

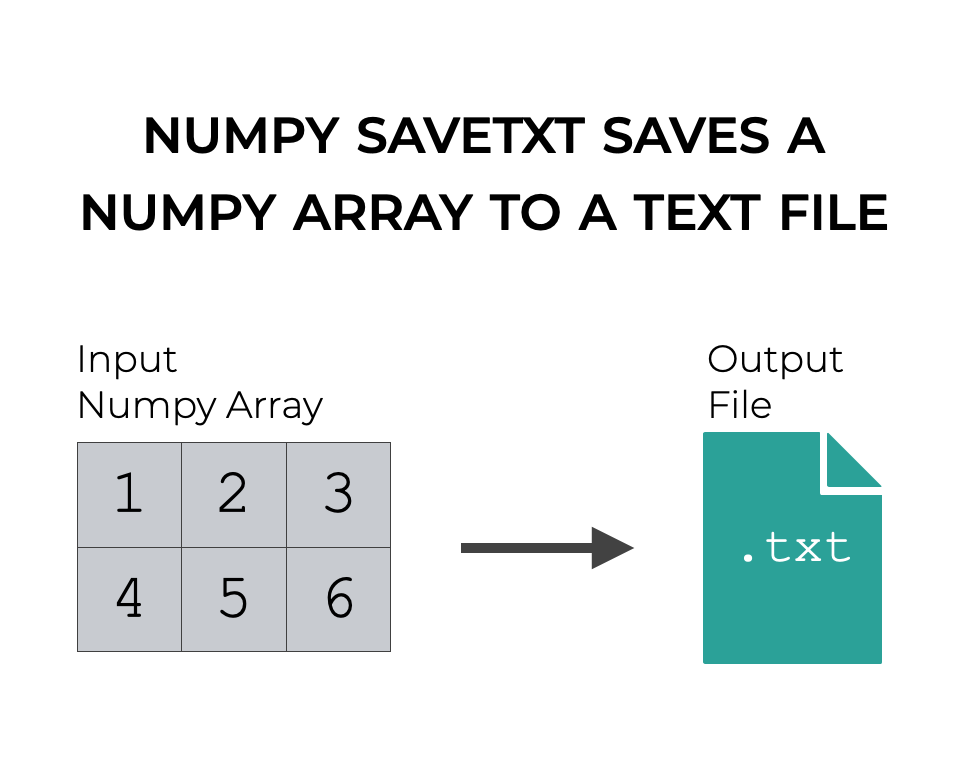
本教程将告诉你如何使用Numpy savetxt将你的Numpy数组保存到文本文件中。
本教程解释了该函数的作用,解释了语法,并展示了如何使用np.savetxt的分步例子。
Numpy Savetxt的快速介绍
你可能已经知道,Numpy savetxt是Numpy包中的一个函数。
Numpy有多种工具用于在Python中创建、重塑、聚合和其他处理数字数据。
但是在你处理完你的数据后,你有时需要把它保存为适合长期存储或传输给其他人的格式。
这就是Numpy savetxt出现的地方。
Numpy savetxt使你能够将Numpy数组保存到一个文本文件中。
然而,关于这个函数有相当多的细节是取决于语法的。
因此,让我们快速了解一下Numpy savetxt的语法。
Numpy Savetxt的语法
在这一节中,我们将看一下np.savetxt的语法。
我们将从高层次上看它是如何工作的,但我们也会看一些可选参数。
一个快速的说明
在我们进入语法之前,我想提醒你一个细节。
每当我们使用一个 Python 包时,我们需要先导入该包。
在 Numpy 的例子中,我们通常用下面的代码来做这件事。
import numpy as np
这很重要,因为当我们像这样导入Numpy时,它使我们能够以'np'为前缀调用Numpy函数。
换句话说,我们究竟如何导入Numpy将稍微改变语法,因为它改变了我们为Numpy命名空间使用的前缀。
我只是想提醒你这一点,因为在未来,我将假设你已经像我在上面的代码中那样导入了Numpy。
np.savetxt的语法
在高层次上,Numpy savetxt的语法很简单。
假设你已经像我上面解释的那样导入了Numpy包,你可以将该函数输入为np.savetxt 。
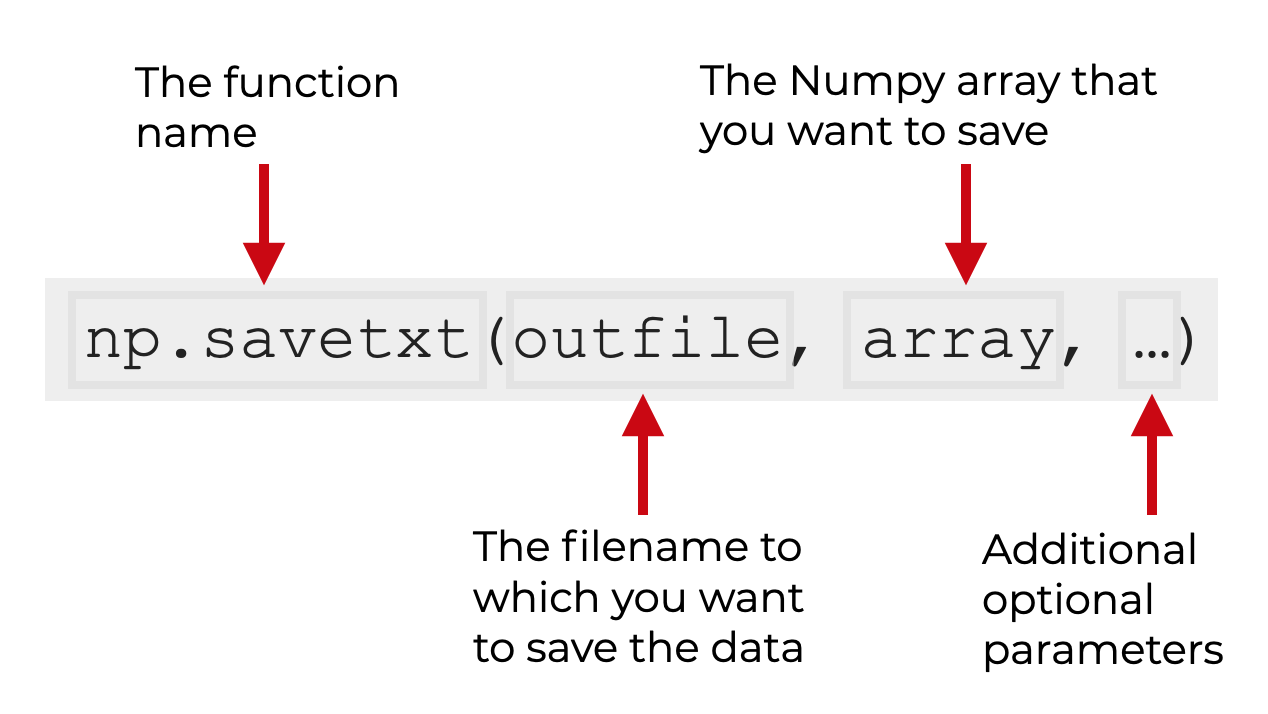
该函数的第一个参数是你想用于输出文本文件的文件名。
第二个参数是你想要保存的Numpy数组。
然后,还有一些你可以使用的可选参数,这些参数将修改函数的具体工作方式。
Numpy Savetxt的参数和输入
Numpy savetxt有几个参数和可选参数。
filenamearrayfmtdelimiternewlineheaderfootercommentsencoding
让我们一次看一下它们中的每一个。
filename (必填)
filename 参数是Numpy savetxt的第一个输入。
如上所述,这是输出文件的名称。
重要的是,这个参数只作为一个位置参数工作。这意味着np.savetxt()函数假定该函数的第一个输入是输出文件的名称。
注意,如果你提供的名称以.gz 结尾,Numpy savetxt将自动以压缩格式保存该文件。
array (必填)
array 参数是你要保存的数据。
最常见的是,输入将是一个Numpy数组。
然而,从技术上讲,np.savetxt 将接受任何 "类似数组 "的对象。 因此,你也可以提供一个Python列表或类似数组的对象,而不是Numpy数组。
fmt
fmt 参数使你可以指定你想在保存的文本文件中使用的数据格式。
这有几个选项,包括。
