

本文已参与「新人创作礼」活动,一起开启掘金创作之路。
在我将idea升级到最新版本后,再在项目中使用mapstruct会报空指针。
方法一 -- 坚持使用旧版mapstruct
需要在idea的编译选项中加入:-Djps.track.ap.dependencies=false,禁止跟踪注解处理器内部依赖项集合,从而使得IDEA的增量编译语言规则在这部分无效。
如下设置,即可解决问题:
方法二 -- 升级mapstruct
github.com/mapstruct/m… 更新mapstruct,最低要1.4.1版本:
- 【core】mvnrepository.com/artifact/or…
- 【processor】mvnrepository.com/artifact/or…
值得注意的是,一定要确保mapstruct和mapstruct-processor都更新到 1.4.1.Final,否则可能不生效。
比如,maven项目中的某些依赖还依赖了旧版mapstruct,需要一个一个找出来并exclusion。(如果觉得很麻烦,推荐直接用方法一)
<exclusion>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct</artifactId>
</exclusion>
感兴趣的可以接着看
增量编译
 在我们整个项目编译后,修改了部分代码。我们点击idea的编译,并非会把项目所有源代码编译,只会编译修改的部分,可以节约开发者很大一部分时间。这就是idea的增量构建。
缺点也有,我们的源代码.java并不是所有都是独立的,他们直接由互相引用、关联,在修改了部分源代码会引起其他的连锁反应。因此,为了解决这个问题,idea又使用到了wrapper接口(原理:javax.annotation.processing.ProcessingEnvironment)记录processor曾经生成的所有类或资源,对其进行过滤,对所有被影响到的源文件全部重新编译,以保证编译结果的正确性(过于复杂,并非一定有效,也因此我们有时候需要删除整个target重新编译)。
在我们整个项目编译后,修改了部分代码。我们点击idea的编译,并非会把项目所有源代码编译,只会编译修改的部分,可以节约开发者很大一部分时间。这就是idea的增量构建。
