

该 recover()是Go中的一个内置函数,用于停止由调用 panic()函数所调用的程序中止序列。它恢复了应用程序的正常执行,并允许处理传递给 panic().换句话说。 recover()"捕获 "panic-类型的错误,并允许你处理它们,而不是终止应用程序。
恐慌和推迟
该 recover()密切配合 panic()函数和 defer语句密切配合:
语句 panic()函数在Go中用来报告应用程序中无法恢复的状态,使其无法继续运行。一般来说,应用程序中的这种状态有两类来源:
- 缺少对应用程序运行所需资源的访问。例如,在一个更新数据库中数据的应用程序中,数据库连接错误导致应用程序无法继续运行。在这种情况下,你应该等待访问,或者明确地以不可恢复的错误终止应用程序,使用
panic()函数明确地终止应用程序。 - 导致运行时错误的编程错误,如索引一个片断超出了范围。它们会自动触发
panic()并终止应用程序。
一个玩具例子显示了该 panic()函数在应用程序缺乏资源访问的情况下是如何工作的:
| |
输出:
panic: error while connecting to db
goroutine 1 [running]:
main.main()
main.go:15 +0x49
exit status 2
在这个例子中,connectToDB() 函数总是返回一个错误,我们用它作为参数给 panic().结果,main() ,打印"connected to db" 字符串的最后一行从未被执行,因为程序提前启动了恐慌序列,结果是将错误记录到标准输出,并终止了应用程序。
为了定义什么是 恐慌序列是什么以及它是如何工作的,我们必须首先了解更多关于 defer语句。
该 defer语句确保一个函数在周围的函数返回后被执行(调用defer 的那个)。不管周围的函数是在没有错误的情况下结束,还是被恐慌打断,这都不重要。该 defer保证这个关键字后面的函数将被执行。
看一下这个例子:
| |
如你所见,我们调用了三个函数的序列。main() 函数调用foo() ,然后调用bar() ,而bar() 则调用baz() 。在每一个函数中,我们打印出字符串"Hello <function-name>" ,并在第一行声明延迟函数,它应该打印出字符串"Bye <function-name>" 。在这三个函数分别调用后,我们打印字符串"After <function-name>" 。此外,baz() ,调用字符串"panic in baz" 的恐慌。
程序在输出端打印了以下结果:
Hello foo
Hello bar
Hello baz
Bye baz
Bye bar
Bye foo
panic: panic in baz
goroutine 1 [running]:
main.baz()
main.go:20 +0xb8
main.bar()
main.go:14 +0xaa
main.foo()
