

作为一个与现实世界数据打交道的数据科学家,在你的职业生涯中的某个时候,你会面临在不平衡数据上建立机器学习模型的困难。你需要在几个问题上做出明智的决定,比如选择适当的措施来保证你的模型在小类中得到足够的训练。
本文将向你介绍Python中的imbalanced-learn模块,并向你展示它最经常使用的两个案例,以帮助你开发一个准确的、信息丰富的模型。
Python中的Imbalanced-learn模块
Imbalanced-learn是机器学习中用来处理不平衡数据集的一个Python包。在一个不平衡的数据集中,数据样本的数量并不是均匀地分布在各个类中。不平衡数据集中的类标签是不平等的。一个类标签的数据样本数量比另一个类标签大得多。
例如,假设你要根据各种输入特征来预测一个学生是通过考试还是失败。在这个例子中我们有两个类名:通过 和不通过。
纳入的方法分为四类。
- 过度取样。
- 低度取样。
- 过度取样和不足取样的混合。
- 集合学习方法。
在这篇文章中,我们将重点讨论过度取样的方法。
过度取样
过度取样(有时也被称为上升取样)是低度取样的逆反。在这种情况下,拥有较少数据的类被认为等同于拥有较多数据的类。这是通过向样本最少的类添加额外的数据来实现的。因此,比例将是1:1和平衡的。
重抽样技术是处理倾斜数据的最有效方法之一。Python不平衡学习模块提供了许多重采样算法和实现,包括两种最有用的技术。SMOTE 和ADASYN。
SMOTE和ADASYN
合成少数人过采样技术(SMOTE)和自适应合成(ADASYN)是两种过采样方法。这些方法同样产生了很少的样本,然而,ADASYN考虑了分布的密度,将数据点均匀地分散开来。
前提条件
你应该了解以下内容。
- Python编程基础
- 机器学习的入门知识
- Pandas 的基本概述
安装Imbalanced-Learn
让我们运行下面的命令来安装它。
sudo pip install -U imbalanced-learn
这就是全部!Imbalanced-learn已经安装完毕,可以开始使用了。现在让我们加载我们的不平衡数据集。
SMOTE
对少数人类别的实例进行过度采样,例如,简单地重复少数人类别的实例,是克服这个问题的一种技术。这种方法没有给模型提供更多的信息。生成合成实例将是一个更好的方法。
SMOTE (Synthetic Minority Oversampling Technique),是一种流行的为少数群体产生合成实例的方法。
它的操作方法如下。
- 从少数群体中随机选取一个代表。
- 确定该实例的k(通常是k=5)个最近的邻居。
- 从这些邻居中随机选择一个样本。
- 在这两个例子之间画一条线。
- 通过在该线上随机选择一个点,构建一个虚构的例子。
现在你将看到如何实现不平衡学习模块。 由于这个数据集是严重不平衡的,它将提供一个很好的示范集。
下载数据集后,你会发现它包括28个匿名的特征,以及时间、数量和类别。
import pandas as pd
data = pd.read_csv("creditcard.csv")
data.head()
将这些特征放在X阵列中,标签放在Y阵列中。
X = data.drop('Class', axis=1)
y = data['Class']
现在将使用SMOTE对小类进行超额取样,使数据集中的两个类得到平衡。
from imblearn.over_sampling import SMOTE
oversample = SMOTE()
X_smote, y_smote = oversample.fit_resample(X, y)
现在,这些类是平衡的,如下图所示。
X_smote = pd.DataFrame(X_smote)
y_smote = pd.DataFrame(y_smote)
y_smote.iloc[:, 0].value_counts()
现在让我们做一个训练-测试分割。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X_smote, y_smote, test_size=0.2, random_state=0
)
import numpy as np
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
然后,训练和测试一个基本分类器,如下图所示。
from sklearn import tree
clf = tree.DecisionTreeClassifier()
clf.fit(X_train, y_train)
最后,看一下性能。
from sklearn.metrics import confusion_matrix
import seaborn as sns
y_pred = clf.predict(X_test)
cm2 = confusion_matrix(y_test, y_pred.round())
sns.heatmap(cm2, annot=True, fmt=".0f")
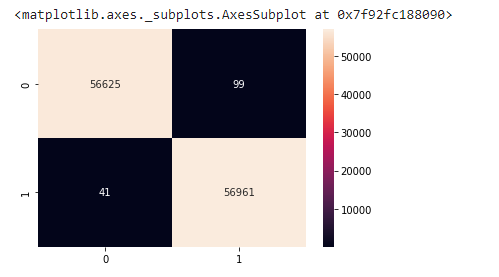
正如你所看到的,使用SMOTE可以确保分类器提供普遍平衡的分类,而不是像失败的模型那样,分类器可能把所有的数据都归类为属于多数类。
SMOTE实现了样本的生成。然而,这种过度取样的方法对基础分布没有了解。因此,可能会产生一些有噪声的样本,例如,当不同的类不能被明确区分的时候。
低度采样的方法将有助于清除这些噪声样本。Imbalanced-learn包括两个随时可以使用的采样器。SMOTETomek和SMOTEENN。
ADASYN
SMOTE的概念由ADASYN扩展。特别是,ADASYN挑选少数民族样本S的方式是 "更难归类 "的少数民族样本更有可能被选中。
这为分类器提供了额外的机会来学习困难的案例。ADASYN的代码与SMOTE的代码相同:只需将 "SMOTE "替换为 "ADASYN"。
from imblearn.over_sampling import ADASYN
oversample = ADASYN()
X_adasyn, y_adasyn = oversample.fit_resample(X, y)
from sklearn.metrics import confusion_matrix
import seaborn as sns
y_pred = clf.predict(X_test)
cm2 = confusion_matrix(y_test, y_pred.round())
sns.heatmap(cm2, annot=True, fmt=".0f")
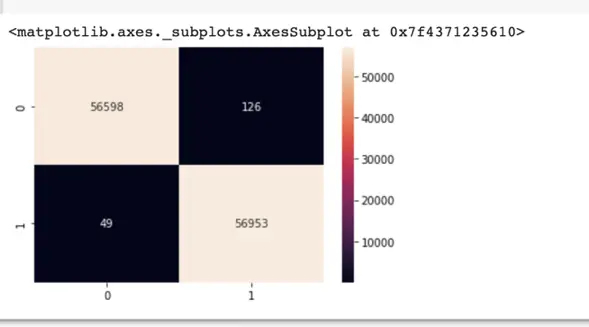
最后的思考
我们在本文中讨论了imbalanced-learn包。我们经历了imbalanced-learn模块的安装过程,并考察了处理不平衡数据集的几种技术。
能够自信地处理不平衡数据的问题是数据科学家的一项宝贵技能。imbalanced-learn库为你提供了必要的工具。