- 使用科学符号
- 指定数字是整数还是浮点数
- 指定有效数字的数量
- 等等
格式可以变得相当复杂,因为它们使用一种迷你语言来指定所有的细节。
delimiter
定界符参数允许你指定一个定界符,以分隔保存的文本文件中的各列。
默认情况下,它被设置为delimiter = ' ' ,它将用一个空格来分隔各列。
另外,你也可以使用另一个字符,如逗号,这也很常见。
我将在例子部分向你展示一个例子。
newline
newline 参数允许你指定一个特定的字符串,指定输出文件中的新行。
默认情况下,它被设置为newline = '\n' 。
如果你将其设置为其他字符或字符串,该字符串将被包含在文件中,而不是一个新行。
header
header 参数允许你在输出文件的顶部添加一些文本,作为文件头。
footer
footer 参数允许你在输出文件的底部添加一些文本,作为页脚。
comments
comments 参数允许你指定一个字符,它将出现在页眉和页脚文本的前面,以显示该文本是一个注释。
默认情况下,这被设置为comments = '# ' 。
encoding
encoding 参数允许你指定用于编码文本文件的编码。
默认情况下,这个参数被设置为encoding = None ,它使用latin1编码。
如何使用Numpy Savetxt的例子
现在我们已经看了语法和参数,让我们看看Numpy Savetxt的一些例子。
例子
- 将一个Numpy数组保存到一个文本文件中
- 在输出的文本文件中使用一个特定的分隔符
- 在输出的文本文件中使用一个特定的格式
- 在输出的文本文件中添加一个页眉和页脚
- 在输出文本文件的页眉/页脚中使用一个特定的字符来指定注释
- 改变 "换行 "字符
先运行这段代码
在你运行这些例子之前,你需要先运行一点设置代码。
具体来说,你需要
- 导入Numpy
- 创建Numpy数组
让我们一次完成这些。
导入Numpy
首先,你需要导入Numpy。
你可以用这段代码来做。
import numpy as np
记住,这允许我们调用Numpy函数,前缀为np 。
创建Numpy数组
接下来,我们将创建一个Numpy数组,可以在我们的例子中使用。
具体来说,我们将使用Numpy数组函数来手动创建一个包含数字1到6的二维numpy数组。
my_array = np.array([[1,2,3],[4,5,6]])
然后让我们把它打印出来。
print(my_array)
输出
[[1 2 3]
[4 5 6]]
这是一个简单的二维数组,我们可以用np.savetxt() ,将其保存到一个文本文件中。
例子1:保存一个Numpy数组到一个文本文件中
这里,我们将从一个非常简单的例子开始。
我们将简单地把我们的Numpy数组数据保存到一个文本文件中,并且我们将使用所有可选参数的默认值。
让我们看一看。
np.savetxt('my_numpy_data.txt', my_array)
如果你在你的电脑上找到输出文件,你应该能够用文本编辑器(例如Mac上的TextEdit,或Windows上的记事本)来检查它。
下面是保存的文本文件中的样子。
