

学习在Java中创建一个Web Scrapper应用程序。本教程中开发的Web Scrapper做了以下动作。
- 读取一个Excel文件,并从指定的列中读取根URLs
- 创建新的可运行任务并提交给线程池执行器
- 创建带有Semaphore的BlockingThreadPoolExecutor,以实现任务节流
- 任务从根URL中获取前20个链接
- 任务点击所有20个URL并提取每个页面的页面标题
- 定期检查完成的URL,并将访问过的URL及其标题写入Excel报告中
这个应用程序不能在生产中使用,因为有很多改进的地方。将此代码作为如何建立一个网络搜刮器的概念性参考。
请根据你的需要自由替换或修改演示程序的任何部分。
1.Maven的依赖性
首先要包括以下依赖的最新版本。
- org.apache.poi:poi。用于读取和写入excel文件。
- org.apache.poi:poi-ooxml: 支持使用SAX解析器读取excel文件。
- io.rest-assured:rest-assured: 用于调用URLs和捕获输出。
- org.jsoup:jsoup: 用于解析和提取HTML文档的信息。
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
2.读取输入并提交处理
Scrapper从excel文件中读取根URLs并创建一个UrlRecord实例。对于每个UrlRecord,创建一个新的ScrapTask线程并交给BlockingThreadPoolExecutor来调用URLs和提取标题。
2.1.读取来自Excel的输入
该应用程序使用SAX解析器API来读取Excel,所以如果Excel文件太大,我们不会出现OutOfMemory错误。我们只列出相关的代码片断。完整的清单,请访问Github资源库。
public class WebScrappingApp {
public static void main(String[] args) throws Exception {
...
RowHandler handler = new RowHandler();
handler.readExcelFile("C:\\temp\\webscrapping-root-urls.xlsx");
...
}
}
public class RowHandler extends SheetHandler {
protected Map<String, String> headerRowMapping = new HashedMap<>();
...
@Override
protected void processRow() throws ExecutionException, InterruptedException {
//Assuming that first row is column names
if (rowNumber > 1 && !rowValues.isEmpty()) {
String url = rowValues.get("B");
if(url != null && !url.trim().equals("")) {
UrlRecord entity = new UrlRecord();
entity.setRownum((int) rowNumber);
entity.setRootUrl(url.trim()); //root URL
JobSubmitter.submitTask(entity);
}
}
}
}
public class SheetHandler extends DefaultHandler {
...
public void readExcelFile(String filename) throws Exception {
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
try (OPCPackage opcPackage = OPCPackage.open(filename)) {
XSSFReader xssfReader = new XSSFReader(opcPackage);
sharedStringsTable = (SharedStringsTable) xssfReader.getSharedStringsTable();
stylesTable = xssfReader.getStylesTable();
ContentHandler handler = this;
Iterator<InputStream> sheets = xssfReader.getSheetsData();
if (sheets instanceof XSSFReader.SheetIterator) {
XSSFReader.SheetIterator sheetIterator = (XSSFReader.SheetIterator) sheets;
while (sheetIterator.hasNext()) {
try (InputStream sheet = sheetIterator.next()) {
sheetName = sheetIterator.getSheetName();
sheetNumber++;
startSheet();
saxParser.parse(sheet, (DefaultHandler) handler);
endSheet();
}
}
}
}
}
}
2.2.提交执行
注意RowHandler的processRow()方法中的*JobSubmitter.submitTask()*语句。JobSubmitter负责将任务提交到BlockingThreadPoolExecutor 。
public class JobSubmitter {
public static List<Future<?>> futures = new ArrayList<Future<?>>();
static BlockingQueue<Runnable> blockingQueue = new LinkedBlockingQueue<Runnable>(25000);
static BlockingThreadPoolExecutor executor
= new BlockingThreadPoolExecutor(5,10, 10000, TimeUnit.MILLISECONDS, blockingQueue);
static {
executor.setRejectedExecutionHandler(new RejectedExecutionHandler()
{
...
