

我演示了一个Groovy脚本,用来清理标签字段的杂乱组合。
最近,我一直在研究Groovy如何精简Java。在这个系列中,我正在开发几个脚本来帮助清理我的音乐收藏。在我的上一篇文章中,我使用之前开发的框架,创建了一个唯一文件名的列表,以及这些文件名在音乐收藏目录中出现的次数。然后我使用Linux的find 命令来删除我不想要的文件。
在这篇文章中,我演示了一个Groovy脚本来清理标签字段的杂乱组合。
警告:这个脚本改变了音乐标签,所以你必须对你测试代码的音乐集进行备份,这一点至关重要。
Vorbis和ID3标签
我没有很多MP3音乐文件。一般来说,我更喜欢使用FLAC。但有时只有MP3版本,或者购买黑胶时有免费的MP3下载。所以在这个脚本中,我必须能够处理这两种情况。随着我对JAudiotagger的熟悉,我学到了一件事,那就是ID3标签(MP3使用的)的样子,我发现我在这个系列的第二部分中发现的一些 "不需要的 "字段标签ID实际上是非常有用的。
现在是时候使用这个框架来获取一个音乐集合中所有标签字段ID的列表,以及它们的计数,以开始决定什么属于什么不属于。
1 @Grab('net.jthink:jaudiotagger:3.0.1')
2 import org.jaudiotagger.audio.*
3 import org.jaudiotagger.tag.*
4 def logger = java.util.logging.Logger.getLogger('org.jaudiotagger');
5 logger.setLevel(java.util.logging.Level.OFF);
6 // Define the music library directory
7 def musicLibraryDirName = '/var/lib/mpd/music'
8 // Define the tag field id accumulation map
9 def tagFieldIdCounts = [:]
10 // Print the CSV file header
11 println "tagFieldId|count"
12 // Iterate over each directory in the music libary directory
13 // These are assumed to be artist directories
14 new File(musicLibraryDirName).eachDir { artistDir ->
15 // Iterate over each directory in the artist directory
16 // These are assumed to be album directories
17 artistDir.eachDir { albumDir ->
18 // Iterate over each file in the album directory
19 // These are assumed to be content or related
20 // (cover.jpg, PDFs with liner notes etc)
21 albumDir.eachFile { contentFile ->
22 // Analyze the file and print the analysis
23 if (contentFile.name ==~ /.*\.(flac|mp3|ogg)/) {
24 def af = AudioFileIO.read(contentFile)
25 af.tag.fields.each { tagField ->
26 tagFieldIdCounts[tagField.id] = tagFieldIdCounts.containsKey(tagField.id) ? tagFieldIdCounts[tagField.id] + 1 : 1
27 }
28 }
29 }
30 }
31 }
32 tagFieldIdCounts.each { key, value ->
33 println "$key|$value"
34 }
第1-7行最初出现在本系列的第2部分。
第8-9行定义了一个累积标签字段ID和出现次数的地图。
第10-21行也出现在以前的文章中。他们深入到各个内容文件的层面。
第23-28行确保正在使用的文件是FLAC、MP3或OGG。第23行使用Groovy的匹配操作符==~ ,用一个slashy正则表达式来过滤掉想要的文件。
第24行使用org.jaudiotagger.audio.AudioFileIO.read() ,从内容文件中获取标签主体。
第25-27行使用org.jaudiotagger.tag.Tag.getFields() 来获取标签主体中所有的TagField 实例,并使用Groovyeach() 方法来迭代该实例列表。
第27行将每个tagField.id 的计数累积到tagFieldIdCounts 地图中。
最后,第32-24行遍历tagFieldIdCounts 地图,打印出键(找到的标签字段ID)和值(每个标签字段ID出现的次数)。
我按如下方式运行这个脚本。
$ groovy TagAnalyzer5b.groovy > tagAnalysis5b.csv
然后我把结果加载到LibreOffice或OnlyOffice电子表格中。在我的例子中,这个脚本需要相当长的时间来运行(几分钟),加载的数据,按照第二列(计数)的降序排序,看起来像这样。
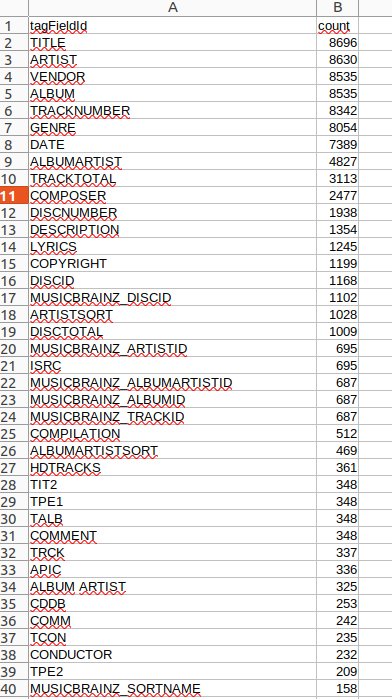
Image by:
(Chris Hermansen, CC BY-SA 4.0)
在第2行,你可以看到有8696个TITLE字段标签ID的出现,这是FLAC文件(和Vorbis,一般)用于歌曲标题的ID。在第28行,你还可以看到有348个TIT2字段标签ID的出现,这是ID3标签字段,包含歌曲的 "实际 "名称。在这一点上,值得去看一下org.jaudiotagger.tag.ide.framebody.FrameBodyTIT2 的JavaDoc,以了解更多关于这个标签和JAudiotagger识别它的方式。在那里,你还可以看到处理其他ID3标签字段的机制。
在这个字段标签ID的列表中,有很多我不感兴趣的东西,它们会影响各种音乐播放器以我认为合理的顺序显示我的音乐收藏的能力。
org.jaudiotagger.tag.Tag接口