main.go:8 +0xaa
main.main()
main.go:24 +0x17
exit status 2
在开始时,一切都像预期的那样--foo() 、bar() 、baz() 函数被逐一执行,并打印出"Hello <function-name>" 信息。在baz() 函数中,出现了恐慌,但在输出中并不立即可见。相反,baz(),bar() 和foo() 依次调用递延函数,省略了"After <function-name>" 字符串的打印。
这就是 panic()的工作原理--它启动 恐慌序列立即停止当前函数的执行,并开始解开当前的goroutine函数栈,沿途运行任何延迟的函数。如果这个解开的过程到达堆栈的顶部,就会记录下恐慌,程序就会死亡。
下图显示了如何在 panic()函数和 defer语句在我们的例子中是如何工作的。
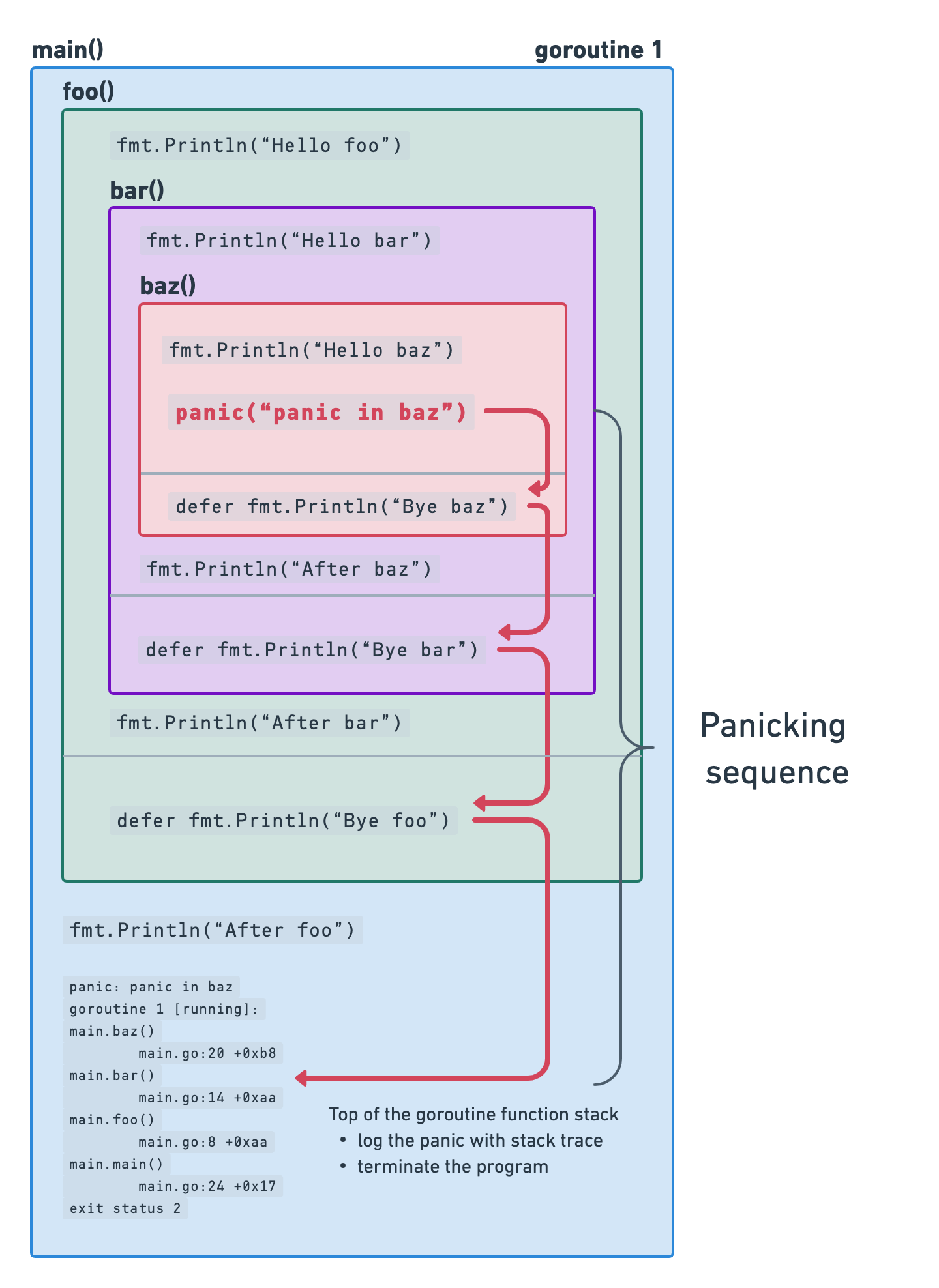
因此,作为恐慌序列的结果,我们可以看到调用到 defer语句函数,打印"Bye <function-name>" 信息。在恐慌过程中,除了在defer 语句中,程序没有调用任何其他函数--它没有打印出"After <function-name>" 字符串。恐慌本身是在最后到达函数堆栈的顶部时被记录下来的。正因为如此,你可以看到这个日志和堆栈跟踪作为输出的最后一条信息。
当然,正如我们在开始时提到的,无论恐慌是否发生,该 defer语句是有效的,无论程序中是否发生恐慌。要检查这一点,请将 panic()并跟踪输出。当然,这也是反过来的,这意味着你在调用时也不需要使用 defer当调用 panic().
从恐慌中恢复
有时你可能想让惊慌失措的人中止,应用程序返回到正常执行,整个解开goroutine函数栈和终止应用程序的序列停止。这就是内置 recover()函数的作用。
该 recover()通过停止慌乱的序列来恢复程序的正常执行。它返回传递给调用的错误值。 panic()的调用,如果goroutine没有恐慌,则返回nil 。
该
panic()可以接受任何值作为参数,所以recover()也会返回类型为any的值。从Go 1.18开始。any是interface{}的一个别名。
该程序在任何情况下都是有用的。 recover()在任何情况下都是有用的,在这种情况下,一次恐慌不应该终止整个程序。例如,网络服务器客户端连接中的一个关键错误不应该使服务器应用程序崩溃。
它也用于处理递归函数栈中的错误。如果在调用此类函数的某一层发生错误,通常需要在顶部处理。要做到这一点,报告panic以解开堆栈到顶层的函数调用,然后 recover()从恐慌中处理错误。
当你存储你的应用程序日志时,在 recover()也可以用来捕获一个恐慌,并将恐慌信息保存到存储区。
既然你已经知道什么是 recover()是什么以及它是如何工作的,现在是时候展示一个如何使用它的例子了。
