

1.0 python基础知识总结: sudo dhclient
1.1导入模块:把功能相近的函数放在一个文件中, 一个.py文件就是一个模块model,模块名就是文件名去掉.py后缀, 提高代码复用性。
import 模块名: 模块名.函数 ,模块名.类
from 模块名 import 功能函数: 直接函数和类
from 模块名 import *
from 模块名 import 功能函数 as 别名 (是调用时候只能调别名才行)
导入包:
import 包名.模块名 (可以点多个包名下的子模块名)
**from 包名 import* (必须在`__init__.py`文件中添加`__all__ = []`,控制允许导入的模块列表。)**
__init__:导入包是默认执行这个文件
循环导入: A模块导入B模块中,B模导入A模块中
可以把 from***import 放到函数里面,或者最后也可以
第三方包:time datetime random os json
time模块: 时间戳
import time
print(sys.version)
# 函数运行时间
a = time.time()
print(a)
# sleep 延迟函数计算时间
# time.sleep(3)
# # 打印当前时间字符串
s = time.strftime('%Y-%m-%d')
print(s)
# 将时间戳转换为元组
d = time.localtime(a)
print(d)
# 将元组转换为时间戳
f = time.mktime(a)
print(f)
文件夹:非py文件 Diractory
包: py文件 Package
模块: 就是.py文件
项目 > 包 > 模块 >类 >函数 >变量
1.2测试用例: if __name__ == '__main__':
test()
可以让导入包时,不执行if下面的测试用例,只能在本模块下才能执行
1.3继承:
子类重写父类方法
子类多继承,先继承第一个父类的属性, 广度优先
类名.__mro__ 打印出继承关系
1.4 super 继承方法:
继承前一个的属性 super().__init__(参数)
先找当前类,再找父类,同名方法叫作 “重写” 默认找子类的方法
例子一:
class Person(object):
def __init__(self, name, sex):
self.name = name
self.sex = sex
class Student(Person):
def __init__(self, name, sex, hight):
super().__init__(name, sex)
self.hight = hight
def study(self, cource):
print('{}正在学习{}课程'.format(self.name, cource))
s = Student('jake', 'man', 18) #父类传参
s.study('python基础') #调用子类方法
例子二:
class Person(object):
def __init__(self, no, name, salary):
self.no = no
self.name = name
self.salary = salary
def __str__(self):
mas = '工号{}, 姓名{}, 本月工资{}'.format(self.no, self.name, self.salary)
def getSalry(self):
return self.salary
class Worker(Person):
def __init__(self, no, name, salary, hours):
super().__init__(no, name, salary)
self.hours = hours
def getSalry(self):
money = self.hours * 5
eturn money
chen = Worker(12, 'ch', 15, 16) # 全部参数都要传递
a = chen.getSalry() # 调用子类方法,没有参数就不用传递参数
print(a)
例子三:
class Test(object):
def __init__(self, age):
self.name = 'mmm'
self.age = age
def eat(self):
if self.age > 9:
print('可以吃饭')
else:
print('不能吃饭')
class Test_1(Test):
def __init__(self, age, sex): # 调用类所要传递的参数
super().__init__(age) # 继承的父类的变量,已经知道的变量不用继承
self.sex = sex
def eat_1(self):
if self.sex == 'man': # 如果是同一个类或不同类里面的已有属性,则不用传递参数 , 用已知参数
print('你是男的')
print(self.name)
else:
print('不是男的')
chen_1 = Test_1(18, 'man') # 早在调用类时就要给__init__传递参数,
chen_1.eat_1() # 调用方法的参数如果和类中的初始化参数不一样,就要自己传递
1.5 异常:
获取错误原因:
except Exception as error:
logging.error(error)
手动扔异常:
文件操作:
os模块:
# # 冒泡排序
# def test(num):
# for j in range(0, len(num) - 1):
# for i in range(0, len(num) - 1 - j):
# if num[i] > num[i+1]:
# num[i], num[i+1] = num[i+1], num[i]
# # a = num[i]
# # num[i] = num[i+1]
# # num[i+1] = a
#
# return num
#
# a = test([4,2,6,1,5])
# print(a)z
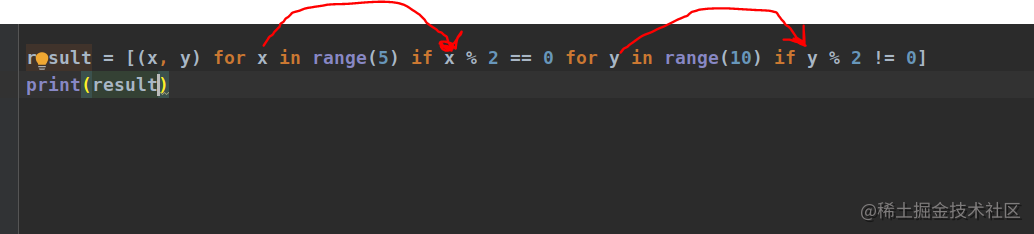
列表推导式:
for每遍历一遍就会把x值返回给if后面的值
生成器:可以节省内存,一个一个拿得到,常用在协程里面
(generator)
通过列表推导式的方式,只不过是圆括号,
函数加 yield 也可以将函数变成生成器
print一次生成一次元素值 next 生成一个新的元素
圆括号的生成器(x for x in range(5))
迭代器和可以迭代的:
迭代器:可以被next函数调用,并不断返回下一个值的对象成为迭代器,例如生成器
;列表是可以迭代的,但不是迭代器, 可以通过 iter() 转换为迭代器
list = 1
f = isinstance(list, Iterable)
print(f) # 返回是True为可以迭代的, 整形是不能迭代的对象
2.0 正则表达式: 对字符串对特定字符, 组成一个字符串形成特定逻辑, 用来过滤
re模块: re.match( )
3.0 进程 > 线程 > 协程
进程之间是独立的,进程是系统进行分配的,为了更快的完成任务。 cpu会开销一个空间
非阻塞式:全部添加到队列中,立即返回,并没有等待,最大化cpu的效率 pool.apply_async()
阻塞式: 添加一个任务执行一个任务 pool.apply()
from multiprocessing import Process
def task1():
while True:
# sleep(1)
print('这是任务一')
def task2():
while True:
# sleep(1)
print('这是任务而2')
if __name__ == '__main__':
p = Process(target=task1, name='任务一')
p.start()
p1 = Process(target=task2, name='任务二')
p1.start()
进程间的通信: put方法 get获得
from multiprocessing import Pool, Process
def task1(q):
images = ['a', 'b', 'c']
for i in images:
print('正在下载:', i)
sleep(1)
q.put(i)
def task2(q):
while True:
file = q.get()
print('{}保存成功'.format(file))
if __name__=='__main__':
q = Queue(5)
p1 = Process(target=task1, args=(q,))
p2 = Process(target=task2, args=(q,))
p1.start()
p2.start()
线程:互不干扰,并发执行, 进程开销大,线程开销小,依赖进程,耗时操作的比较大的任务使用线程,
状态: 新建状态,对象创建完成后,就绪状态,运行状态,阻塞状态,
