(如Java),大量长寿命的缓存对象会增加垃圾收集的时间和次数。
缓存组件的备份
一般要求:
- 读密集型的应用
- 存在热点数据的应用
- 对响应时效要求较高的应用
- 对一致性要求不是很严格的场景
6. 案例分享
6.1缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
6.2 缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
- 设置热点数据永远不过期。
- 加互斥锁
6.3 缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。 hash一致性算法
- 设置热点数据永远不过期。
6.4 缓存一致性问题
Cache aside也就是旁路缓存,是比较常用的缓存策略。先更新数据库,再删除缓存。
先更新数据库 再更新缓存:
先删缓存,再更新数据库
先更新后删除:
但我们仔细想一下,上述问题发生的概率其实非常低,因为通常数据库更新操作比内存操作耗时多出几个数量级,上图中最后一步回写缓存(set age 18)速度非常快,通常会在更新数据库之前完成。
如果这种极端场景出现了怎么办?我们得想一个兜底的办法:缓存数据设置过期时间。通常在系统中是可以允许少量的数据短时间不一致的场景出现。