下面的程序与前面的程序相同,只是这次我们在baz() 函数中从恐慌中恢复:
| |
输出:
Hello foo
Hello bar
Hello baz
Bye baz
RECOVERED: panic in baz
After baz
Bye bar
After bar
Bye foo
After foo
在baz() 的第一行,有一个延迟的恐慌恢复函数recoverPanic() ,它检查了 recover()返回一个非零的结果。如果是,那么恐慌参数将被打印到标准输出,前缀为RECOVERED: 。
在输出中,你可以看到应用程序确实已经恢复了恐慌,因为它回到了正常的执行状态,并打印了字符串"After baz","After bar", 和"After foo" 。
我们的示例程序现在看起来像图中这样:
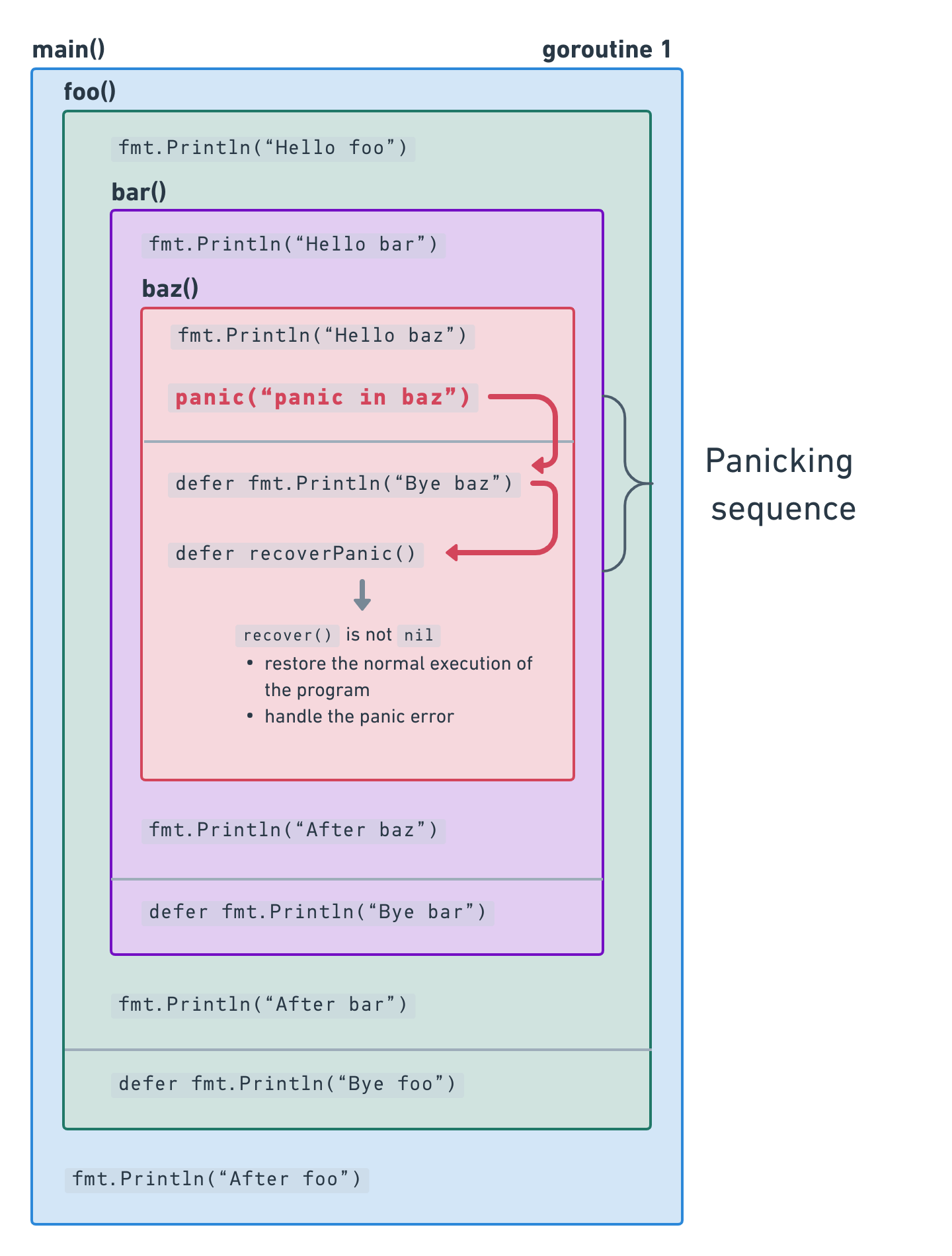
你可能会想,为什么我们要把 recover()在一个延迟函数中调用baz() 。好吧,这是在使用 recover()函数时的第一条规则。
该 recover()只在递延函数中工作。
这是因为在返回到调用者的恐慌序列中,唯一运行的代码是递延函数,所以 recover()将不会在其他地方运行。
第二条规则是:
该 recover()只在同一个goroutine中工作,而在这个goroutine中 panic()被抛出的地方。
看一下这个例子:
| |
输出:
deferred from bar
panic: panic in bar
goroutine 6 [running]:
main.bar()
recover/main.go:14 +0x73
main.main.func1()
recover/main.go:20 +0x17
created by main.main
recover/main.go:19 +0x45
exit status 2
在main() ,我们声明调用延迟函数barRecover() ,它从恐慌中恢复过来。然后,我们在一个新的单独的goroutine中调用了恐慌的bar() 函数。正如你在输出中看到的,恐慌没有被恢复,因为它是由一个新的goroutine调用的,而 recover()是在主goroutine中。在图中,它看起来像这样。

当你在一个新的goroutine中替换bar() 的调用:
| |
用一个正常的调用来代替:
| |
那么恐慌将被恢复,你将看到的输出将是这样的:
deferred from bar
RECOVER: panic in bar
作为一个经验法则,记住这个方案,你只能在与主程序相同的goroutine中调用 recover()在同一个goroutine中调用 panic().这将为你节省大量的调试时间。
结论
该 recover()函数是Go中一个很好的机制,可以避免在发生不可恢复的错误时杀死应用程序,并处理这些错误,使应用程序可以继续运行。综上所述,你应该记住这个函数的3个最重要的东西:
