

持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第26天,点击查看活动详情
2 快速搞定 Kafka 术语
- 消息:Record。Kafka 是消息引擎嘛,这里的消息就是指 Kafka 处理的主要对象。
- 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
- 分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
- 消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
- 副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
- 生产者:Producer。向主题发布新消息的应用程序。
- 消费者:Consumer。从主题订阅新消息的应用程序。
- 消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
- 消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
- 重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
Kafka 体系架构 = M个
producer+ N个broker+ K个consumer+ZK集群
基础架构
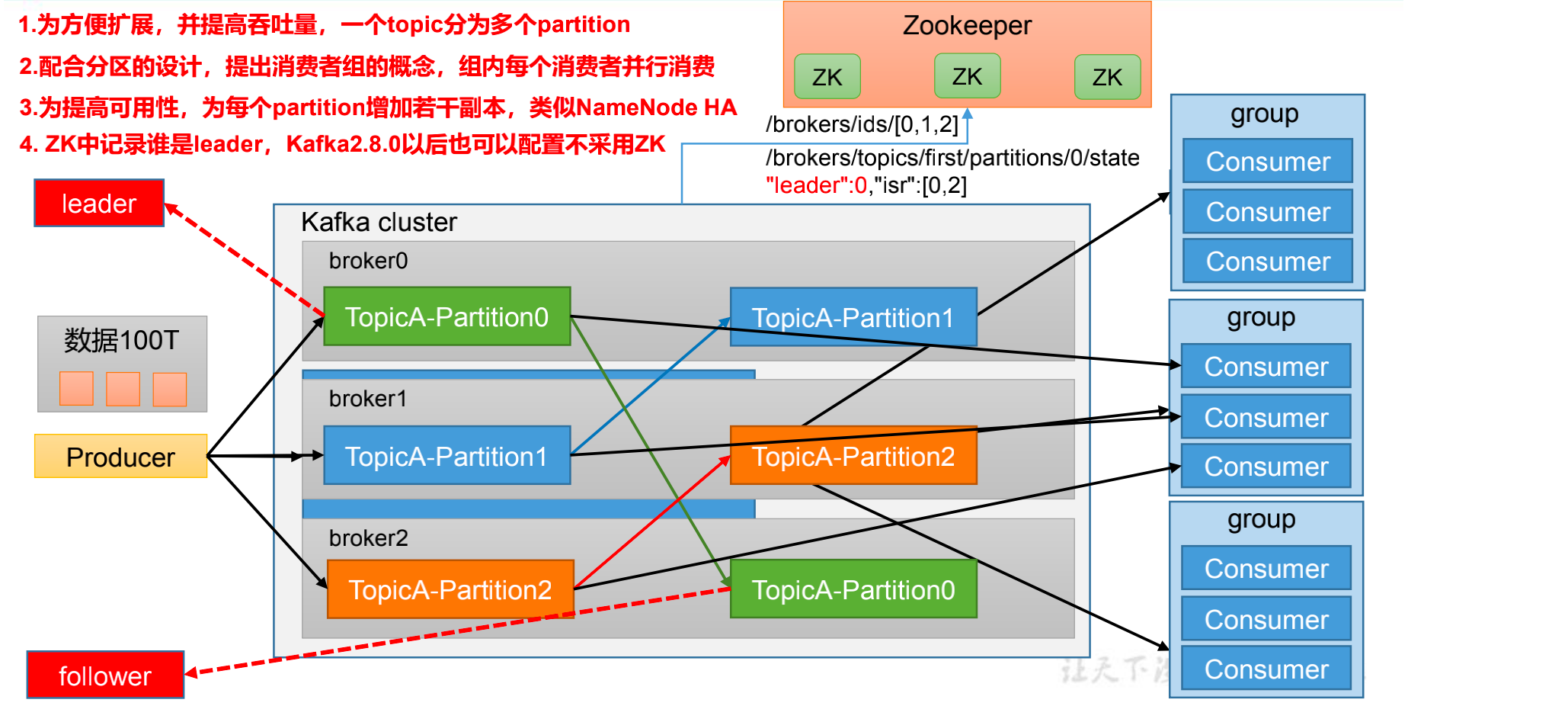
-
Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
-
Consumer:消息消费者,向 Kafka broker 取消息的客户端。
-
Consumer Group(CG):消费者组,由多个 consumer 组成。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;
- 消费者组之间互不影响。
- 所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
-
Broker:一台
Kafka服务器就是一个broker。- 一个集群由多个 broker 组成。一个
broker可以容纳多个topic。
- 一个集群由多个 broker 组成。一个
-
Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
-
Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
-
Replica:副本。一个 topic 的每个分区都有若干个副本,一个
Leader和若干个Follower。 -
Leader:每个分区多个副本的“主” ,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
-
Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个Follower 会成为新的 Leader。
3 Kafka只是消息引擎系统吗?
Apache Kafka 是消息引擎系统,也是一个分布式流处理平台(Distributed Streaming Platform)。
4 我应该选择哪种Kafka?
-
Apache Kafka(社区版 Kafka)
- 优势在于迭代速度快,社区响应度高,使用它可以让你有更高的把控度;
- 缺陷在于仅提供基础核心组件,缺失一些高级的特性。
-
Confluent Kafka(Confluent 公司提供)
- 优势在于集成了很多高级特性且由 Kafka 原班人马打造,质量上有保证;
- 缺陷在于相关文档资料不全,普及率较低,没有太多可供参考的范例。
-
CDH/HDP Kafka(大数据云公司提供的 Kafka,内嵌 Apache Kafka)
- 优势在于操作简单,节省运维成本;
- 缺陷在于把控度低,演进速度较慢。
-
推荐的监控工具
- 试试JMXTrans + InfluxDB + Grafana
- 一个是 kafka tools ,能够清晰的看到kafka存储结构。一个是 granafa,能看到消费的折线图。
- 滴滴开源github.com/didi/Logi-K…,是目前市面上最好用的一站式 Kafka 集群指标监控与运维管控平台。
5 聊聊Kafka的版本号
-
Kafka 版本命名:大版本号 - 小版本号 - Patch 号,如 kafka-2.11-2.1.1
- 2.11是
Scala编译器版本 - 真正的
Kafka版本号实际上是 2.1.1- 前面的 2 表示大版本号,即
Major Version;中间的 1 表示小版本号或次版本号,即Minor Version;最后的 1 表示修订版本号,也就是Patch号。
- 前面的 2 表示大版本号,即
- 2.11是
-
Kafka 版本演进
- 0.7版本:只提供最基础的消息队列功能
- 0.8版本
- 引入了副本机制(成为了一个真正意义上完备的分布式高可靠消息队列解决方案)(较好地做到消息无丢失)
- 0.8.2.0 版本社区引入了新版本
Producer API,即需要指定 Broker 地址的 Producer
- 0.9版本
- 增加了基础的安全认证 / 权限功能,Java重写了新的consumer API;(不建议使用consumer API)
- 引入了 Kafka Connect 组件用于实现高性能的数据抽取;
- 0.10版本(里程碑式的大版本)
- 引入Kafka Streams功能(Kafka 正式升级成分布式流处理平台);
- 建议版本0.10.2.2;建议使用新版consumer API
- 0.11版本(2017 年 6 月)
- 提供幂等性 Producer API 以及事务(Transaction) API;
- 对 Kafka 消息格式做了重构。
- 建议版本0.11.0.3(目前最主流的版本之一)。
- 1.0 和 2.0 版本:主要还是 Kafka Streams 的各种改进,在消息引擎方面并未引入太多的重大功能特性。
- 如果你是 Kafka Streams 的用户,至少选择 2.0.0 版本吧。
- 如果你在意的依然是消息引擎,那么这两个大版本都是适合于生产环境的。
- 3.0版本
-
最后建议,不论你用的是哪个版本,都请尽量保持服务器端版本和客户端版本一致,否则你将损失很多 Kafka 为你提供的性能优化收益。
