

以下是我如何使用开源工具来分析我的音乐目录,包括专辑封面文件。
在这个系列中,我正在开发几个脚本来帮助清理我的音乐收藏。在上一篇文章中,我使用了我创建的分析音乐文件目录和子目录的框架,并利用优秀的开源JAudiotagger库进行分析,分析音乐目录和子目录中的音乐文件的标签。在这篇文章中,我将做一个更简单的工作。
- 使用我们在第一部分创建的框架
- 确保每个专辑目录有一个
cover.jpg类 - 记下专辑目录中任何不是FLAC、MP3或OGG的其他文件。
音乐和元数据
还有一件事。大多数音频翻录应用程序和许多下载。
- 没有附带一个有用的
cover.jpg文件 - 即使他们有一个有用的
cover.jpg文件,他们也没有把媒体文件链接到这个文件上 - 携带各种实用性可疑的文件(例如,
playlist.m3u,它是由我过去使用的一个标签工具创建的)。
正如我在上一篇文章中提到的,这个系列的最终目标是创建一些有用的脚本,以帮助识别丢失或不寻常的标签,并促进创建一个工作计划来解决标签问题。这个特别的脚本寻找丢失的cover.jpg 文件和不需要的非媒体文件,并创建一个CSV文件,你可以把它加载到LibreOffice或OnlyOffice中去寻找问题。它不会查看媒体文件本身,也不会查找留在艺术家子目录中的无关文件(那些是留给读者的练习)。
框架和专辑文件分析
从代码开始。和以前一样,我在脚本中加入了注释,反映了我通常给自己留下的(相对简略的)"注释说明"。
1 // Define the music library directory
2 def musicLibraryDirName = '/var/lib/mpd/music'
3 // Print the CSV file header
4 println "artist|album|cover|unwanted files"
5 // Iterate over each directory in the music libary directory
6 // These are assumed to be artist directories
7 new File(musicLibraryDirName).eachDir { artistDir ->
8 // Iterate over each directory in the artist directory
9 // These are assumed to be album directories
10 artistDir.eachDir { albumDir ->
11 // Iterate over each file in the album directory
12 // These are assumed to be content or related
13 // (cover.jpg, PDFs with liner notes etc)
14 // Initialize the counter for cover.jpg
15 // and the list for unwanted file names
16 def coverCounter = 0
17 def unwantedFileNames = []
18 albumDir.eachFile { contentFile ->
19 // Analyze the file
20 if (contentFile.name ==~ /.*\.(flac|mp3|ogg)/) {
21 // nothing to do here
22 } else if (contentFile.name == 'cover.jpg') {
23 coverCounter++
24 } else {
25 unwantedFileNames << contentFile.name
26 }
27 }
28 println "${artistDir.name}|${albumDir.name}|$coverCounter|${unwantedFileNames.join(',')}"
29 }
30 }
第1-2行定义音乐文件目录的名称。
第3-4行打印CSV文件的标题。
第5-13行来自本文第一部分中创建的框架,并深入到专辑的子目录中。
第14-17行设置了cover.jpg 计数器(应该永远只有0或1)和空列表,我们将在其中积累不需要的文件名。
第18-27行分析在专辑目录中发现的任何文件。
第20-21行使用Groovy的匹配运算符==~ 和一个 "slashy "正则表达式来检查文件名模式。对这些文件不做任何处理(见第二部分的信息)。
第22-23行计算cover.jpg 的实例(它应该只有0或1)。
第24-26行记录任何非媒体文件的名称,non-cover.jpg ,以显示潜在的杂物或专辑目录中不知道的东西。
第28行打印出艺术家名称、专辑名称、cover.jpg计数和不需要的文件名列表。
这就是了!
运行该代码
通常情况下,我按以下方式运行这个程序。
$ groovy TagAnalyzer3.groovy > tagAnalysis3.csv
然后,我将生成的CSV加载到电子表格中。例如,在LibreOffice Calc中,进入工作表菜单并选择从文件中插入工作表。当出现提示时,将分隔符设置为| 。在我的例子中,结果看起来像这样。
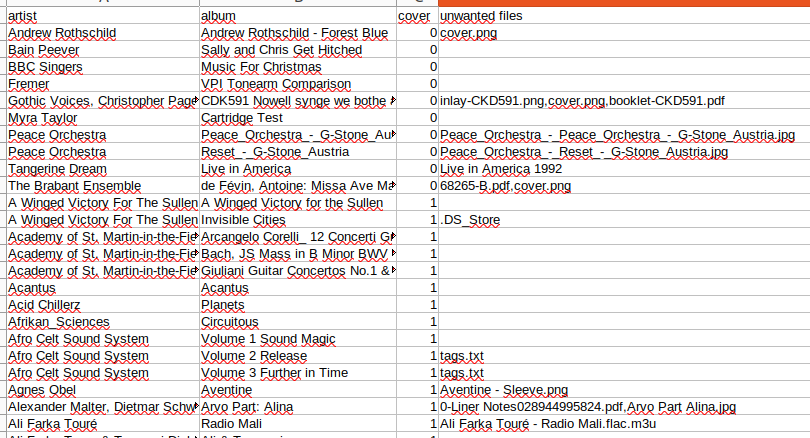
我按照 "封面 "列的递增顺序进行排序,以显示没有cover.jpg 文件的专辑子目录。请注意,有些有cover.png ,而不是。我对音乐播放器的经验是,至少有些播放器对PNG格式的封面图片玩得不好。
另外,请注意,其中一些有PDF内页注释,额外的图像文件,M3U播放列表,等等。
