

短文
几天前,我遇到了我的一个朋友。他对我和我的经历有几个问题。几乎所有的问题都与我最近做的工作有关。尽管这些问题来自不同的主题,但我发现自己对所有的问题都给出了几乎相同的答案。听起来就像,"使用干式结构"。之后,我记得我以前也给别人讲过类似的故事。这让我非常惊讶和焦虑,因为我意识到这个工具是多么重要和有用。不幸的是,我的一些朋友甚至不明白为什么这个工具会存在。
在这篇文章中,我试图为已经在寻求与我朋友相同信息的人揭示这些问题和答案。我还设定了一个目标,向不了解其动机的人展示dry-struct究竟能解决什么问题。我想说明为什么这个工具非常重要,为什么它是向Ruby世界中更舒适的开发过程迈出的一步。
问题和答案
1.Andrei,我听说你对GraphQL有经验。但你对它的态度是什么?我更喜欢JSON API,没有看到GraphQL的好处。
好吧,首先在比较它们之前,我们应该明白JSON只是一种指定数据的格式。通常这些数据应该从一个 "程序/服务/服务器/进程/什么的 "到另一个 "程序/服务/服务器/进程/什么的"。让我们同意 "程序/服务/服务器/进程/什么的 "是一个黑箱服务,它可以是后端或前端的进程,从现在开始我们只叫它进程。
注意,进程可以用不同的编程语言编写,因为JSON是语言无关的。基本上,这只是一组指定数据从流程A到流程B的规则(关于JSON的更多信息见rfc7159):

上图中的红色管道是一个负责数据传输的传输协议。而在这个管道内,一些数据以JSON格式进行交换。注意,协议可以是HTTP、RPC、AMQP等,甚至可以是同一进程中的方法调用!但是,在发送这个字符串之前,一个进程需要对这个字符串做适当的处理。
但是在发送这个字符串之前,一个进程需要从驻留在其内存中的对象中建立它。这个动作被称为序列化。此外,一个接收数据的进程需要在其内存中建立相应的对象回来。这个动作被称为反序列化。幸运的是,对于这些动作,几乎所有的编程语言都有现成的工具。Ruby和JavaScript在这里也不例外。
不幸的是,一个正确序列化的JSON并不能保证反序列化过程的正确运作。考虑一下下面的情况。有一个定义好的JSON数据{title: "A post", body: "Some text"} 。它现在对两个进程都很好:一个进程发送者自由地序列化它,一个进程接收者自由地反序列化它。流程本身在整合中正常工作,也就是说,它们说的是同一种语言。现在,发送方发生了一些变化,"标题 "字段自发地被重命名为 "名称"。对于动态编程语言,像这样的自发变化经常发生,特别是当数据是由一些 "魔法 "产生的时候(你好,Ruby!)。因此,数据结构隐含地改变为{name: "A post", body: "Some text"} 。现在,如果这些变化不一致,接收方会发生什么?当然,它会失败。在JavaScript的例子中,它处理数据时,在用户界面上显示一个空的标题,而不是预期的 "A post"。在任何情况下,一个无辜的变化都会引入一个错误。
如何防止这个问题?手动测试?当然,有可能手动测试一切。每当有什么变化时,需要有人运行相应的程序,看看它们是否能整合工作。如果只有两个进程,如Web应用程序,这也许是可以的 - 后端是Ruby,前端是JavaScript。打开浏览器,点击一下,这不是问题。但即使这样也不能保证没有退步。通常,有一些棘手的场景或不受欢迎的地方容易被遗忘,特别是当有缺失的测试场景时。很容易发现不了UI上的一个小东西,乍一看是正确的,但实际上是错误的。因此,需要有人阅读接收进程的代码,排除所有地方对旧名称的使用。
如果代码不多,而且没有很多进程,这可能是可以接受的。但如果有很多进程呢?例如,除了我们的Web UI之外,还有iOS、Android,有数百个版本,等等。每个过程都有一个独立的负责人/团队。那么这个简单的检查回归的任务就会变成一个不痛不痒的漫长活动。这导致了不必要的沟通和人工测试的肉体的猴子行为。
最终,手工测试并不能保证什么,因为总是有机会错过什么。记住,上面的例子中的变化是自发发生的。根本没有人知道数据中的这个变化!在没有人工测试的情况下,很容易错过这个错误并部署到生产中。
这是Rails世界中的一个典型案例:一个字段在表上被重新命名,单元测试被运行并且是绿色的,代码在后端被读取,并且保证没有任何东西在后端使用旧字段。部署到生产中,打开浏览器,哎呀 :(
集成测试可以解决这个问题,如果它们涵盖了与变化有关的代码。这是一个更强大的方法,精心编写的方案可能完全解决这个问题。不过,集成测试也有缺点。首先,它们运行得太慢。这就是为什么他们可能会影响开发周期。第二,由维护、CI时间和实施组成的高成本。尽管有这些障碍,但这是一个具有生产部署的应用程序的一个非常重要的部分。它可以帮助我们自信地进行代码修改,而不会给业务带来损害。