缺点也有,我们的源代码.java并不是所有都是独立的,他们直接由互相引用、关联,在修改了部分源代码会引起其他的连锁反应。因此,为了解决这个问题,idea又使用到了wrapper接口(原理:javax.annotation.processing.ProcessingEnvironment)记录processor曾经生成的所有类或资源,对其进行过滤,对所有被影响到的源文件全部重新编译,以保证编译结果的正确性(过于复杂,并非一定有效,也因此我们有时候需要删除整个target重新编译)。
举例:
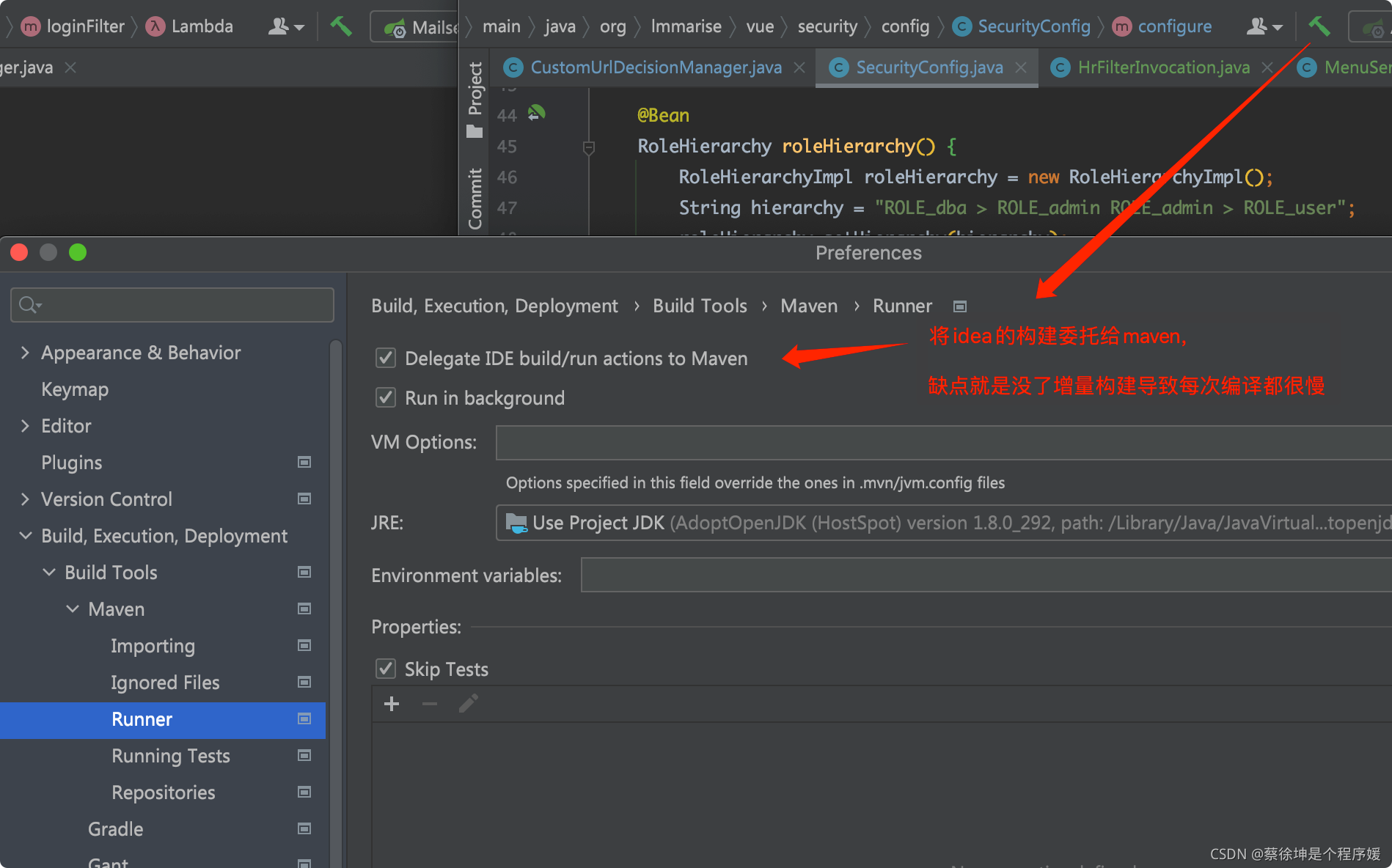
读者可自行将idea的构建委托给maven,以尝试idea的增量构建的好处。当然偶尔idea会莫名其妙的抽风,此时委托给maven来构建也不失为一个解决方法。
注解处理器
在编译期对注解进行处理的一系列API,注解处理器可以根据任何类型的可见的元素,生成新的源文件/字节码。
问题原因
问题就出现在,mapstruct能处理编译,idea也能处理编译。
就是这次更新IDEA对编译期的优化做了部分改动(俗称feature),导致mapstruct的org.mapstruct.ap.internal.processor.DefaultVersionInformation.getLibraryName在和IDEA构建过程中,在此环境下拿到NULL,并操作空指针了(就是个NPE bug)。
解决方法原理
默认是jps.track.ap.dependencies=true,改为false后,idea的增量编译不再跟踪处理MapStruct的注解处理器的依赖部分。
综上,上面两种解决方法,其实就是将问题的解决转变为是由IDEA还是mapstruct来处理这个空指针的问题。
PS:这个bug可以认为是idea开发者的,也可以认为是MapStruct开发者的,不过我们日常对NPE的处理更偏向于接收者来做,而不是提供者;这个锅可能在MapStruct。
问,如果禁用注解处理器指定的依赖项集合,那IDEA的增量编译优化还有效吗?是否会影响IDEA的增量编译的正确性?
主要还是看MapStruct是怎么工作的。
MapStruct 对注解的处理原理:根据MapStruct的注解生成中间 *.java 文件。因此,因为又生成了新的java文件,在这种情况下增量编译应该还是正常工作的。
