

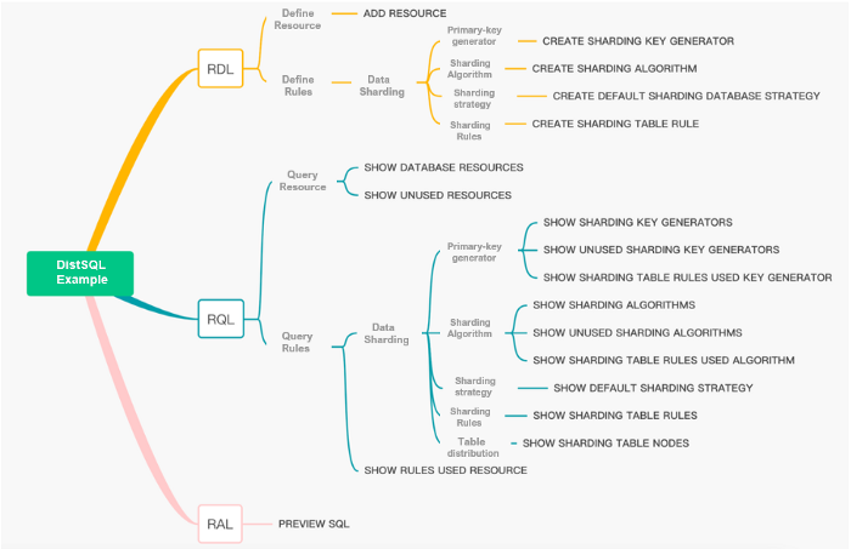
看看一个数据分片的场景,DistSQL的灵活性使你可以创建一个分布式数据库。
分布式数据库很常见,原因很多。它们提高了可靠性、冗余度和性能。Apache ShardingSphere是一个开源框架,使你能够将任何数据库转变为分布式数据库。自ShardingSphere 5.0.0发布以来,DistSQL(分布式SQL)就为ShardingSphere生态系统提供了动态管理。
在这篇文章中,我演示了一个数据分片的场景,DistSQL的灵活性使你可以创建一个分布式数据库。同时,我展示了一些语法糖来简化操作程序,允许你的潜在用户选择他们喜欢的语法。
通过实际案例运行一系列DistSQL语句,让你掌握一整套实用的DistSQL分片管理方法,通过动态管理创建和维护分布式数据库。
图片由。
(姜龙涛, CC BY-SA 4.0)
什么是分片?
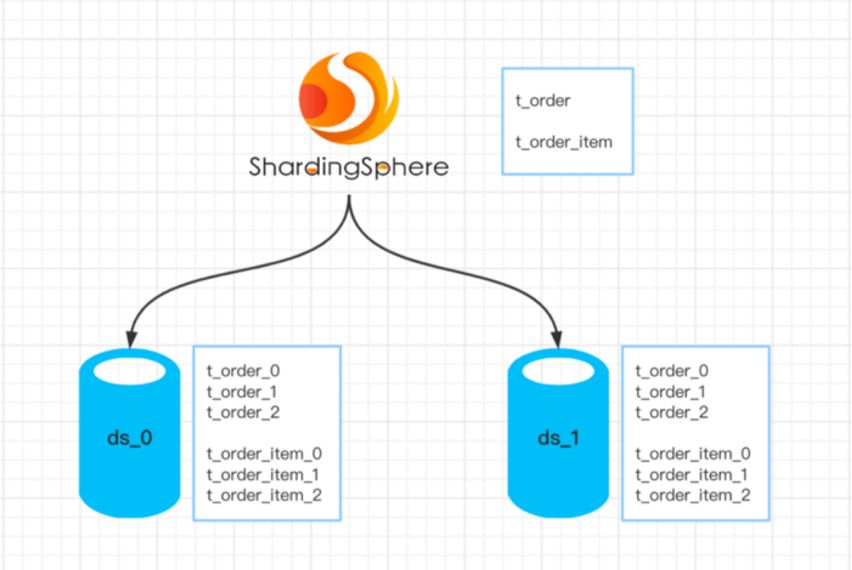
在数据库术语中,分片是将一个表分割成独立实体的过程。虽然表的数据是直接相关的,但它往往存在于不同的物理数据库节点上,或者至少存在于不同的逻辑分区中。
实际案例
要跟上这个例子,你必须有这些组件,在你的实验室里或在你阅读这篇文章时,在你的头脑中。
- 两个分片表:t_order和t_order_item。
- 对于这两个表,数据库碎片是用user_id字段进行的,而表碎片是用order_id字段进行的。
- 分片的数量是两个数据库乘以三个表。
图片由。
(姜龙涛, CC BY-SA 4.0)
设置环境
1.准备一个数据库(MySQL、MariaDB、PostgreSQL或openGauss)实例供访问。创建两个新的数据库:demo_ds_0和demo_ds_1。
2.部署Apache ShardingSphere-Proxy 5.1.2和Apache ZooKeeper。ZooKeeper充当治理中心,存储ShardingSphere元数据信息。
3.在Proxy conf目录下配置server.yaml ,如下所示。
mode:
type: Cluster
repository:
type: ZooKeeper
props:
namespace: governance_ds
server-lists: localhost:2181 #ZooKeeper address
retryIntervalMilliseconds: 500
timeToLiveSeconds: 60
maxRetries: 3
operationTimeoutMilliseconds: 500
overwrite: falserules: - !AUTHORITY
users: - root@%:root
4.启动ShardingSphere-Proxy,并使用客户端将其连接到Proxy,比如说。
$ mysql -h 127.0.0.1 -P 3307 -u root -p
5.创建一个分布式数据库。
CREATE DATABASE sharding_db;USE sharding_db;
添加存储资源
接下来,添加与数据库对应的存储资源。
ADD RESOURCE ds_0 (
HOST=127.0.0.1,
PORT=3306,
DB=demo_ds_0,
USER=root,
PASSWORD=123456
), ds_1(
HOST=127.0.0.1,
PORT=3306,
DB=demo_ds_1,
USER=root,
PASSWORD=123456
);
查看存储资源。
mysql> SHOW DATABASE RESOURCES\G;******** 1. row ***************************
name: ds_1
type: MySQL
host: 127.0.0.1
port: 3306
db: demo_ds_1
-- Omit partial attributes******** 2. row ***************************
name: ds_0
type: MySQL
host: 127.0.0.1
port: 3306
db: demo_ds_0
-- Omit partial attributes
在查询语句中添加可选的\G 开关,使输出格式易于阅读。
创建分片规则
ShardingSphere的分片规则支持常规分片和自动分片。这两种分片方法的效果是一样的。不同的是,自动分片的配置更加简明,而普通分片则更加灵活和独立。
接下来,是时候采用正则分片,使用INLINE表达式算法来实现需求中描述的分片场景了。
主键生成器
主键生成器为分布式方案中的数据表创建一个安全和唯一的主键。
1.创建一个主键生成器。
CREATE SHARDING KEY GENERATOR snowflake_key_generator (
TYPE(NAME=SNOWFLAKE)
);
2.查询主键生成器。
mysql> SHOW SHARDING KEY GENERATORS;
+-------------------------+-----------+-------+| name | type | props |
+-------------------------+-----------+-------+| snowflake_key_generator | snowflake | {} |
+-------------------------+-----------+-------+1 row in set (0.01 sec)
分片算法
1.创建一个由t_order和t_order_item共同使用的数据库分片算法。
-- Modulo 2 based on user_id in database sharding
CREATE SHARDING ALGORITHM database_inline (
TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="ds_${user_id % 2}"))
);
2.为t_order和t_order_item创建不同的表碎片算法**。**
-- Modulo 3 based on order_id in table sharding
CREATE SHARDING ALGORITHM t_order_inline (
TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="t_order_${order_id % 3}"))
);
CREATE SHARDING ALGORITHM t_order_item_inline (
TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="t_order_item_${order_id % 3}"))
);
3.查询分片算法。
mysql> SHOW SHARDING ALGORITHMS;
+---------------------+--------+---------------------------------------------------+| name | type | props |
+---------------------+--------+---------------------------------------------------+| database_inline | inline | algorithm-expression=ds_${user_id % 2} || t_order_inline | inline | algorithm-expression=t_order_${order_id % 3} || t_order_item_inline | inline | algorithm-expression=t_order_item_${order_id % 3} |
+---------------------+--------+---------------------------------------------------+3 rows in set (0.00 sec)
创建一个默认的分片策略
分片策略由分片密钥和分片算法组成,在本例中是数据库策略 和表策略。因为t_order和t_order_item具有相同的数据库分片字段和分片算法,所以创建一个默认策略,供所有没有配置分片策略的分片表使用。
1.创建一个默认的数据库分片策略。
CREATE DEFAULT SHARDING DATABASE STRATEGY (
TYPE=STANDARD,SHARDING_COLUMN=user_id,SHARDING_ALGORITHM=database_inline
);
2.查询默认策略。
mysql> SHOW DEFAULT SHARDING STRATEGY\G;*************************** 1. row ***************************
name: TABLE
type: NONE
sharding_column:
sharding_algorithm_name:
sharding_algorithm_type:
sharding_algorithm_props:*************************** 2. row ***************************
name: DATABASE
type: STANDARD
sharding_column: user_id
sharding_algorithm_name: database_inline
sharding_algorithm_type: inline
sharding_algorithm_props: {algorithm-expression=ds_${user_id % 2}}2 rows in set (0.00 sec)
你没有配置默认的表分片策略,所以TABLE的默认策略是NONE。
设置分片规则
主键生成器和分片算法都已准备就绪。现在你可以创建分片规则。我下面演示的方法有点复杂,涉及多个步骤。在下一节中,我将向你展示如何在一个步骤中创建分片规则,但现在,请见证它通常是如何完成的。
首先,定义t_order。
CREATE SHARDING TABLE RULE t_order (
DATANODES("ds_${0..1}.t_order_${0..2}"),
TABLE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=order_id,SHARDING_ALGORITHM=t_order_inline),
KEY_GENERATE_STRATEGY(COLUMN=order_id,KEY_GENERATOR=snowflake_key_generator)
);
下面是对上述数值的解释。
- DATANODES指定分片表的数据节点。
- TABLE_STRATEGY指定表策略,其中SHARDING_ALGORITHM使用创建的分片算法t_order_inline。
- KEY_GENERATE_STRATEGY指定表的主键生成策略。如果不需要生成主键,请跳过此配置。
接下来,定义t_order_item。
CREATE SHARDING TABLE RULE t_order_item (
DATANODES("ds_${0..1}.t_order_item_${0..2}"),
TABLE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=order_id,SHARDING_ALGORITHM=t_order_item_inline),
KEY_GENERATE_STRATEGY(COLUMN=order_item_id,KEY_GENERATOR=snowflake_key_generator)
);
查询分片规则以验证你所创建的内容。
mysql> SHOW SHARDING TABLE RULES\G;************************** 1. row ***************************
table: t_order
actual_data_nodes: ds_${0..1}.t_order_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_${order_id % 3}
key_generate_column: order_id
key_generator_type: snowflake
key_generator_props:*************************** 2. row ***************************
table: t_order_item
actual_data_nodes: ds_${0..1}.t_order_item_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_item_${order_id % 3}
key_generate_column: order_item_id
key_generator_type: snowflake
key_generator_props:2 rows in set (0.00 sec)
到目前为止,这看起来是正确的。现在你已经为t_order和t_order_item配置了分片规则。
你可以跳过创建主键生成器、分片算法和默认策略的步骤,并在一个步骤中完成分片规则。下面是如何让它变得更容易。
分片管理规则语法
例如,如果你想添加一个名为t_order_detail的分片表,你可以按以下方式创建分片规则。
CREATE SHARDING TABLE RULE t_order_detail (
DATANODES("ds_${0..1}.t_order_detail_${0..1}"),
DATABASE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=user_id,SHARDING_ALGORITHM(TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="ds_${user_id % 2}")))),
TABLE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=order_id,SHARDING_ALGORITHM(TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="t_order_detail_${order_id % 3}")))),
KEY_GENERATE_STRATEGY(COLUMN=detail_id,TYPE(NAME=snowflake))
);
该语句指定了数据库分片策略、表策略和主键生成策略,但它没有使用现有的算法。DistSQL引擎会自动使用输入表达式,为t_order_detail的分片规则创建一个算法。
现在有一个主键生成器。
mysql> SHOW SHARDING KEY GENERATORS;
+--------------------------+-----------+-------+| name | type | props |
+--------------------------+-----------+-------+| snowflake_key_generator | snowflake | {} || t_order_detail_snowflake | snowflake | {} |
+--------------------------+-----------+-------+2 rows in set (0.00 sec)
显示分片算法。
mysql> SHOW SHARDING ALGORITHMS;
+--------------------------------+--------+-----------------------------------------------------+| name | type | props |
+--------------------------------+--------+-----------------------------------------------------+| database_inline | inline | algorithm-expression=ds_${user_id % 2} || t_order_inline | inline | algorithm-expression=t_order_${order_id % 3} || t_order_item_inline | inline | algorithm-expression=t_order_item_${order_id % 3} || t_order_detail_database_inline | inline | algorithm-expression=ds_${user_id % 2} || t_order_detail_table_inline | inline | algorithm-expression=t_order_detail_${order_id % 3} |
+--------------------------------+--------+-----------------------------------------------------+5 rows in set (0.00 sec)
最后是分片规则。
mysql> SHOW SHARDING TABLE RULES\G;*************************** 1. row ***************************
table: t_order
actual_data_nodes: ds_${0..1}.t_order_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_${order_id % 3}
key_generate_column: order_id
key_generator_type: snowflake
key_generator_props:*************************** 2. row ***************************
table: t_order_item
actual_data_nodes: ds_${0..1}.t_order_item_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_item_${order_id % 3}
key_generate_column: order_item_id
key_generator_type: snowflake
key_generator_props:*************************** 3. row ***************************
table: t_order_detail
actual_data_nodes: ds_${0..1}.t_order_detail_${0..1}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_detail_${order_id % 3}
key_generate_column: detail_id
key_generator_type: snowflake
key_generator_props:3 rows in set (0.01 sec)
在CREATE SHARDING TABLE RULE 语句中,DATABASE_STRATEGY、TABLE_STRATEGY和KEY_GENERATE_STRATEGY可以重复使用现有的算法。
另外,它们也可以通过语法快速定义。所不同的是,额外的算法对象被创建。
配置和验证
一旦你创建了配置验证规则,你可以通过以下方式验证它们。
1.检查节点分布。
DistSQL提供了SHOW SHARDING TABLE NODES ,用于检查节点分布,用户可以快速了解分片表的分布。
mysql> SHOW SHARDING TABLE NODES;
+----------------+------------------------------------------------------------------------------------------------------------------------------+| name | nodes |
+----------------+------------------------------------------------------------------------------------------------------------------------------+| t_order | ds_0.t_order_0, ds_0.t_order_1, ds_0.t_order_2, ds_1.t_order_0, ds_1.t_order_1, ds_1.t_order_2 || t_order_item | ds_0.t_order_item_0, ds_0.t_order_item_1, ds_0.t_order_item_2, ds_1.t_order_item_0, ds_1.t_order_item_1, ds_1.t_order_item_2 || t_order_detail | ds_0.t_order_detail_0, ds_0.t_order_detail_1, ds_1.t_order_detail_0, ds_1.t_order_detail_1 |
+----------------+------------------------------------------------------------------------------------------------------------------------------+3 rows in set (0.01 sec)
mysql> SHOW SHARDING TABLE NODES t_order_item;
+--------------+------------------------------------------------------------------------------------------------------------------------------+| name | nodes |
+--------------+------------------------------------------------------------------------------------------------------------------------------+| t_order_item | ds_0.t_order_item_0, ds_0.t_order_item_1, ds_0.t_order_item_2, ds_1.t_order_item_0, ds_1.t_order_item_1, ds_1.t_order_item_2 |
+--------------+------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.00 sec)
你可以看到,分片表的节点分布与需求中描述的一致。
SQL预览
预览SQL也是验证配置的一个简单方法。其语法为:PREVIEW SQL 。首先,做一个没有分片密钥的查询,有所有的路线。
mysql> PREVIEW SELECT * FROM t_order;
+------------------+---------------------------------------------------------------------------------------------+| data_source_name | actual_sql |
+------------------+---------------------------------------------------------------------------------------------+| ds_0 | SELECT * FROM t_order_0 UNION ALL SELECT * FROM t_order_1 UNION ALL SELECT * FROM t_order_2 || ds_1 | SELECT * FROM t_order_0 UNION ALL SELECT * FROM t_order_1 UNION ALL SELECT * FROM t_order_2 |
+------------------+---------------------------------------------------------------------------------------------+2 rows in set (0.13 sec)
mysql> PREVIEW SELECT * FROM t_order_item;
+------------------+------------------------------------------------------------------------------------------------------------+| data_source_name | actual_sql |
+------------------+------------------------------------------------------------------------------------------------------------+| ds_0 | SELECT * FROM t_order_item_0 UNION ALL SELECT * FROM t_order_item_1 UNION ALL SELECT * FROM t_order_item_2 || ds_1 | SELECT * FROM t_order_item_0 UNION ALL SELECT * FROM t_order_item_1 UNION ALL SELECT * FROM t_order_item_2 |
+------------------+------------------------------------------------------------------------------------------------------------+2 rows in set (0.00 sec)
现在,在一个具有单一数据库路由的查询中指定user_id。
mysql> PREVIEW SELECT * FROM t_order WHERE user_id = 1;
+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+| data_source_name | actual_sql |
+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+| ds_1 | SELECT * FROM t_order_0 WHERE user_id = 1 UNION ALL SELECT * FROM t_order_1 WHERE user_id = 1 UNION ALL SELECT * FROM t_order_2 WHERE user_id = 1 |
+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.14 sec)
mysql> PREVIEW SELECT * FROM t_order_item WHERE user_id = 2;
+------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+| data_source_name | actual_sql |
+------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+| ds_0 | SELECT * FROM t_order_item_0 WHERE user_id = 2 UNION ALL SELECT * FROM t_order_item_1 WHERE user_id = 2 UNION ALL SELECT * FROM t_order_item_2 WHERE user_id = 2 |
+------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.00 sec)
用一个表的路由指定user_id和order_id。
mysql> PREVIEW SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1;
+------------------+------------------------------------------------------------+| data_source_name | actual_sql |
+------------------+------------------------------------------------------------+| ds_1 | SELECT * FROM t_order_1 WHERE user_id = 1 AND order_id = 1 |
+------------------+------------------------------------------------------------+1 row in set (0.04 sec)
mysql> PREVIEW SELECT * FROM t_order_item WHERE user_id = 2 AND order_id = 5;
+------------------+-----------------------------------------------------------------+| data_source_name | actual_sql |
+------------------+-----------------------------------------------------------------+| ds_0 | SELECT * FROM t_order_item_2 WHERE user_id = 2 AND order_id = 5 |
+------------------+-----------------------------------------------------------------+1 row in set (0.01 sec)
单表路由扫描最少的分片表,提供最高的效率。
查询未使用的资源
在系统维护期间,不再使用的算法或存储资源可能需要释放,或者需要释放的资源可能已经被引用而无法删除。DistSQL的SHOW UNUSED RESOURCES 命令可以解决这些问题。
mysql> ADD RESOURCE ds_2 (
-> HOST=127.0.0.1,
-> PORT=3306,
-> DB=demo_ds_2,
-> USER=root,
-> PASSWORD=123456
-> );
Query OK, 0 rows affected (0.07 sec)
mysql> SHOW UNUSED RESOURCES\G;*************************** 1. row ***************************
name: ds_2
type: MySQL
host: 127.0.0.1
port: 3306
db: demo_ds_2
connection_timeout_milliseconds: 30000
idle_timeout_milliseconds: 60000
max_lifetime_milliseconds: 2100000
max_pool_size: 50
min_pool_size: 1
read_only: false
other_attributes: {"dataSourceProperties":{"cacheServerConfiguration":"true","elideSetAutoCommits":"true","useServerPrepStmts":"true","cachePrepStmts":"true","useSSL":"false","rewriteBatchedStatements":"true","cacheResultSetMetadata":"false","useLocalSessionState":"true","maintainTimeStats":"false","prepStmtCacheSize":"200000","tinyInt1isBit":"false","prepStmtCacheSqlLimit":"2048","serverTimezone":"UTC","netTimeoutForStreamingResults":"0","zeroDateTimeBehavior":"round"},"healthCheckProperties":{},"initializationFailTimeout":1,"validationTimeout":5000,"leakDetectionThreshold":0,"poolName":"HikariPool-8","registerMbeans":false,"allowPoolSuspension":false,"autoCommit":true,"isolateInternalQueries":false}1 row in set (0.03 sec)
查询未使用的主键生成器
DistSQL还可以通过SHOW UNUSED SHARDING KEY GENERATORS ,显示未使用的分片密钥生成器。
mysql> SHOW SHARDING KEY GENERATORS;
+--------------------------+-----------+-------+| name | type | props |
+--------------------------+-----------+-------+| snowflake_key_generator | snowflake | {} || t_order_detail_snowflake | snowflake | {} |
+--------------------------+-----------+-------+2 rows in set (0.00 sec)
mysql> SHOW UNUSED SHARDING KEY GENERATORS;
Empty set (0.01 sec)
mysql> CREATE SHARDING KEY GENERATOR useless (
-> TYPE(NAME=SNOWFLAKE)
-> );
Query OK, 0 rows affected (0.04 sec)
mysql> SHOW UNUSED SHARDING KEY GENERATORS;
+---------+-----------+-------+| name | type | props |
+---------+-----------+-------+| useless | snowflake | |
+---------+-----------+-------+1 row in set (0.01 sec)
查询未使用的分片算法
DistSQL可以通过(你猜对了)SHOW UNUSED SHARDING ALGORITHMS 命令揭示未使用的分片算法。
mysql> SHOW SHARDING ALGORITHMS;
+--------------------------------+--------+-----------------------------------------------------+| name | type | props |
+--------------------------------+--------+-----------------------------------------------------+| database_inline | inline | algorithm-expression=ds_${user_id % 2} || t_order_inline | inline | algorithm-expression=t_order_${order_id % 3} || t_order_item_inline | inline | algorithm-expression=t_order_item_${order_id % 3} || t_order_detail_database_inline | inline | algorithm-expression=ds_${user_id % 2} || t_order_detail_table_inline | inline | algorithm-expression=t_order_detail_${order_id % 3} |