但也有可能减少成本。如果流程之间通过一些合同进行对话,那么违反合同就意味着集成立即被破坏:
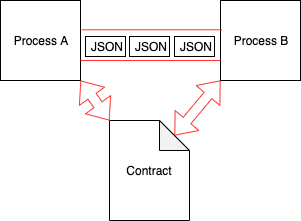
这里的合同是一些对两个进程都能理解的规范。如果数据在序列化或反序列化过程中不符合合同的规定,它就会立即失效。
这里GraphQL开始发挥作用。重点是,它有一个类似于开箱即用的合同的实现。它被称为 "模式"。不可能生成或接收不符合模式的数据。如果模式参与了单元测试,那么烟雾测试就足以确保集成工作。而且这些测试要便宜得多。
这并不是GraphQL开箱即用所解决的唯一问题。模式实际上是所有可能的字段的集合,它们相互连接。GraphQL的所有魅力在于,一个接收过程可以只指定它所需要的那些数据,不多不少。而且,对于所有这些,只有一个端点,而不是一个有着奇怪名字的森林REST端点。
在我看来,这里的赢家是GraphQL。对于一个可持续的相对较大的应用程序,强烈推荐使用它。但对于MVP或PoC,它可能是多余的。
有人可能会说,还有其他普遍接受的方法来构建这样的合同。Pact、JSON-schema、Swagger,以及其他。但它们与GraphQL有着微妙的不同。它们是通过在已经很复杂的堆栈中增加一种更复杂的技术来解决JSON的问题。有了GraphQL,我们就有了一种技术(虽然不是一种简单的技术),内置了所有必要的东西。
对于那些相信这是一项值得关注的技术的人来说,有一个正式的地方可以开始。
好吧,但这一切与dry-struct有什么关系?事实证明,用dry-struct定义的结构也是一种模式。它有已知类型的字段和它们之间的连接,类似于GraphQL。它很容易将数据序列化为JSON并从JSON中反序列化。
最终意味着,dry-struct可以像GraphQL一样被用于进程之间的通信。但有一点需要注意的是。两端都应该用Ruby编写。这样就有可能在发送/接收进程之间共享dry-struct,从而使传输的数据可以很容易地与模式进行验证。否则,我们需要在一个定义了干式结构的地方(当然是在Ruby中)和一个不能重用Ruby定义的地方之间同步一个干式结构模式。为了实现这种同步,应该有一些工具将dry-structschema转换为其他语言支持的常用格式。
简而言之,GraphQL和dry-struct是允许在进程之间定义一个严格的API的工具。有了严格的API,维护代码和添加新功能就更容易了。我所说的严格是指对代码中的变化的可能性或不可能性的即时反馈。
现在,考虑只有一个Ruby进程,内部方法调用被用于数据交换。当一个单一的应用程序被分割成孤立的模块,通过一些 "远程 "协议进行通信时,这种情况是可能的。在这种情况下,由dry-struct指定的结构可以被用作API模式和契约,JSON可以被用作数据传输格式。
根据我的经验,在一个项目中是这样实现的:
- 干结构被定义在 "存储库1 "中
- "存储库2 "和 "存储库3 "只是将 "存储库1 "作为依赖的Ruby应用程序,因此,"模式 "的任何变化都应该在这些存储库中得到调整
- 为了方便,所有的 "仓库 "都保存在一个git仓库中,这样。
- 在模式改变后,可以很容易地一次性搜索所有的代码并发现需要改变的地方
- 不需要手动更新对 "资源库2 "和 "资源库3 "的依赖。
但这还不是全部。如果只是一个只调用内部方法的Ruby进程,dry-struct可以作为一个值对象使用。同样,由于结构是严格的,我们可以谈论一个可靠的内部API。这与类型化语言的尊重几乎是一样的。
2.对于验证、准备和处理来自另一个进程的参数,你的偏好是什么?
dry-schema是我在这里的主要偏好。它和dry-struct一样,有相同的基础,即dry-types,有相同的理念,但有更漂亮的DSL和API来验证参数。另外,它对初学者来说更容易。
我不喜欢把验证和回调放在模型层。模型可以在不同的环境中使用,不需要一些回调或验证。因此,在这些上下文中定义回调和验证是合理的,而不是把意大利面条放在一个地方。不过,如果一些验证在所有上下文中都是真实的,那么把它们留在模型层也是合理的。如果遵循这一规则,代码将变得更容易维护和扩展。
请看这个片段来感受这个想法:
PostSchema = Dry::Schema.Params do
required(:title).filled(:string)
optional(:body).filled(:string)
end
class CreatePostOperation
def initialize(params)
@params = PostSchema.call(params)
end
def peform
raise ParamsError.new(params.errors.to_h) unless params.success?