我要花点时间来探索JAudiotagger提供的访问标签字段的通用机制。这个机制在org.jaudiotagger.tag.Tag 的JavaDocs中有描述。有两个方法可以帮助清理标签字段的情况。
void setField(FieldKey genericKey,[String](http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string) value)
这句话是用来设置某个标签字段的值的。
这一行用于删除一个特定标签字段的所有实例(原来在一些标签方案中,有些标签字段允许多次出现)。
void deleteField(FieldKey fieldKey)
然而,这个特定的deleteField() 方法要求我们提供一个FieldKey 值,而我发现,在我的音乐收藏中,并非所有的字段键ID都对应于一个已知的FieldKey 值。
环顾JavaDocs,我看到有一个FlacTag ,它 "对其大部分元数据使用Vorbis注释",并声明其标签字段为VorbisCommentTag 。
VorbisCommentTag 它本身扩展了 ,它提供了。org.jaudiotagger.audio.generic.AbstractTag
protected void deleteField([String](http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string) key)
事实证明,这可以从AudioFileIO.read(f).getTag() ,至少对FLAC和MP3标签体来说,可以从标签实例中访问。
从理论上讲,应该可以这样做。
-
用以下方法获取标签主体
def af = AudioFileIO.read(contentFile) def tagBody = af.tag -
获取我想要的(已知的)标签字段的值,使用。
def album = tagBody.getFirst(FieldKey.ALBUM) def artist = tagBody.getFirst(FieldKey.ARTIST) // etc -
删除所有标签字段(包括想要的和不想要的),使用。
def originalTagFieldIdList = tagBody.fields.collect { tagField -> tagField.id } originalTagFieldIdList.each { tagFieldId -> tagBody.deleteField(tagFieldId) } -
只放回想要的标签字段。
tagBody.setField(FieldKey.ALBUM, album) tagBody.setField(FieldKey.ARTIST, artist) // etc
当然,这里有一些小问题。
首先,注意到originalTagFieldIdList 的使用。我不能在修改这些字段的同时使用each() 遍历tagBody.getFields() 返回的迭代器;所以我使用collect() 把标签字段 ID 变成一个列表,然后遍历这个标签字段 ID 列表来进行删除。
第二,并非所有文件都有我想要的所有标签字段。例如,有些文件可能没有定义ALBUM_SORT_ORDER ,等等。我可能不希望把这些标签字段写成空值。此外,我可能可以安全地默认一些字段。例如,如果没有定义ALBUM_ARTIST ,我可以把它设置为ARTIST。
第三,对我来说最晦涩难懂的是,Vorbis评论标签总是包括一个VENDOR字段的标签ID;如果我试图删除它,我最终会简单地取消设置该值。哼。
尝试这一切
考虑到这些教训,我决定创建一个测试的音乐目录,其中只包含一些艺术家和他们的专辑(因为我不想把我的音乐收藏全部清除。)
警告:因为这个脚本会改变音乐标签,所以有一个音乐收藏的备份是非常重要的,这样当我发现我删除了一个重要的标签时,我可以恢复备份,修改脚本并重新运行它。
下面是这个脚本。
1 @Grab('net.jthink:jaudiotagger:3.0.1')
2 import org.jaudiotagger.audio.*
3 import org.jaudiotagger.tag.*
4 def logger = java.util.logging.Logger.getLogger('org.jaudiotagger');5 logger.setLevel(java.util.logging.Level.OFF);
6 // Define the music library directory
7 def musicLibraryDirName = '/work/Test/Music'
8 // Print the CSV file header
9 println "artistDir|albumDir|contentFile|tagField.id|tagField.toString()"
10 // Iterate over each directory in the music libary directory
11 // These are assumed to be artist directories
12 new File(musicLibraryDirName).eachDir { artistDir ->
13 // Iterate over each directory in the artist directory
14 // These are assumed o be album directories
15 artistDir.eachDir { albumDir ->
16 // Iterate over each file in the album directory
17 // These are assumed to be content or related18 // (cover.jpg, PDFs with liner notes etc)
19 albumDir.eachFile { contentFile ->
20 // Analyze the file and print the analysis
21 if (contentFile.name ==~ /.*\.(flac|mp3|ogg)/) {
22 def af = AudioFileIO.read(contentFile)
23 def tagBody = af.tag
24 def album = tagBody.getFirst(FieldKey.ALBUM)