+--------------------------------+--------+-----------------------------------------------------+5 rows in set (0.00 sec)
mysql> CREATE SHARDING ALGORITHM useless (
-> TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="ds_${user_id % 2}"))
-> );
Query OK, 0 rows affected (0.04 sec)
mysql> SHOW UNUSED SHARDING ALGORITHMS;
+---------+--------+----------------------------------------+| name | type | props |
+---------+--------+----------------------------------------+| useless | inline | algorithm-expression=ds_${user_id % 2} |
+---------+--------+----------------------------------------+1 row in set (0.00 sec)
使用目标存储资源的查询规则
你还可以通过SHOW RULES USED RESOURCE ,查看规则内使用的资源。所有使用资源的规则都可以被查询,不限于分片规则。
mysql> DROP RESOURCE ds_0;
ERROR 1101 (C1101): Resource [ds_0] is still used by [ShardingRule].
mysql> SHOW RULES USED RESOURCE ds_0;
+----------+----------------+| type | name |
+----------+----------------+| sharding | t_order || sharding | t_order_item || sharding | t_order_detail |
+----------+----------------+3 rows in set (0.00 sec)
使用目标主键生成器的查询分片规则
你可以使用密钥生成器SHOW SHARDING TABLE RULES USED KEY GENERATOR ,找到分片规则。
mysql> SHOW SHARDING KEY GENERATORS;
+--------------------------+-----------+-------+| name | type | props |
+--------------------------+-----------+-------+| snowflake_key_generator | snowflake | {} || t_order_detail_snowflake | snowflake | {} || useless | snowflake | {} |
+--------------------------+-----------+-------+3 rows in set (0.00 sec)
mysql> DROP SHARDING KEY GENERATOR snowflake_key_generator;
ERROR 1121 (C1121): Sharding key generator `[snowflake_key_generator]` in database `sharding_db` are still in used.
mysql> SHOW SHARDING TABLE RULES USED KEY GENERATOR snowflake_key_generator;
+-------+--------------+| type | name |
+-------+--------------+| table | t_order || table | t_order_item |
+-------+--------------+2 rows in set (0.00 sec)
使用目标算法的查询分片规则
用目标算法显示分片规则,SHOW SHARDING TABLE RULES USED ALGORITHM 。
mysql> SHOW SHARDING ALGORITHMS;
+--------------------------------+--------+-----------------------------------------------------+| name | type | props |
+--------------------------------+--------+-----------------------------------------------------+| database_inline | inline | algorithm-expression=ds_${user_id % 2} || t_order_inline | inline | algorithm-expression=t_order_${order_id % 3} || t_order_item_inline | inline | algorithm-expression=t_order_item_${order_id % 3} || t_order_detail_database_inline | inline | algorithm-expression=ds_${user_id % 2} || t_order_detail_table_inline | inline | algorithm-expression=t_order_detail_${order_id % 3} || useless | inline | algorithm-expression=ds_${user_id % 2} |
+--------------------------------+--------+-----------------------------------------------------+6 rows in set (0.00 sec)
mysql> DROP SHARDING ALGORITHM t_order_detail_table_inline;
ERROR 1116 (C1116): Sharding algorithms `[t_order_detail_table_inline]` in database `sharding_db` are still in used.
mysql> SHOW SHARDING TABLE RULES USED ALGORITHM t_order_detail_table_inline;
+-------+----------------+| type | name |
+-------+----------------+| table | t_order_detail |
+-------+----------------+1 row in set (0.00 sec)
让分片管理更加完善
DistSQL提供了一个灵活的语法来帮助简化操作。除了INLINE算法之外,DistSQL还支持标准分片、复合分片、HINT分片和自定义分片算法。