});
// Let start all core threads initially
executor.prestartAllCoreThreads();
}
public static void submitTask(UrlRecord entity) {
Future<?> f = executor.submit(new ScrapTask(entity));
futures.add(f);
}
}
BlockingThreadPoolExecutor是ThreadPoolExecutor的一个自定义实现,它支持任务节流,所以我们不会超过可用资源的数量,如HTTP连接。
public class BlockingThreadPoolExecutor extends ThreadPoolExecutor {
private final Semaphore semaphore;
public BlockingThreadPoolExecutor(int corePoolSize, int maximumPoolSize,
long keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
semaphore = new Semaphore(10);
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
}
@Override
public void execute(final Runnable task) {
boolean acquired = false;
do {
try {
Thread.sleep(1000);
semaphore.acquire();
acquired = true;
} catch (final InterruptedException e) {
System.out.println("InterruptedException whilst aquiring semaphore" + e);
}
} while (!acquired);
try {
super.execute(task);
} catch (final RejectedExecutionException e) {
System.out.println("Task Rejected");
semaphore.release();
throw e;
}
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
if (t != null) {
t.printStackTrace();
}
semaphore.release();
}
}
3.搜集URL
实际处理发生在ScrapTask类中,它是一个线程,由执行器执行。ScrapTask调用URLs并刮取内容。所有自定义的搜刮逻辑都在这里。
public class ScrapTask implements Runnable {
public ScrapTask(UrlRecord entity) {
this.entity = entity;
}
private UrlRecord entity;
public UrlRecord getEntity() {
return entity;
}
public void setEntity(UrlRecord entity) {
this.entity = entity;
}
static String[] tokens = new String[]{" private", "pvt.", " pvt",
" limited", "ltd.", " ltd"};
static RestAssuredConfig config = RestAssured.config()
.httpClient(HttpClientConfig.httpClientConfig()
.setParam(CoreConnectionPNames.CONNECTION_TIMEOUT, 30000)
.setParam(CoreConnectionPNames.SO_TIMEOUT, 30000));
@Override
public void run() {
try {
loadPagesAndGetTitles(entity.getRootUrl());
} catch (Exception e) {
e.printStackTrace();
}
}
private void loadPagesAndGetTitles(String rootUrl) {
try{
Response response = given()
.config(config)
.when()
.get(rootUrl)
.then()
.log().ifError()
.contentType(ContentType.HTML).
extract().response();
Document document = Jsoup.parse(response.getBody().asString());
Elements anchors = document.getElementsByTag("a");
if (anchors != null && anchors.size() > 0) {
for (int i = 0; i < anchors.size() && i < 20; i++) {
String visitedUrl = anchors.get(i).attributes().get("href");
if(visitedUrl.startsWith("/")) {
String title = getTitle(rootUrl + visitedUrl);
UrlRecord newEntity = new UrlRecord();
newEntity.setRownum(WebScrappingApp.rowCounter++);
newEntity.setRootUrl(entity.getRootUrl());
newEntity.setVisitedUrl(rootUrl + visitedUrl);
newEntity.setTitle(title);
System.out.println("Fetched Record: " + newEntity);
WebScrappingApp.processedRecords.add(newEntity);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
private String getTitle(String url) {
try {
Response response = given()
.config(config)
.when()
.get(url)
.then()
.log().ifError()
.contentType(ContentType.HTML).
extract().response();
Document document = Jsoup.parse(response.getBody().asString());
Elements titles = document.getElementsByTag("title");
if (titles != null && titles.size() > 0) {
return titles.get(0).text();
}
}
catch (Exception e) {
e.printStackTrace();
}
return "Not Found";
}
}
4.4.将搜刮的记录写到输出
ScrapTask ,为每个URL创建新的UrlRecord实例,并把它们放在一个BlockingQueue中。一个新的线程持续关注这个队列,每30秒从队列中抽出所有的记录。然后,报告编写者线程不断在输出的excel文件中追加新记录。
周期性地写入记录,有助于在发生故障时,保持JVM的内存自由。
public class WebScrappingApp {
public static void main(String[] args) throws Exception {
...
File outFile = new File("C:\\temp\\webscrapping-output-"+ random.nextLong() +".xlsx");
Map<Integer, Object[]> columns = new HashMap<Integer, Object[]>();
columns.put(rowCounter++, new Object[] {"URL", "Title"});
ReportWriter.createReportFile(columns, outFile); //Create report one time
//periodically, append rows to report
ScheduledExecutorService es = Executors.newScheduledThreadPool(1);
es.scheduleAtFixedRate(runAppendRecords(outFile), 30000, 30000, TimeUnit.MILLISECONDS);
...
}
private static Runnable runAppendRecords(File file) {
return new Runnable() {
@Override
public void run() {
if(processedRecords.size() > 0) {
List<UrlRecord> recordsToWrite = new ArrayList<>();
processedRecords.drainTo(recordsToWrite);
Map<Integer, Object[]> data = new HashMap<>();
for(UrlRecord entity : recordsToWrite) {
data.put(rowCounter++, new Object[] {entity.getVisitedUrl(), entity.getTitle()});
}
System.out.println("###########Writing "+data.size()+" records to excel file############################");
try {
ReportWriter.appendRows(data, file);
} catch (IOException e) {
e.printStackTrace();
} catch (InvalidFormatException e) {
e.printStackTrace();
}
} else {
System.out.println("===========Nothing to write. Waiting.============================");
}
}
};
}
}
public class ReportWriter {
public static void createReportFile(Map<Integer, Object[]> columns, File file){
XSSFWorkbook workbook = new XSSFWorkbook();
XSSFSheet sheet = workbook.createSheet("URL Titles");
Set<Integer> keyset = columns.keySet();
int rownum = 0;
for (Integer key : keyset)
{
Row row = sheet.createRow(rownum++);
Object [] objArr = columns.get(key);
int cellnum = 0;
for (Object obj : objArr)
{
Cell cell = row.createCell(cellnum++);
if(obj instanceof String)
cell.setCellValue((String)obj);
else if(obj instanceof Integer)
cell.setCellValue((Integer)obj);
}
}
try
{
//Write the workbook in file system
FileOutputStream out = new FileOutputStream(file);
workbook.write(out);
out.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}
public static void appendRows(Map<Integer, Object[]> data, File file) throws IOException, InvalidFormatException {
XSSFWorkbook workbook = new XSSFWorkbook(new FileInputStream(file));
Sheet sheet = workbook.getSheetAt(0);
int rownum = sheet.getLastRowNum() + 1;
Set<Integer> keyset = data.keySet();
for (Integer key : keyset)
{
Row row = sheet.createRow(rownum++);
Object [] objArr = data.get(key);
int cellnum = 0;
for (Object obj : objArr)
{
Cell cell = row.createCell(cellnum++);
if(obj instanceof String)
cell.setCellValue((String)obj);
else if(obj instanceof Integer)
cell.setCellValue((Integer)obj);
}
}
try
{
FileOutputStream out = new FileOutputStream(file);
workbook.write(out);
out.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
5.演示
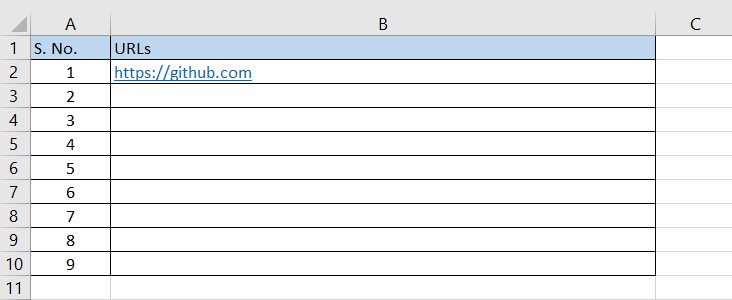
对于这个演示,在临时目录下创建一个输入的excel文件,如下所示。
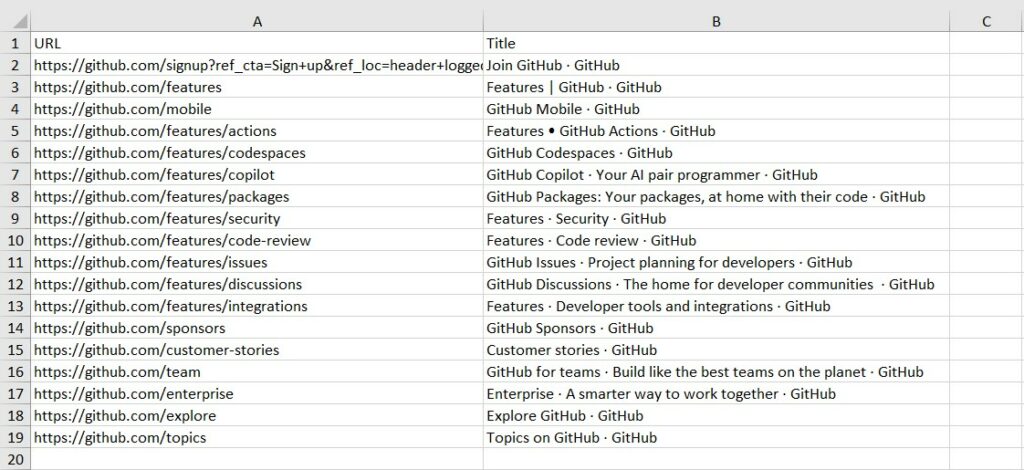
现在运行应用程序,注意在临时文件夹中生成的报告。
6.结语
在这个Java教程中,我们学习了如何创建一个网络搜刮器。我们学会了建立一个工作中的Web Scrapper所需的各种组件,尽管它还远远不够完美。你可以把这个案例作为一个起点,并根据你的需要对它进行定制。
学习愉快!!
这个帖子有帮助吗?
如果你喜欢这篇文章,请告诉我们。这是我们能够改进的唯一方法。
是的
没有