25 def albumArtist = tagBody.getFirst(FieldKey.ALBUM_ARTIST)
26 def albumArtistSort = tagBody.getFirst(FieldKey.ALBUM_ARTIST_SORT)
27 def artist = tagBody.getFirst(FieldKey.ARTIST)
28 def artistSort = tagBody.getFirst(FieldKey.ARTIST_SORT)
29 def composer = tagBody.getFirst(FieldKey.COMPOSER)
30 def composerSort = tagBody.getFirst(FieldKey.COMPOSER_SORT)
31 def genre = tagBody.getFirst(FieldKey.GENRE)
32 def title = tagBody.getFirst(FieldKey.TITLE)
33 def titleSort = tagBody.getFirst(FieldKey.TITLE_SORT)
34 def track = tagBody.getFirst(FieldKey.TRACK)
35 def trackTotal = tagBody.getFirst(FieldKey.TRACK_TOTAL)
36 def year = tagBody.getFirst(FieldKey.YEAR)
37 if (!albumArtist) albumArtist = artist
38 if (!albumArtistSort) albumArtistSort = albumArtist
39 if (!artistSort) artistSort = artist
40 if (!composerSort) composerSort = composer
41 if (!titleSort) titleSort = title
42 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.ALBUM|${album}"
43 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.ALBUM_ARTIST|${albumArtist}"
44 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.ALBUM_ARTIST_SORT|${albumArtistSort}"
45 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.ARTIST|${artist}"
46 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.ARTIST_SORT|${artistSort}"
47 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.COMPOSER|${composer}"
48 println "${artistDir.name}|${albumDir.name}|${contentFile.name}
|FieldKey.COMPOSER_SORT|${composerSort}"
49 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.GENRE|${genre}"
50 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.TITLE|${title}"
51 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.TITLE_SORT|${titleSort}"
52 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.TRACK|${track}"
53 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.TRACK_TOTAL|${trackTotal}"
54 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.YEAR|${year}"
55 def originalTagIdList = tagBody.fields.collect {
56 tagField -> tagField.id
57 }
58 originalTagIdList.each { tagFieldId ->
59 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|${tagFieldId}|XXX"
60 if (tagFieldId != 'VENDOR')
61 tagBody.deleteField(tagFieldId)
62 }
63 if (album) tagBody.setField(FieldKey.ALBUM, album)
64 if (albumArtist) tagBody.setField(FieldKey.ALBUM_ARTIST, albumArtist)
65 if (albumArtistSort) tagBody.setField(FieldKey.ALBUM_ARTIST_SORT, albumArtistSort)
66 if (artist) tagBody.setField(FieldKey.ARTIST, artist)
67 if (artistSort) tagBody.setField(FieldKey.ARTIST_SORT, artistSort)
68 if (composer) tagBody.setField(FieldKey.COMPOSER, composer)
69 if (composerSort) tagBody.setField(FieldKey.COMPOSER_SORT, composerSort)
70 if (genre) tagBody.setField(FieldKey.GENRE, genre)
71 if (title) tagBody.setField(FieldKey.TITLE, title)
