

Scikit Learn KNN简介
Scikit learn KNN非常简单易懂,它是机器学习中最顶级的算法。KNN只不过是k近邻算法,它被用于各种应用,如医疗、金融、图像识别和视频识别。KNN算法被用于回归和分类问题,KNN算法在任何应用中都是基于特征相似性的方法。
主要启示
- KNN算法是一种有监督的机器学习算法,用于分类和回归任务。
- 有监督的机器学习算法取决于标记的输入数据,算法从这些数据中学习并用于产生未标记数据的正确输出。
什么是Scikit Learn KNN?
Sklearn KNN根据学习方法为有监督和无监督的邻居提供功能。无监督学习方法是其他学习方法的基础,特别是频谱聚类和光谱聚类。监督学习分为两种情况,一种是连续标签的回归,一种是离散标签的分类。最近的邻居的原则是找到预定的训练数量。样本的数量是恒定的,这是用户定义的,或者它可以根据密度变化。
一般来说,我们可以测量距离。scikit learn中基于邻居的方法被称为非广义机器学习的方法,训练数据被转换为KD树。尽管KNN方法很简单,但它在大量的回归和分类问题上都很成功。
scikit learn neighbors的类别是通过使用numpy数组或使用稀疏度量作为输入来处理的。对于密集的矩阵,支持大距离度量。按照非参数方法,这是一个成功的情况,我们可以定义决策边界。只有依靠近邻的核心的学习程序。
如何使用Scikit Learn KNN?
分类器中的k名称将代表最近的邻居,其中k是一个由用户指定的整数值。根据名称,这个分类器将实现最近的邻居算法。为了使用scikit learn KNN,我们需要遵循以下步骤。
1.在第一步中,我们将导入数据集名称为虹膜,如下所示。我们从sklearn.datasets库中导入同样的数据,如下所示。
代码
from sklearn.datasets import load_iris
输出

2.在加载数据集库后,在这个例子中,我们将加载虹膜数据集并定义KNN变量,如下所示:
代码
knn = load_iris()
print (knn.feature_names)
输出

3.导入虹膜数据集后,在这一步中,我们要打印数据集的目标,如下所示。
代码
print (knn.target)
输出

4.在下面的例子中,在打印完目标后,我们要打印数据集的目标名称,如下所示: 代码
print (knn.target_names)
输出
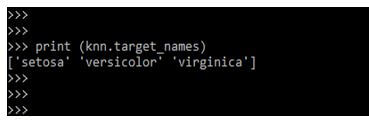
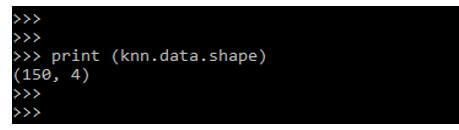
5.在下面的例子中,我们正在检查观察值和特征的数量,如下所示:
代码
print (knn.data.shape)
输出
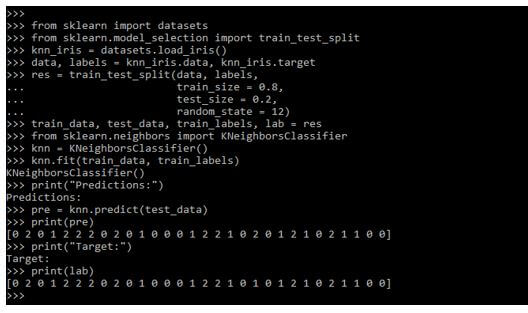
6.下面的例子显示了我们如何使用和创建近邻分类器,如下:
代码
from sklearn import datasets
from sklearn.model_selection import train_test_split
knn_iris = datasets.load_iris()
data, labels = knn_iris.data, knn_iris.target
train_data, test_data, train_labels, lab = res
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit (train_data, train_labels)
print("Predictions:")
pre = knn.predict (test_data)
print (pre)
print ("Target:")
print (lab)
输出
Scikit Learn KNN是如何工作的?
KNN就是最近的邻居,邻居是一个核心决定因素。k邻居是一个核心决定因素,在KNN中,如果类的数量是两个,一般是一个奇数。在k为1的时候,那么同样的算法被称为最近的邻居算法。
下面的例子显示了KNN是如何工作的:
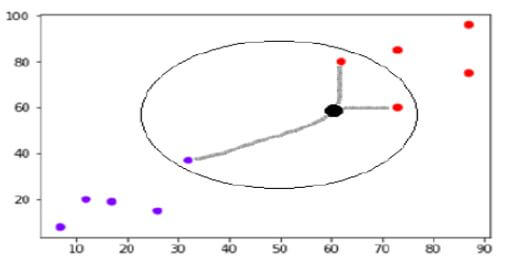
假设p1是我们要预测的标签的一个点,那么首先我们需要找到哪个是离p1最近的点,然后我们需要对大多数的k个邻居进行分类。每个对象都在为类别投票,而类别则为预测投票。为了找到最接近的点,我们需要使用测量方法来找到点之间的距离。
Scikit学习KNN包含以下步骤:
- 计算距离
- 寻找最接近的邻居
- 标签投票
下面的例子显示了KNN将如何工作,如下所示。在下面的例子中,我们正在加载虹膜数据集:
代码
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(train_data, train_labels)
print("Predictions:")
predict = knn.predict(test_data)
print(predict)
print("Target val:")
print(lab)
输出
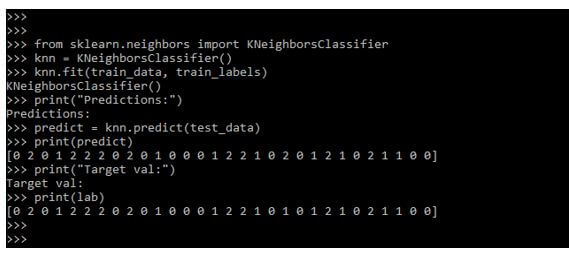
Scikit Learn KNN分类器
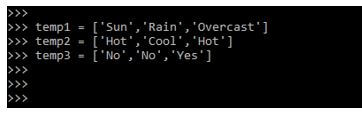
为了定义数据集,我们需要在我们的数据标签和特征中定义两类属性。下面的例子显示了如何创建一个数据集。
代码
temp1 = ['Sun', 'Rain', 'Overcast']
temp2 = ['Hot', 'Cool', 'Hot']
temp3 = ['No', 'No', 'Yes']
输出
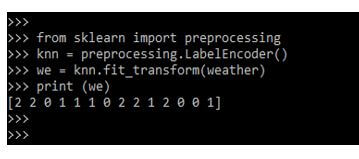
在下面的例子中,我们正在定义编码数据列。各种算法都需要数字数据,它代表了分类和数字列,如下所示:
代码
from sklearn import preprocessing
knn = preprocessing.LabelEncoder()
we = knn.fit_transform(weather)
print (we)
输出
现在我们通过使用zip函数将特征和多列组合成一个单一的集合,如下所示。
代码
te = knn.fit_transform (temp)
label = knn.fit_transform(play)
features = list(zip(we, te))
输出