Post.create(params.to_h)
end
end
PostSchema 是接收进程和另一进程之间的合同,发送参数。这个合同规定了一系列的规则,比如:
- 必需和可选字段
- 这些字段的类型
- 根据指定的类型自动强制给定参数
- 如果一个参数有一个错误的类型,或者一个不可能被打成指定类型的值,它将被视为一个验证错误。
注意,除了参数验证,我们还可以免费获得可管理的类型转换。这里所说的可管理,是指无需猴子补丁即可添加自定义强制规则或类型的官方可能性。请记住,Rails并没有这种可能性。
CreatePostOperation 应该被用于负责处理来自其他进程的请求的控制器中。它的实现在这里被简化了很多,只是为了提供一个想法。在现实中,像这样的操作有更多需要注意的地方,比如:
- 打开DB事务或不在
#perform - 在没有异常的情况下轻轻退出,提供一个接口来获取错误信息
- 绕过模型层中的错误。记住,上面的
Post模型仍然可以有验证,或者在DB层面上可能有约束。 - 捕获特定的异常,并从那里提取错误,通过类似于模型验证的接口暴露出来。
- 其他。
3.我对dry-struct很熟悉,但它不能从我的对象中序列化数据。你如何序列化到dry-struct中?
这是真的,dry-struct没有这个功能,开箱即用。但这并不是什么大问题,因为它很容易实现:
class BaseStruct < Dry::Struct
def self.to_hash(object, type = self)
type.schema.each_with_object({}) do |key, res|
name = key.name
attr = key.type
if array?(attr)
values = ::Array.wrap(object.public_send(name))
res[name] = values.map { |value_item| serialize(value_item, attr.member) }
elsif bool?(attr)
value = object.public_send("#{name}?")
res[name] = value
else
value = object.public_send(name)
res[name] = serialize(value, attr)
end
end
end
private
def serialize(object, type)
complex?(type) ? to_hash(object, type) : object
end
def complex?(attribute)
attribute.respond_to?(:<) && attribute < BaseStruct
end
def bool?(attribute)
attribute.primitive?(true)
end
def array?(attribute)
attribute.primitive?([])
end
end
class Types
include Dry.Types()
end
class PostStruct < BaseStruct
attribute :title, Types::String
attribute :body, Types::String.optional
end
这里的主函数是BaseStruct.to_hash ,你可能已经猜到了。它只是一个递归函数,遍历所有定义的属性。只要开始使用它:PostStruct.to_hash(Post.last).to_json 。请注意,序列化对象应该已经定义了结构上指定的所有方法。在这个例子中,结构上定义了title 和body 属性,因此Post 实例应该响应这两个方法并返回指定类型的值。
注意,复杂的属性应该像这样继承自BaseStruct:
attribute :metadata, BaseStruct do
attribute :writer_id, Types::Integer
attribute :created_at, Types::Time
end
要了解全貌,请看如何反序列化的例子:
PostStruct.new(JSON.parse(params))
另外,对于已经尝试过dry-schema或dry-struct的人还有一个建议。乍一看,它们可能因为类型的多样性而显得很可怕。那里的所有类型都不像Ruby那样存在于全局范围内。例如,在Ruby中,有String ,仅此而已,它在任何地方都是String 。在dry-struct/dry-schema中,类型与组有关。nominal,strict,coercible,params,json,maybe 。关于这一点的更多信息在这里。它们之间的区别在于它们的严格程度以及自动类型转换是否可能。
对于JSON序列化和反序列化,我们需要严格和可强制的类型。但并不是所有默认的dry-struct类型都满足这些要求。例如,没有严格的和可强制的Date 出来。幸运的是,我们可以将它们结合起来:Date = Strict::Date | JSON::Date 。而如果把这段代码放在上面的Types 类下,我们可以得出以下优雅的代码:
class Types
include Dry.Types()
Date = Strict::Date | JSON::Date
Symbol = Strict::Symbol | JSON::Symbol
Time = Strict::Time | JSON::Time
Decimal = Coercible::Decimal
end
而现在Types:: 空间下的所有类型都是严格的和可强制的。在指定属性时,我们不应该担心从哪个组中抽取一个类型。
4.4.Ruby的调试是一个痛苦的过程。你能推荐一些东西来减少在这方面花费的时间吗?
当然,我可以。使用dry-struct!说真的,代码中严格定义的结构使它更易读,从而大大减少调试时间。哪种类型被使用,在哪里使用,在第一次看完代码后,几乎马上就能明白。如果接收这些结构的方法的签名被记录下来,我们几乎可以得到开箱即用的静态类型语言。因此,我们从两个世界中受益:动态和静态。
YARD格式的方法签名文档的例子:
# @param post_params [PostStruct]
def publish(post_params)
顺便说一下,仅仅记录方法签名是好的。但从业务角度记录方法本身也会带来很多好处。如果你还没有记录你的代码,我邀请你开始这么做。你会看到你是如何成为一个更好的开发者的。
结论
Dry-rb生态系统是巨大的。在这篇文章中,我们只接触了其中的一部分。dry-struct,dry-schema, 和隐含的dry-types 。我希望你已经看到了这些工具给Ruby世界带来的好处。简而言之,它们借用了静态编程语言中缺少的部分--类型。这使得在Ruby中编程更加舒适和自信。因此,它减少了错误和调试时间方面的痛苦。