72 if (titleSort) tagBody.setField(FieldKey.TITLE_SORT, titleSort)
73 if (track) tagBody.setField(FieldKey.TRACK, track)
74 if (trackTotal) tagBody.setField(FieldKey.TRACK_TOTAL, trackTotal)
75 if (year) tagBody.setField(FieldKey.YEAR, year)
76 af.commit()77 }
78 }
79 }
80 }
第1-21行已经很熟悉了。请注意,我在第7行定义的音乐目录是指一个测试目录。
第22-23行获得标签主体。
第24-36行得到我感兴趣的字段(但可能不是你感兴趣的字段,所以请根据你自己的要求自由调整!)。
第37-41行为缺失的ALBUM_ARTIST和排序顺序调整一些值。
第42-54行打印出每个标签字段的键值和调整后的值,供后人参考。
第55-57行获得所有标签字段ID的列表。
第58-62行打印出每个标签字段ID并将其删除,但VENDOR标签字段ID除外。
第63-75行使用已知的标签字段键设置所需的标签字段值。
最后,第76行将修改提交给文件。
该脚本产生的输出可以导入电子表格中。
我只想再提一次,这个脚本会改变音乐标签!这一点非常重要。有一个音乐收藏的备份是非常重要的,这样当你发现你删除了一个重要的标签,或者以某种方式破坏了你的音乐文件,你可以恢复备份,修改脚本,然后重新运行它。
用这个Groovy脚本检查结果
我有一个方便的小Groovy脚本来检查结果。
1 @Grab('net.jthink:jaudiotagger:3.0.1')
2 import org.jaudiotagger.audio.*
3 import org.jaudiotagger.tag.*
4 def logger = java.util.logging.Logger.getLogger('org.jaudiotagger');
5 logger.setLevel(java.util.logging.Level.OFF);
6 // Define the music libary directory
7 def musicLibraryDirName = '/work/Test/Music'
8 // Print the CSV file header
9 println "artistDir|albumDir|tagField.id|tagField.toString()"
10 // Iterate over each directory in the music libary directory
11 // These are assumed to be artist directories
12 new File(musicLibraryDirName).eachDir { artistDir ->
13 // Iterate over each directory in the artist directory
14 // These are assumed to be album directories
15 artistDir.eachDir { albumDir ->
16 // Iterate over each file in the album directory
17 // These are assumed to be content or related
18 // (cover.jpg, PDFs with liner notes etc)
19 albumDir.eachFile { contentFile ->
20 // Analyze the file and print the analysis
21 if (contentFile.name ==~ /.*\.(flac|mp3|ogg)/) {
22 def af = AudioFileIO.read(contentFile)
23 af.tag.fields.each { tagField ->
24 println "${artistDir.name}|${albumDir.name}|${tagField.id}|${tagField.toString()}"
25 }
26 }
27 }
28 }
29 }
现在看来,这应该很熟悉了
在运行上一节中的修复器脚本之前,运行它产生的结果是这样的。
St Germain|Tourist|VENDOR|reference libFLAC 1.1.4 20070213
St Germain|Tourist|TITLE|Land Of...
St Germain|Tourist|ARTIST|St Germain
St Germain|Tourist|ALBUM|Tourist
St Germain|Tourist|TRACKNUMBER|04
St Germain|Tourist|TRACKTOTAL|09
St Germain|Tourist|GENRE|Electronica
St Germain|Tourist|DISCID|730e0809
St Germain|Tourist|MUSICBRAINZ_DISCID|jdWlcpnr5MSZE9H0eibpRfeZtt0-
St Germain|Tourist|MUSICBRAINZ_SORTNAME|St Germain
一旦运行固定器脚本,它产生的结果是这样的。
St Germain|Tourist|VENDOR|reference libFLAC 1.1.4 20070213
St Germain|Tourist|ALBUM|Tourist
St Germain|Tourist|ALBUMARTIST|St Germain
St Germain|Tourist|ALBUMARTISTSORT|St Germain
St Germain|Tourist|ARTIST|St Germain
St Germain|Tourist|ARTISTSORT|St Germain
St Germain|Tourist|GENRE|Electronica
St Germain|Tourist|TITLE|Land Of...
St Germain|Tourist|TITLESORT|Land Of...
St Germain|Tourist|TRACKNUMBER|04
St Germain|Tourist|TRACKTOTAL|09
就这样了!现在我只需要鼓起勇气在我的全部音乐库中运行我的修复器脚本......