1.000000000000000000e+00 2.000000000000000000e+00 3.000000000000000000e+00
4.000000000000000000e+00 5.000000000000000000e+00 6.000000000000000000e+00
你会看到,数字数据被存储为文本格式,采用科学符号,列与列之间有空格,每行有新行。
这是默认的行为。 我们将在接下来的几个例子中改变其中的一些细节。
例子2:在输出的文本文件中使用一个特定的分隔符
接下来,我们将使用一个特定的分隔符来分隔输出文本文件中的各列。
你会注意到,在上一个例子中,默认情况下,各列是由空格分隔的。
在这里,我们将改变这一点,使各列由逗号分隔。
要做到这一点,我们将使用delimiter 参数。
让我们看一看。
np.savetxt('my_numpy_data.txt', my_array, delimiter = ',')
现在,在你的电脑上找到这个文本文件,用一个文本编辑器(例如Mac上的TextEdit,或Windows上的记事本)打开它。
下面是保存的文本文件的内容。
1.000000000000000000e+00,2.000000000000000000e+00,3.000000000000000000e+00
4.000000000000000000e+00,5.000000000000000000e+00,6.000000000000000000e+00
你可以看到这里的数字是用逗号而不是空格分开的。
实例3:在输出的文本文件中使用特定的格式
接下来,我们要为输出文件中的数字使用特定的格式。
你可能注意到,在例子1和2中,数字是用科学符号表示的。
我不确定这是否有必要,因为我们Numpy数组中的数字是整数。
所以,让我们在输出数组中以整数格式保存数据。
要做到这一点,我们将使用fmt 参数,并使用'%i' 来指定我们要保存的数据为整数格式。
np.savetxt('my_numpy_data.txt', my_array, fmt = '%i')
现在,在你的电脑上找到这个文本文件,用一个文本编辑器(例如Mac上的TextEdit,或Windows上的记事本)打开它。
下面是保存的文本文件的内容。
1 2 3
4 5 6
你会注意到,在这种情况下,数字是以整数格式存储的。
公平地说,整数在工作上要简单得多。 如果你使用的是浮点数,格式化可能需要更复杂一些。
例子4:为输出的文本文件添加页眉和页脚
在这里,我们要给输出文件添加一个页眉和页脚。
我们将用header 和footer 参数来做。
np.savetxt('my_numpy_data.txt'
,my_array
,header = 'This is header text'
,footer = 'This is footer text'
)
现在,在你的电脑上找到这个文本文件,用一个文本编辑器(如Mac上的TextEdit,或Windows上的记事本)打开它。
下面是保存的文本文件的内容。
# This is header text
1.000000000000000000e+00 2.000000000000000000e+00 3.000000000000000000e+00