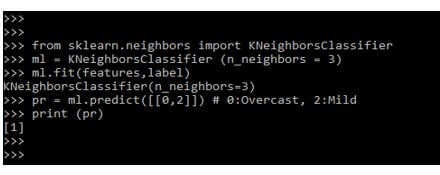
在下面的例子中,我们正在建立KNN分类器模型,具体如下。我们首先通过传递参数号导入KNN分类器的对象,如下所示。
代码
from sklearn.neighbors import KNeighborsClassifier
ml = KNeighborsClassifier (n_neighbors = 3)
ml.fit (features,label)
pr = ml.predict ([[0,2]]) # 0:Overcast, 2:Mild
print (pr)
输出
在下面的例子中,我们已经创建了KNN分类器,我们也在用KNN创建多个标签,如下所示。在下面的例子中,我们正在加载葡萄酒数据集。
代码
from sklearn import datasets
knn = datasets.load_wine()
输出
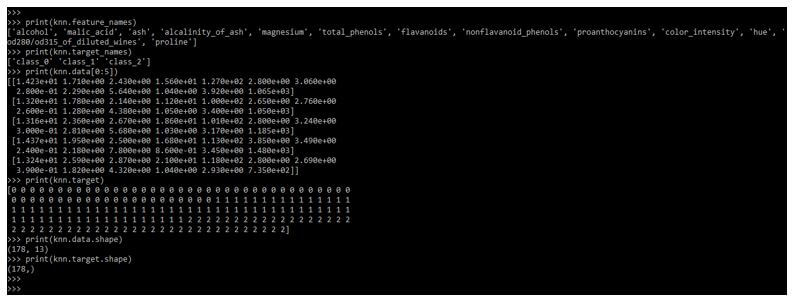
在下面的例子中,创建了多重标签后,我们正在探索数据,如下所示:
代码
print(knn.feature_names)
print(knn.target_names)
print(knn.data[0:5])
print(knn.target)
print(knn.data.shape)
print(knn.target.shape)
输出
在下面的例子中,我们正在对数据进行分割,并使用k=5的值建立KNN分类器:
代码
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
knn1 = KNeighborsClassifier (n_neighbors=5)
knn1.fit (X_train, y_train)
y_pred = knn1.predict(X_test)
输出
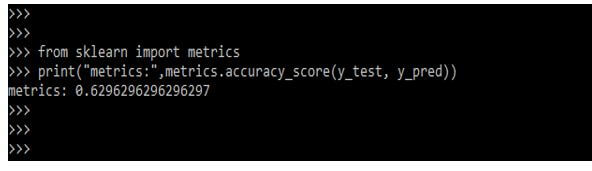
现在在下面的例子中,我们要找出KNN分类器的准确度,如下所示:
代码
from sklearn import metrics
print("metrics:",metrics.accuracy_score (y_test, y_pred))
输出
参数
下面是scikit learn k近邻的参数,如下。KNN包含多个参数:
- **n_neighbors -**这个参数的默认值是5,类型是int。这定义了一个邻居的数量。
- **权重 -**这个参数的默认值是统一的。它用于预测。
- **算法 -**这个参数的默认值是自动。
- **leaf_size -**这个参数的默认值是30,类型是int。如果传递给KD树的叶子大小。
- **p -**这个参数的默认值是2,类型是int。这定义了功率参数。
- **Metric -**这个参数的默认值是Minkowski。这定义了用于距离计算的度量。
- **metric_params -**这个参数的默认值是无。这些是额外的参数。
- **n_jobs -**这个参数的默认值是无,类型是int。
常见问题
下面是提到的常见问题:
Q1.scikit learn KNN在python中的用途是什么?
答:KNN是一种简单的分类算法。 KNN是一种简单的分类算法,我们可以用它来给一个新的数据点分配一个类别。
Q2.在python中使用scikit learn KNN时,我们需要使用哪些库?
答:我们需要使用sklearn库。 我们需要使用sklearn库,在使用scikit learn KNN时需要导入数据集。
Q3.KNN分类器的用途是什么?
答:我们需要创建KNN分类器。 在python中使用k近邻算法时,我们需要创建KNN分类器。
结论
KNN只不过是k近邻算法,它被用于各种应用,如医疗、金融、图像识别和视频识别。尽管它很简单,但KNN方法在许多回归和分类问题上是有效的。