4.000000000000000000e+00 5.000000000000000000e+00 6.000000000000000000e+00
# This is footer text
你会注意到,这已经在文件的顶部添加了指定的 "标题 "文本,在文件的底部添加了 "页脚 "文本。
此外,注意到在页眉和页脚文本的前面有一个'#'符号。
这是为了表示这些文本行是注释。
我们也可以改变这个 "评论字符"。让我们在下一个例子中这样做。
例子5:使用一个特定的字符来指定输出文本文件的页眉/页脚中的注释
在这个例子中,我们将改变指定输出文件中评论文本行的 "评论 "字符。
我们可以用comments 字符来做这件事。
np.savetxt('my_numpy_data.txt'
,my_array
,header = 'This is header text'
,footer = 'This is footer text'
,comments = '** '
)
现在,在你的电脑上找到这个文本文件,用一个文本编辑器(例如,Mac上的TextEdit,或Windows上的记事本)打开它。
下面是保存的文本文件的内容。
** This is header text
1.000000000000000000e+00 2.000000000000000000e+00 3.000000000000000000e+00
4.000000000000000000e+00 5.000000000000000000e+00 6.000000000000000000e+00
** This is footer text
注意,在我们的代码中,我们指定了comments = '** ' 。
这在我们的注释文本行(即页眉和页脚)前使用了'** ' 作为一种前缀。
例子6:改变 "换行 "字符
最后,让我们改变换行符。
默认情况下,换行符是'\n' 。 这是文本文件和字符串的传统换行符,它将导致字符数据被打印在新的一行。
不过我们可以用np.savetxt 来进行不同的编码。
我们可以选择任何字符或字符串来指定数据的新行。
在这里,我们将使用'//'来指定一个新行。
我们将用newline 参数来指定这一点。
np.savetxt('my_numpy_data.txt'
,my_array
,newline = '//'
)
现在,在你的电脑上找到这个文本文件,用一个文本编辑器(例如Mac上的TextEdit,或Windows上的记事本)打开它。
下面是保存的文本文件的内容。
1.000000000000000000e+00 2.000000000000000000e+00 3.000000000000000000e+00//4.000000000000000000e+00 5.000000000000000000e+00 6.000000000000000000e+00//
记住,数字1、2、3是在我们数组的第一行,4、5、6是在第二行。
然而,在这个文本表述中,你可以看到3和4之间有一个// 。 这是因为我们用// 来指定新的数据行。
请记住:当你需要把你的数据作为Numpy数组加载回Python时(估计是使用Numpy loadtxt),你需要在你的加载代码中指定换行符。
